首页 > 基础资料 博客日记
【GIS系列】挑战千万级数据:Java和Elasticsearch在GIS中的叠加分析实践
2024-06-22 12:00:06基础资料围观719次
作者:后端小肥肠
创作不易,未经允许严禁转载。
目录
3.4.1. 将面要素wkt转换为GeoPoint类型的数组
1. 前言
在处理千万级图斑叠加分析时,传统的后端GIS工具,如Geotools和PostGIS,往往难以满足实时性和高效性的要求。在这一挑战背景下,引入Elasticsearch作为空间叠加查询的解决方案,成为了一种创新且高效的选择。本文将探讨如何利用Java和Elasticsearch实现GIS中的千万级图斑叠加分析,以项目场景为基础,通过对传统后端GIS工具与Elasticsearch的性能比较,旨在为读者展示Elasticsearch作为一种新兴的空间数据处理工具的价值和潜力,为解决类似问题的开发者提供新的思路和解决方案。
本文适合有Elasticsearch和GIS后台编程基础的jym,如本文对你有帮助和启示,请三连支持一下小肥肠~
2. 叠加分析场景方案对比
假设叠加分析的场景为求一个面要素下包含的点要素,点要素图层有1000万个点,要求在短时间内返回叠加分析结果。以后端为JAVA的背景下,常用的叠加分析方案有Geotools,Postgis,ES,目前将从技术方案特点,性能,优缺点,以及处理千万级图斑的可行性这几个方面依次介绍这几种技术方案。
2.1. Geotools
- 技术方案特点: Geotools是一个开源的Java GIS工具库,提供了丰富的地理信息处理功能。
- 性能评估: 在处理大规模空间数据时,Geotools可能性能较差,因其设计更偏向于灵活性和功能的全面性,而不是针对大规模数据的优化。
- 优缺点: Geotools拥有丰富的功能和灵活的定制性,但在处理千万级图斑等大规模数据时,可能表现不佳。
- 处理千万级图斑的可行性:在处理大规模数据时可能性能较差,可能需要额外的优化和资源才能满足实时性和高效性的要求。
2.2. PostGIS
- 技术方案特点: PostGIS是一个基于PostgreSQL的空间数据库扩展,提供了丰富的空间分析功能。
- 性能评估: PostGIS在处理大规模空间数据时性能较好,可以通过索引和优化查询来提高处理效率。
- 优缺点: PostGIS具有成熟的空间数据处理功能和优秀的性能,但在某些情况下可能需要额外的硬件资源来支持高负载。
- 处理千万级图斑的可行性:PostGIS在处理大规模数据时性能较好,通过适当的索引和优化查询可以有效提高处理效率,但要在短时间内完千万级图斑成叠加分析可能存在一些限制,特别是在复杂的叠加条件或者硬件资源受限的情况下。
2.3. Elasticsearch
-
技术方案特点:
- 分布式实时搜索与分析引擎: Elasticsearch是一个基于分布式架构的实时搜索和分析引擎,专注于快速、实时的数据处理和查询。
- 地理空间支持: Elasticsearch通过地理空间索引和查询功能,能够有效地处理地理空间数据,包括点、线、面等要素。
- 高度可扩展性: Elasticsearch具有良好的横向扩展能力,能够轻松地处理大规模数据,因此适合处理千万级图斑等大规模空间数据。
