首页 > 基础资料 博客日记
Java 并发集合:CopyOnWrite 写时复制集合介绍
2024-07-06 12:00:06基础资料围观930次
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 016 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自己的技术栈的同学。与此同时,本专栏的所有文章,也都会准备充足的代码示例和完善的知识点梳理,因此也十分适合零基础的小白和要准备工作面试的同学学习。当然,我也会在必要的时候进行相关技术深度的技术解读,相信即使是拥有多年 Java 开发经验的从业者和大佬们也会有所收获并找到乐趣。
–
Java 集合框架(Java Collections Framework)为开发者提供了一套强大且灵活的数据结构和算法工具,使得数据管理和操作变得更加高效和简洁。在多线程环境中,如何在保证线程安全的同时,保持集合操作的高效性,成为了一个至关重要的课题。为此,Java 提供了一系列并发集合类,其中
CopyOnWrite系列集合因其独特的“写时复制”机制,成为了解决并发读写问题的一种有效方案。
CopyOnWrite集合类主要包括CopyOnWriteArrayList和CopyOnWriteArraySet。它们通过在每次修改集合时创建一个新副本,从而保证了读操作的无锁化,这种设计极大地提高了读操作的性能,同时也简化了开发者的使用难度。然而,写时复制的特性也带来了一定的内存开销和写操作的性能代价。因此,了解其工作原理和适用场景,对于我们在实际开发中选择合适的集合类至关重要。在本文中,我们将深入探讨
CopyOnWrite集合的实现原理、优缺点以及适用场景,帮助读者全面理解和正确使用这些集合类。无论是编写高性能的多线程应用程序,还是解决复杂的并发数据访问问题,掌握CopyOnWrite集合的使用技巧,都将为您的开发工作带来极大的助益。
文章目录
1、写时复制的介绍
写时复制(Copy-on-Write,简称COW)是一种计算机程序设计领域的优化策略。
其核心思想是:如果有多个调用者同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这一过程对其他的调用者都是透明的。
- 当对容器进行写操作(这里的写可以理解为 “增、删、改”)时,为了避免读写操作同时进行而导致的线程安全问题
