首页 > 基础资料 博客日记
Elasticsearch底层的倒排索引技术是什么?
2024-10-16 18:30:03基础资料围观590次
倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
技术应用在Elasticsearch,得益于倒排索引,用来实现高性能的搜索功能
正向索引
例如有一张名为tb_goods的表:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like '%手机%';
那搜索的大概流程如图:
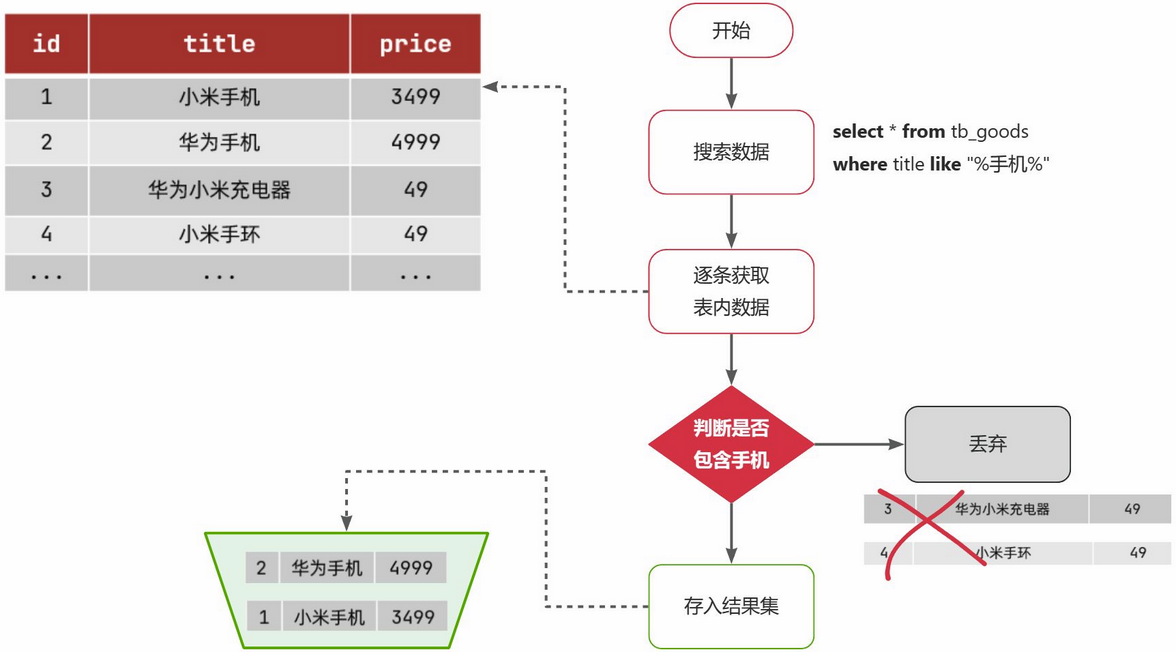
说明:
- 1)检查到搜索条件为
like '%手机%',需要找到title中包含手机的数据 - 2)逐条遍历每行数据(每个叶子节点),比如第1次拿到
id为1的数据 - 3)判断数据中的
title字段值是否符合条件 - 4)如果符合则放入结果集,不符合则丢弃
- 5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
倒排索引
倒排索引中有两个概念
- 文档(
Document):每一条数据就是一个文档。
例如一个网页、一个商品信息
- 词条(
Term):文档按照语义分成的词语
例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
倒排索引创建流程
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下
- 先把文档进行分词,形成词条与文档的ID对应关系,为词条建立索引,而且具备唯一性
- 对搜索内容进行分词,把分词后的关键字列表,更具关键字去词条中匹配,再找到对应的文档ID
- 让后根据文档ID列表,找到对应的文档信息
此时形成的这张以词条为索引的表,就是倒排索引表,两者对比如下:
正向索引
| id(索引) | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
倒排索引
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
倒排索引的搜索流程
倒排索引的搜索流程如下(以搜索"华为手机"为例)
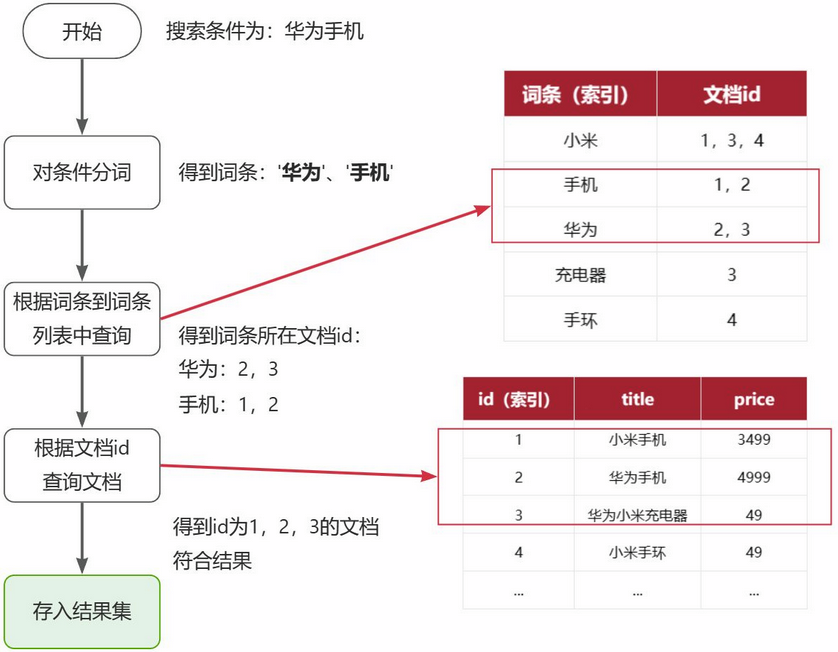
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向和倒排优缺点
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