-
性能评估:
- 实时性和高效性: Elasticsearch在处理大规模数据时表现出色,具有较快的响应速度和高效的查询性能,能够满足实时性和高效性的要求。
- 水平扩展性: 通过横向扩展集群节点,Elasticsearch能够有效地处理大规模数据,保持良好的性能表现。
-
优缺点:
- 优点:
- 实时性高:Elasticsearch支持实时索引和查询,能够快速处理最新的空间数据。
- 强大的查询功能:Elasticsearch提供丰富的查询语法和功能,能够灵活地满足各种空间分析需求。
- 可扩展性强:Elasticsearch具有良好的横向扩展能力,能够轻松地处理大规模数据。
- 缺点:
- 学习曲线较陡:对于新手来说,可能需要一定时间来学习Elasticsearch的数据模型和查询语法。
- 硬件资源需求较高:在处理大规模数据时,可能需要较多的硬件资源来支持高负载的查询请求。
- 优点:
-
处理千万级图斑的可行性:
- 可行性: Elasticsearch在处理大规模数据时表现优异,尤其擅长于实时性和高效性要求较高的场景,因此对于处理千万级图斑是可行的选择。通过合适的索引设计和优化查询,Elasticsearch能够有效地处理千万级图斑数据,并提供快速准确的查询结果。
3. 基于ElastcSearch实现叠加分析代码实践
3.1. 开发环境搭建
3.1.1. 所需版本和工具
| 依赖 | 版本 |
|---|---|
| Spring Boot | 2.6.3 |
| Java | 1.8以上 |
| Elasticsearch | 7.9.3 |
3.1.2. pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.locationtech.jts</groupId>
<artifactId>jts-core</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>3.2. 数据导入
基于工具将点要素图层导入Elasticsearch,这里怎么导入的不细讲,相关资料可自行百度:
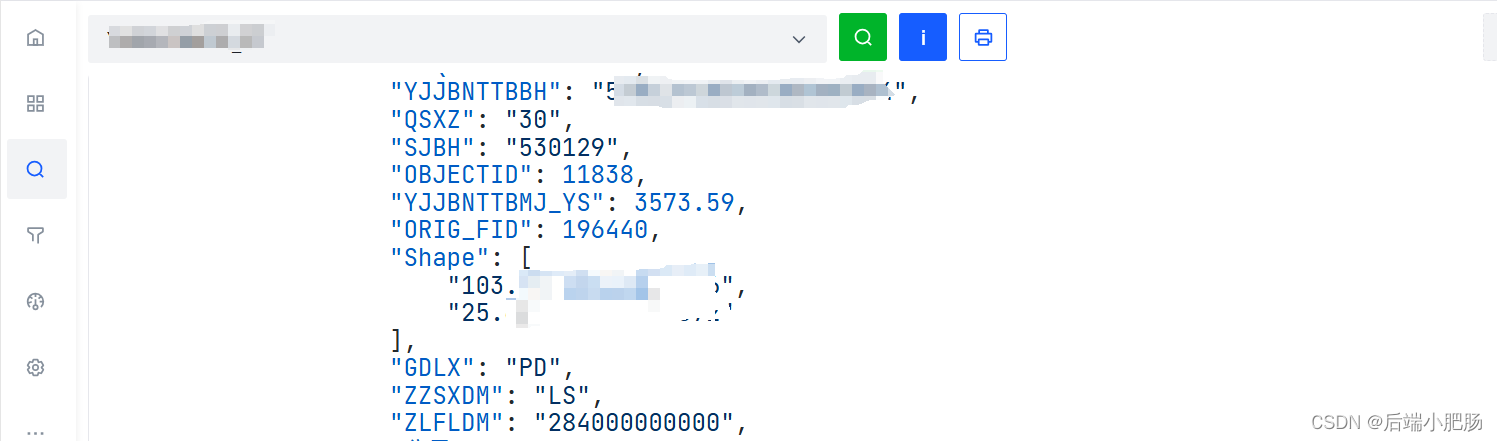
注意看Shape字段类型要如上图才能支持面包含点类型的叠加分析。
3.3. 返回结构设计
{
"code": 200,
"status": "success",
"message": "OK",
"data": {
"list": [
{
"name": "地类名称",
"code": "地类编码",
"count": 178,
"hectares": 541213,
"ares": 3243,
"squareMetres": 32432
}
]
}
}由返回结构可看出,我们需要返回点要素的name,code和面积属性(平方米,公亩,公顷)。
3.4. 核心代码讲解
3.4.1. 将面要素wkt转换为GeoPoint类型的数组
private List<GeoPoint> parseWKTGeometry(String wkt) {
List<GeoPoint> points = new ArrayList<>();