我们将原始容器中的数据复制一份放入新创建的容器,然后对新创建的容器进行写操作; - 而读操作继续在原始容器上进行,这样读写操作之间便不会存在数据访问冲突,也就不存在线程安全问题
当写操作执行完成之后,新创建的容器替代原始容器,原始容器便废弃。
写时复制的主要优点是,如果调用者没有修改该资源,就不会有副本被创建,因此多个调用者只是进行读取操作时可以共享同一份资源。这种策略不仅优化了内存使用,还保护了数据,因为在写操作之前,原始数据不会被覆盖或修改,从而避免了数据丢失的风险。
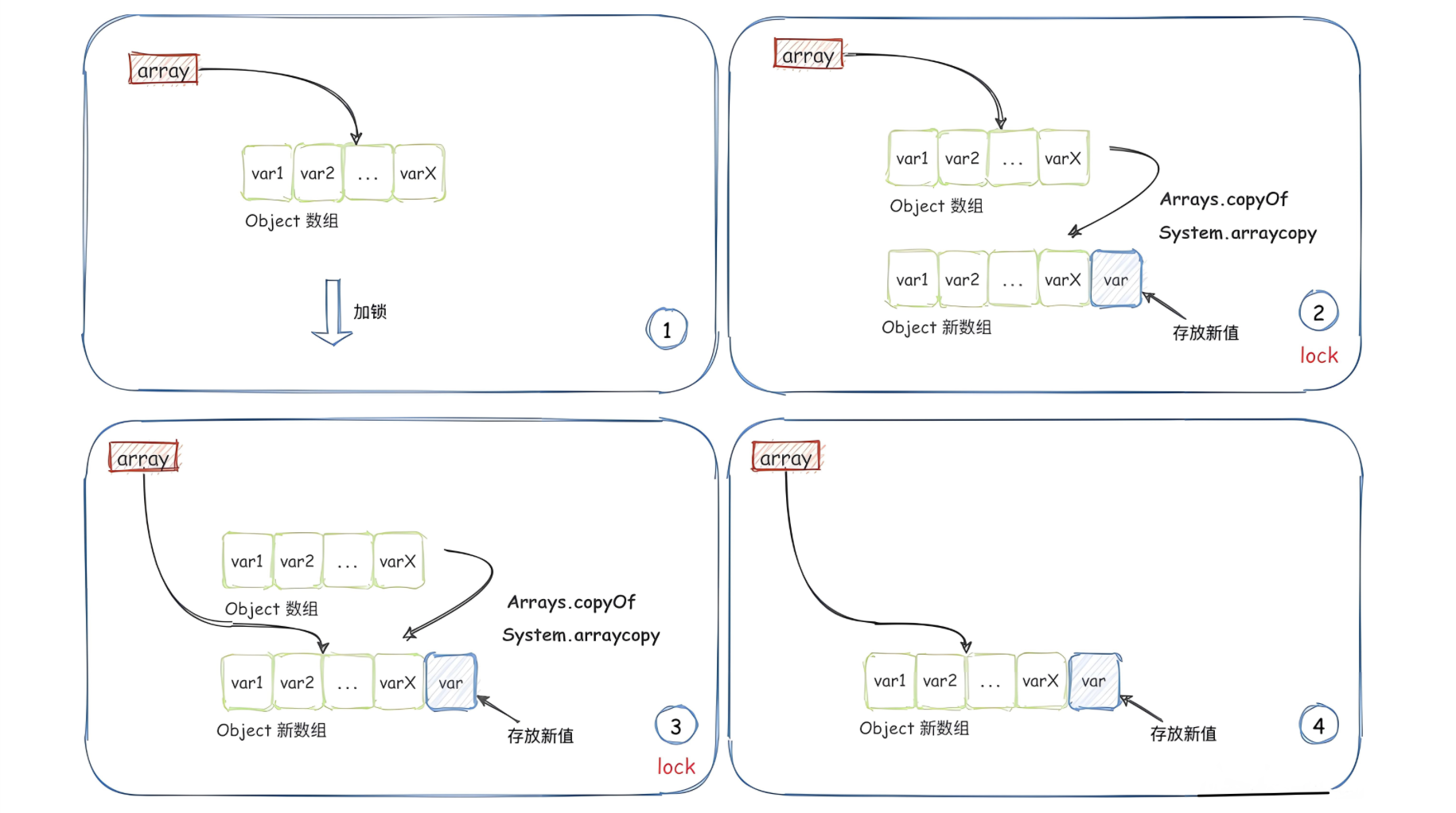
在 Java 中,CopyOnWriteArrayList 和 CopyOnWriteArraySet 就是使用了这种策略的两个类。这两个类都位于java.util.concurrent 包下,是线程安全的集合类。当需要修改集合中的元素时,它们不会直接在原集合上进行修改,而是复制一份新的集合,然后在新的集合上进行修改。修改完成后,再将指向原集合的引用指向新的集合。这种设计使得读操作可以在不加锁的情况下进行,从而提高了并发性能。
总的来说,写时复制是一种适用于读多写少场景的优化策略,它通过复制数据的方式实现了读写分离,提高了并发性能。但是,它也存在一些潜在的性能问题,如内存占用增加、写操作性能下降以及频繁的垃圾回收。因此,在使用时需要根据具体场景进行权衡和选择。
2、写时复制的实现
2.1、CopyOnWriteArrayList 数据结构
CopyOnWriteArrayList 是 Java 中的一种线程安全的 List 实现,它通过每次写操作时复制底层数组来保证线程安全。CopyOnWriteArrayList 跟 ArrayList 一样,也实现了 List 接口:
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable {
// ReentrantLock用于保证在多线程环境下的线程安全
final transient ReentrantLock lock = new ReentrantLock();
// 持有实际元素的数组,通过volatile修饰保证在多线程环境下的可见性
private transient volatile Object[] array;
// 默认构造函数,初始化一个空数组
public CopyOnWriteArrayList() {
this.array = new Object[0];
}
// 省略其他方法和实现细节...