GeometryFactory geometryFactory = new GeometryFactory();
WKTReader reader = new WKTReader(geometryFactory);
try {
Geometry geometry = reader.read(wkt);
if (geometry instanceof Polygon) {
Polygon polygon = (Polygon) geometry;
LinearRing ring = (LinearRing) polygon.getExteriorRing();
Coordinate[] coordinates = ring.getCoordinates();
for (Coordinate coord : coordinates) {
double lat = coord.y;
double lon = coord.x;
points.add(new GeoPoint(lat, lon));
}
}
} catch (ParseException e) {
e.printStackTrace();
}
return points;
}3.4.2. 编写叠加分析方法函数
public ResponseStructure overlayAnalysis(OverlayDTO overlayDTO) {
try {
if(StringUtils.isEmpty(overlayDTO.getGeometry())){
return ResponseStructure.failed("空间范围不可为空");
}
String geometry=overlayDTO.getGeometry();
// 1. 指定检索 Index
SearchRequest request = new SearchRequest();
request.indices(ALIAS);
// 2. 指定检索方式
SearchSourceBuilder builder = new SearchSourceBuilder();
// 3. 解析 WKT 格式的多边形
List<GeoPoint> points = parseWKTGeometry(geometry);
// geoPolygonQuery 代表着的是多边形查询
builder.query(QueryBuilders.geoPolygonQuery("Shape", points)).trackTotalHits(true).size(0);
// 4. 添加聚合查询
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("code").field(FIELD_CODE)
.subAggregation(AggregationBuilders.sum("MJ").field("YJJBNTMJ")).size(500);
builder.aggregation(termsAggregationBuilder);
request.source(builder);
// 5. 执行查询
SearchResponse resp = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 6.1 输出总数