}
可以看到,CopyOnWriteArrayList 底层的数据结构是一个数组(Object[] array)。这个数组通过 volatile 修饰,保证在多线程环境下的可见性。当数组内容发生变化时,其他线程能够立即看到最新的数组内容。
2.2、CopyOnWriteArrayList 读操作
读操作不需要加锁,因为写操作总是会生成新的数组副本,并且数组引用是 volatile 的,所以读操作总能读取到最新的数组内容。这使得读操作非常高效,适用于读多写少的场景。
public E get(int index) {
return (E) this.array[index];
}
get() 函数实现了 CopyOnWriteArrayList 的读操作,代码逻辑非常简单,直接按照下标访问 array 数组从代码中我们可以发现,读操作没有加锁,因此即便在多线程环境下,效率也非常高
2.2、CopyOnWriteArrayList 写时复制
当对 CopyOnWriteArrayList 进行写操作(如 add, set, remove)时,都会创建底层数组的新副本。在新的副本上进行修改操作,修改完成后再将引用指向新的数组。这种写时复制的机制保证了在进行写操作时不会影响到正在进行读操作的线程。
2.2.1、add() 函数
add() 函数的代码实现如下所示,add() 函数包含写时复制逻辑,因此相对于 get() 函数,要复杂一些
public boolean add(E e) {
// 获取锁,确保在多线程环境下只有一个线程能进行写操作
lock.lock();
try {
// 获取当前数组的长度
int len = array.length;
// 使用 Arrays.copyOf() 方法创建一个新数组,并将现有数组的元素复制到新数组中
// Arrays.copyOf() 方法底层依赖 native 方法 System.arraycopy() 来实现复制操作,速度较快
Object[] newElements = Arrays.copyOf(array, len + 1);
// 将新元素添加到新数组的最后一个位置
newElements[len] = e;
// 将底层数组引用指向新数组
array = newElements;
// 返回 true 表示添加成功
return true;
} finally {
// 释放锁
lock.unlock();
}
}
当往容器中添加数据时,并非直接将数据添加到原始数组中,而是创建一个长度比原始数组大一的数组 newElements,将原始数组中的数据拷贝到 newElements。然后将数据添加到 newElements 的末尾,最后修改 array 引用指向 newElements。
除此之外,我们可以看到,为了保证写操作的线程安全性,避免两个线程同时执行写时复制,写操作通过加锁(lock.lock();)来串行执行也就是说:读读、读写都可以并行执行,唯独写写不可以并行执行.
2.2.2、remove() 函数
remove() 函数的代码实现如下所示:
public E remove(int index) {
// 获取锁,确保在多线程环境下只有一个线程能进行写操作
lock.lock();
try {
// 获取当前数组的长度
int len = array.length;
// 获取指定索引处的元素,该元素将在稍后被移除
E oldValue = get(array, index);
// 计算从指定索引到数组末尾之间的元素个数
int numMoved = len - index - 1;
if (numMoved == 0) {
// 如果要移除的元素是数组的最后一个元素,直接创建一个长度为 len - 1 的新数组
array = Arrays.copyOf(array, len - 1);
} else {
// 如果要移除的元素在数组的中间位置
Object[] newElements = new Object[len - 1];
// 将原数组中从索引 0 到 index-1 的元素复制到新数组中
System.arraycopy(array, 0, newElements, 0, index); // array[0, index - 1]
// 将原数组中从索引 index+1 到末尾的元素复制到新数组中,从 index 位置开始
System.arraycopy(array, index + 1, newElements, index, numMoved);
// 更新底层数组引用为新数组
array = newElements;
}
// 返回被移除的元素
return oldValue;
} finally {
// 释放锁
lock.unlock();
}
}
remove() 函数的处理逻辑跟 add() 函数类似:先通过加锁保证写时复制操作的线程安全性,然后申请一个大小比原始数组大小小一的新数组 newElements。除了待删除数据之外,我们将原始数组中的其他数据统统拷贝到 newElements,拷贝完成之后,我们将 array 引用指向 newElements。
2.2.3、set() 函数
set() 函数的代码实现如下所示
public E set(int index, E element) {
// 获取锁,确保在多线程环境下只有一个线程能进行写操作
lock.lock();
try {
// 获取指定索引处的旧值
E oldValue = get(array, index);
// 如果旧值与新值不同,才进行更新操作
if (oldValue != element) {
// 获取当前数组的长度
int len = array.length;
// 使用 Arrays.copyOf() 方法创建一个新数组,并将现有数组的元素复制到新数组中
// Arrays.copyOf() 方法底层依赖 native 方法 System.arraycopy() 来实现复制操作,速度较快
Object[] newElements = Arrays.copyOf(array, len);
// 将新元素放置到指定索引处
newElements[index] = element;
// 更新底层数组引用为新数组
array = newElements;
}
// 返回旧值
return oldValue;
} finally {
// 释放锁
lock.unlock();
}
}
在 set() 函数中,跟 add() 函数、remove() 函数的类似,通过加锁确保线程安全,在旧值与新值不同时复制底层数组并替换指定索引处的元素,最后更新数组引用并释放锁。
2.3、CopyOnWriteArraySet 的实现
CopyOnWriteArraySet 使用 CopyOnWriteArrayList 作为底层数据结构,通过写时复制的方式保证线程安全。
public class CopyOnWriteArraySet<E> extends AbstractSet<E> {
// 底层数据结构使用 CopyOnWriteArrayList 来存储元素
private final CopyOnWriteArrayList<E> al;
// 默认构造函数,初始化底层的 CopyOnWriteArrayList
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
// 添加元素到集合中,如果元素不存在则添加并返回 true,否则返回 false
public boolean add(E e) {
return al.addIfAbsent(e);
}
// 从集合中移除指定元素,如果移除成功则返回 true,否则返回 false
public boolean remove(Object o) {
return al.remove(o);
}
// 判断集合中是否包含指定元素,如果包含则返回 true,否则返回 false
public boolean contains(Object o) {
return al.contains(o);
}
// 省略其他方法和实现细节...