long total = resp.getHits().getTotalHits().value;
// 6.2 聚合结果
List<DataVo> lists = new ArrayList<>();
Terms terms = resp.getAggregations().get("code");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
// 获取分组总面积
Sum mj = bucket.getAggregations().get("MJ");
Double sum = mj.getValue();
log.info("面积:{}", sum);
// 获取代码
String code = bucket.getKeyAsString();
log.info("代码:{}", code);
QuickStatistics quickStatistics = quickStatisticsMapper.selectOne(new LambdaQueryWrapper<QuickStatistics>()
.eq(QuickStatistics::getCode, code).eq(QuickStatistics::getType, FIELD_CODE));
// 如果大数据库查到的代码没有在 pg 库的数据字典中,忽略不统计
if (quickStatistics == null) {
log.info("未统计的代码:{}", code);
continue;
}
String name = quickStatistics.getName();
lists.add(new DataVo(name, code, bucket.getDocCount(), sum, sum / 100, sum / 10000));
}
JBNTVO jbntvo = new JBNTVO(lists);
return ResponseStructure.success(jbntvo);
} catch (Exception e) {
log.error(e.getMessage(), e);
return ResponseStructure.failed("叠加分析异常");
}
}上述方法使用Elasticsearch进行查询,根据指定的几何图形执行地理多边形查询,并添加聚合查询以计算特定区域内的指标数据。最后,它将查询结果进行处理,包括统计各个区域的指标数据和计算相关指标,然后封装成特定的VO对象返回。如果在执行过程中出现异常,则记录错误信息并返回相应的错误响应。
3.5. 结果测试
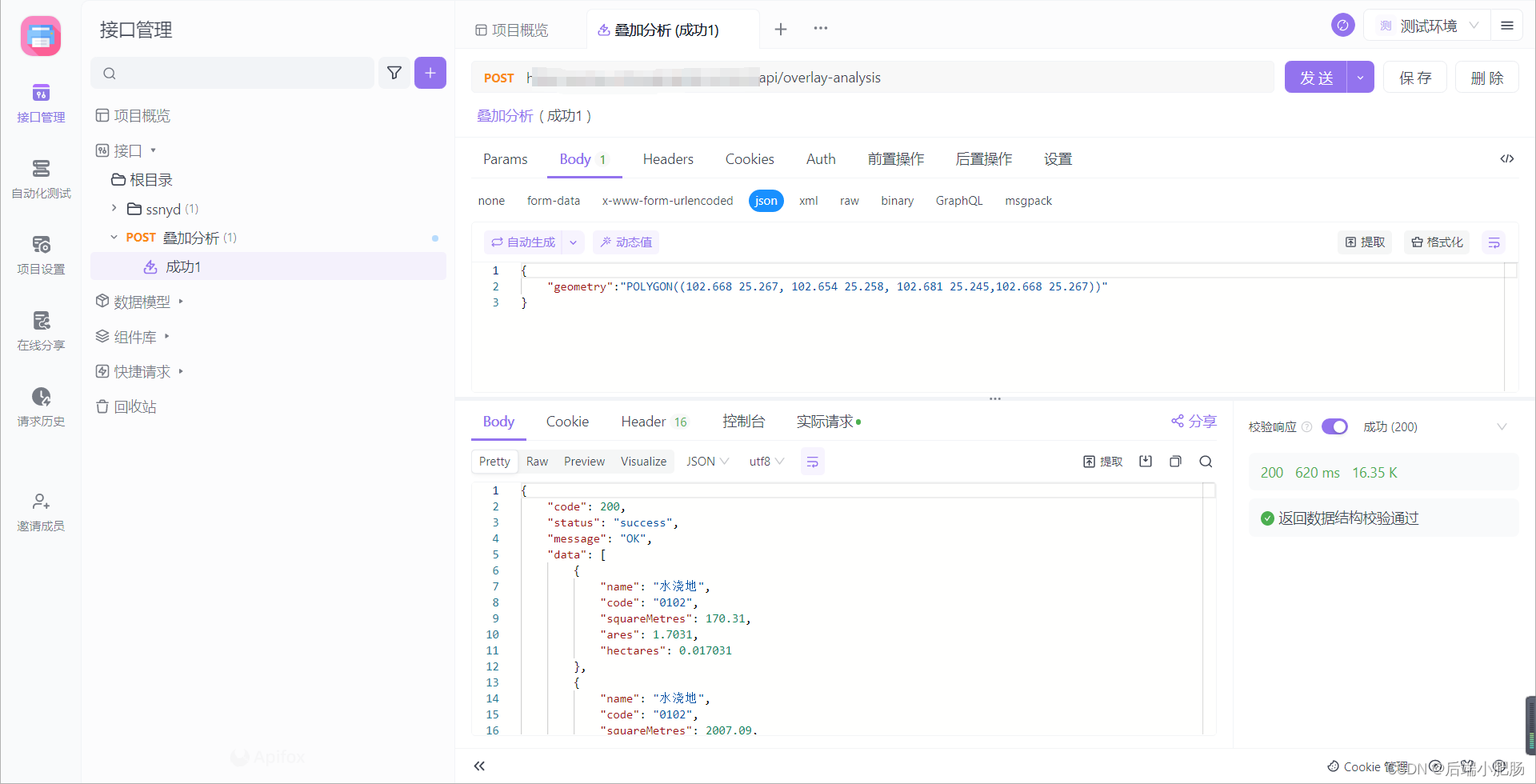
由上图可知,只需要输入叠加面要素的wkt格式数据,便可在短时间内拿到叠加分析结果。
4. 结语
本文以千万级图斑叠加分析为背景,首先对比了常规技术栈和ES的优缺点,最后以实际代码讲解了如何基于ES实现千万级图斑叠加分析,如有更好的想法欢迎在评论区留言进行讨论~

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