}
添加元素时,只有在元素不存在时才会添加;移除和检查元素的方法直接委托给底层的 CopyOnWriteArrayList 实现。整个实现确保了高并发环境下的安全性和一致性。
3、写实复制的特性
3.1、读多写少
从上述 CopyOnWriteArrayList 的源码和性能测试结果可以得出以下结论:
-
写操作需要加锁:所有的写操作(如
add、set、remove等)都需要获取锁,确保线程安全性,因此这些操作只能串行执行; -
写时复制:每次写操作都需要创建数组副本并进行数据拷贝,这涉及大量的数据搬移,导致写操作的执行效率非常低;
-
读多写少的场景:由于写操作的高开销,
CopyOnWriteArrayList适用于读多写少的应用场景。在这种场景下,读操作可以并发执行,且无需加锁。
以下是一个性能测试的示例代码,用于比较 CopyOnWriteArrayList 和 ArrayList 在执行大量写操作时的耗时:
public class Demo {
public static void main(String[] args) {
List<Integer> cowList = new CopyOnWriteArrayList<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
cowList.add(i);
}
System.out.println("CopyOnWriteArrayList耗时: " + (System.currentTimeMillis() - startTime) + " 毫秒");
List<Integer> list = new ArrayList<>();
startTime = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
list.add(i);
}
System.out.println("ArrayList耗时: " + (System.currentTimeMillis() - startTime) + " 毫秒");
}
}
这里我执行的结果是:CopyOnWriteArrayList 执行 100000 次写操作耗时约 2098 毫秒。ArrayList 执行同样数量的写操作仅耗时约 2 毫秒。CopyOnWriteArrayList 的耗时是 ArrayList 的 1000 多倍,说明在写操作频繁的场景下,CopyOnWriteArrayList 的性能表现非常差。
3.2、弱一致性
CopyOnWriteArrayList 由于写时复制的特性,写操作的结果并不会立即对读操作可见。写操作在新数组上执行,而读操作在原始数组上执行,这就导致在 array 引用指向新数组之前,读操作只能读取到旧的数据。这种现象被称为弱一致性。
在示例代码中,存在两个线程:一个线程调用 add() 函数添加数据,另一个线程调用 sum() 函数遍历容器求和。
public class Demo {
private List<Integer> scores = new CopyOnWriteArrayList<>();
public void add(int idx, int score) {
scores.add(idx, score); // 将数据插入到 idx 下标位置
}
public int sum() {
int ret = 0;
for (int i = 0; i < scores.size(); i++) {
ret += scores.get(i);
}
return ret;
}
}
重复统计问题的产生:假设一个线程在执行 add(int idx, int score) 方法向 scores 列表中添加数据的同时,另一个线程在执行 sum() 方法遍历 scores 列表求和。这种情况下,可能会发生以下情况:
-
线程 A 执行
add()方法:线程 A 调用scores.add(idx, score)方法,底层会创建一个新的数组并将原数组的内容复制到新数组,然后将新元素添加到新数组中; -
线程 B 执行
sum()方法:在scores列表的array引用更新之前,线程 B 开始遍历原数组;
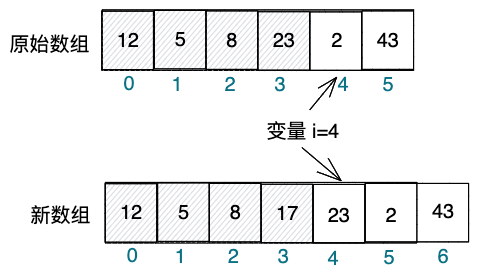
- 写时复制导致的数据不一致:由于写时复制的特性,线程 A 操作的是新数组,而线程 B 读取的是旧数组。此时,如果线程 A 更新了
array引用,指向了新数组,而线程 B 仍然在遍历旧数组,可能会产生数据不一致的问题。
假设 scores 列表中有 n 个元素,线程 A 在第 i 个位置添加新元素,而线程 B 正在遍历第 i 个元素。如果 array 引用在此时更新,指向了新数组,线程 B 会继续遍历旧数组并重复统计第 i 个元素。这就导致了 sum() 方法可能会多统计一次该元素的值,产生错误的求和结果。
迭代器实现与弱一致性问题的解决:CopyOnWriteArrayList 提供了一个专门的迭代器,用于遍历容器。这个迭代器在创建时,将原始数组赋值给 snapshot 引用,之后的遍历操作都是在 snapshot 上进行的。这样,即使 array 引用指向新的数组,也不会影响到 snapshot 引用继续指向原始数组,从而解决了弱一致性带来的问题。
以下是 CopyOnWriteArrayList 中迭代器的实现代码:
// 位于 CopyOnWriteArrayList.java 中
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
static final class COWIterator<E> implements ListIterator<E> {
private final Object[] snapshot; // 指向原始数组
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
@SuppressWarnings("unchecked")
public E next() {
if (!hasNext()) throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
// ... 省略其他方法 ...
}
使用迭代器来重构 sum() 方法,使其在遍历过程中避免重复统计的问题。重构后的代码如下:
public int sum() {
int ret = 0;
Iterator<Integer> itr = scores.iterator();
while (itr.hasNext()) {
ret += itr.next();
}
return ret;
}
重构后的优点:
-
避免数据不一致:由于迭代器在创建时将原始数组赋值给
snapshot,遍历操作都是在snapshot上进行,即使array引用指向新的数组,遍历过程中的数据也不会改变,从而避免了重复统计的问题; -
线程安全:迭代器提供了一种线程安全的遍历方式,确保在高并发环境下能够正确读取数据;
-
简洁代码:使用迭代器使得遍历代码更加简洁和易读,同时保证了代码的正确性和性能。
3.3、连续存储
在本篇开头,我们提到了 JUC 提供了 CopyOnWriteArrayList、CopyOnWriteArraySet 却没有提供 CopyOnWriteLinkedList、CopyOnWriteHashMap 等其他类型的写时复制容器,这是出于什么样的考虑呢?
3.3.1、数组容器
在写时复制的处理逻辑中,每次执行写操作时,哪怕只添加、修改、删除一个数据,都需要大动干戈,把原始数据重新拷贝一份。如果原始数据比较大,那么对于链表、哈希表来说,因为数据在内存中不是连续存储的,因此拷贝的耗时将非常大,写操作的性能将无法满足一个工业级通用类对性能的要求。
而 CopyOnWriteArrayList 和 CopyOnWriteArraySet 底层都是基于数组来实现的,数组在内存中是连续存储的
JUC 使用 JVM 提供的 native 方法,如下所示,通过 C++ 代码中的指针实现了内存块的快速拷贝,因此写操作的性能在可接受范围之内。
而在平时的业务开发中,对于一些读多写少的业务场景,在确保性能满足业务要求的前提下,我们仍然可以使用写时复制技术来提高读操作性能。
// 位于 System.java 中
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
3.3.3、非数组容器
JUC 没有提供非数组类型的写时复制容器,是出于对于一个工业级通用类的性能的考量对于非数组类型的容器,我们需要自己去开发相应的写时复制逻辑,
假设系统配置存储在文件中,在系统启动时,配置文件被解析加载到内存中的 HashMap 容器中,之后 HashMap 容器中的配置会频繁地被用到系统支持配置热更新,在不重启系统的情况下,我们希望能较实时地更新内存中的配置,让其跟文件中的配置保持一致
为了实现热更新这个功能,我们在系统中创建一个单独的线程,定时从配置文件中加载解析配置,更新到内存中的 HashMap 容器中
对于这样一个读多写少的应用场景,我们就可以使用写时复制技术,如下代码所示在更新内存中的配置时,使用写时复制技术,避免写操作和读操作互相影响。相对于 ConcurrentHashMap 来说,读操作完全不需要加锁,甚至连 CAS 操作都不需要,因此读操作的性能更高。
public class Configuration {
private static final Map<String, String> map = new HashMap<>();
// 热更新, 这里不需要加锁(只有一个线程调用此函数), 也不需要拷贝(全量更新配置)
public void reload() {
Map<String, String> newMap = new HashMap<>();
// ... 从配置文件加载配置, 并解析放入 newMap
map = newMap;
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
