首页 > 基础资料 博客日记
小小redis持久化,拿捏
2024-05-12 14:00:04基础资料围观514次
前言
我们先来说说什么是持久化
-
持久化顾名思义就是数据长久保存,Redis为什么需要持久化呢,好呆的问题,Redis数据是存储在内存中的,内存数据的特点就是一旦重启就什么都没了
-
我们将文件由内存中保存到硬盘中的这个过程,我们叫做数据保存,也就叫做持久化。但是把它保存下来不是你的目的,最终你还要把它再读取出来,它加载到内存中这个过程,我们叫做数据恢复。
一、redis的两种持久化方式
-
快照——RDB
-
日志——AOF

1.RDB
将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单,关注点在数据。
2.AOF
将数据的操作过程进行保存,日志形式,存储操作过程,存储格式复杂,关注点在数据的操作过程。
二、 RDB
1. RDB的存储方式
理解RDB的存储方式,这种方式叫快照,就相当于给当前数据立刻拍一张照片存起来,在电脑中以二进制的形式存储,数据恢复的时候直接拿出照片,一个copy瞬间恢复
2. save指令
-
save指令:手动进行一次保存操作
-
sava指令工作原理:
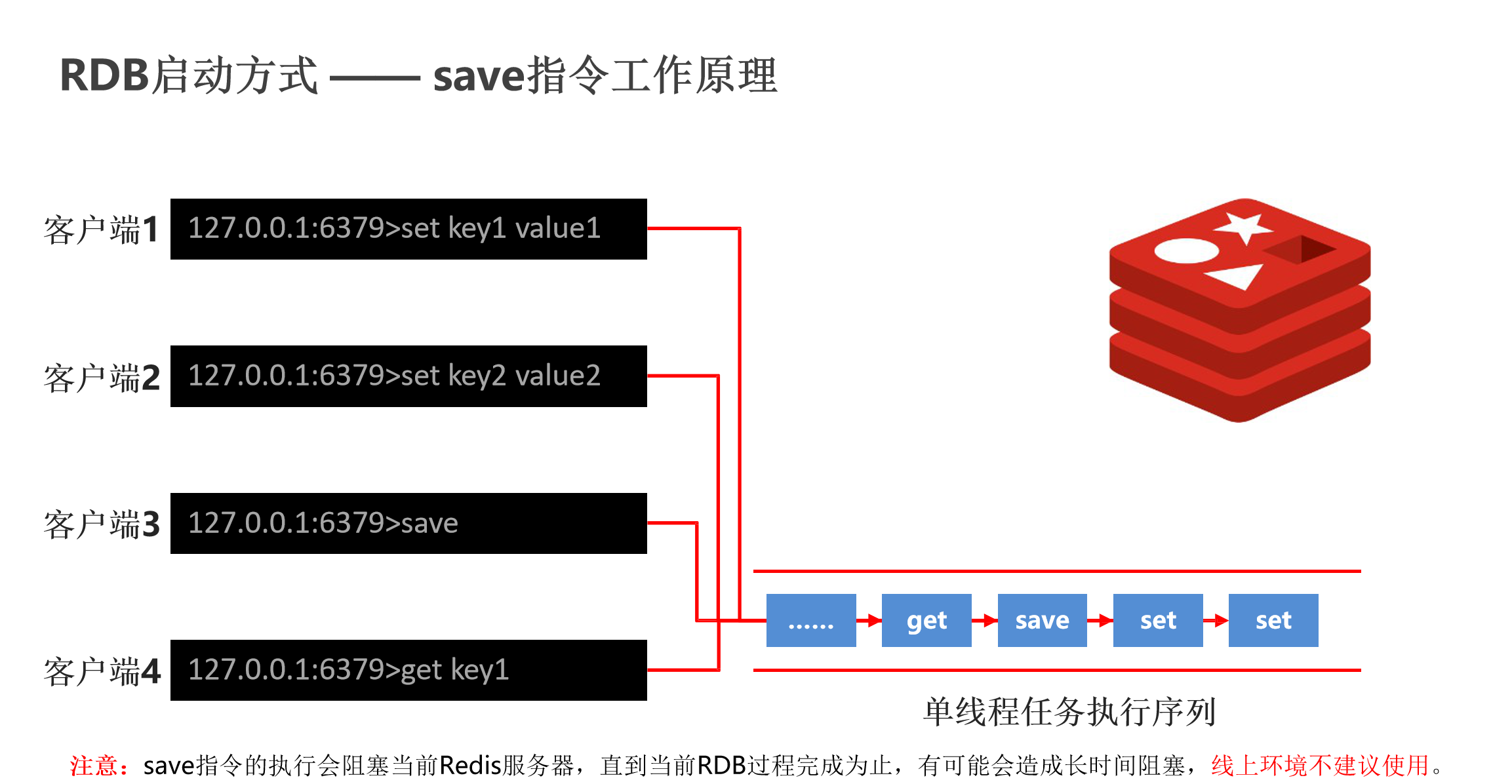
记得redis是个单线程的工作模式,它会创建一个任务队列,所有的命令都会进到这个队列里边,在这儿排队执行,执行完一个消失一个,当所有的命令都执行完了,OK,结果达到了。
但是如果现在我们执行的时候save指令保存的数据量很大会是什么现象呢?
他会非常耗时,以至于影响到它在执行的时候,后面的指令都要等,所以说这种模式是不友好的,这是save指令对应的一个问题,当cpu执行的时候会阻塞redis服务器,直到他执行完毕,所以说我们不建议在线上环境用save指令
3. bgsave指令
当save指令的数据量过大时,单线程执行方式造成效率过低,
此时我们可以使用:bgsave指令,bg其实是background的意思,后台执行的意思
手动启动后台保存操作,但不是立即执行
bgsave工作原理:当执行bgsave的时候,客户端发出bgsave指令给到redis服务器。注意,这个时候服务器马上回一个结果告诉客户端后台已经开始了,与此同时它会创建一个子进程,使用Linux的fork函数创建一个子进程,让这个子进程去执行save相关的操作
4. save设置自动执行
这里说明一下,save指令在开始的时候默认是需要我们手动输入指令才能保存的,懒星人受不了这个,所以我们可以通过
save second changes
设置自动持久化的条件,满足限定时间范围内key的变化数量达到指定数量即进行持久化
参数
second:监控时间范围
changes:监控key的变化量
5. RDB的优点
-
RDB是一个紧凑压缩的二进制文件,存储效率较高
-
RDB内部存储的是redis在某个时间点的数据快照,非常适合用于数据备份,全量复制等场景
-
RDB恢复数据的速度要比AOF快很多
-
应用:服务器中每X小时执行bgsave备份,并将RDB文件拷贝到远程机器中,用于灾难恢复
6. RDB的缺点
-
RDB方式无论是执行指令还是利用配置,无法做到实时持久化,具有较大的可能性丢失数据
-
bgsave指令每次运行要执行fork操作创建子进程,要牺牲掉一些性能
-
Redis的众多版本中未进行RDB文件格式的版本统一,有可能出现各版本服务之间数据格式无法兼容现象
三、AOF
1. AOF的存储方式
AOF的存储方式是一种日志的形式,开启AOF之后就会记录每一次对于数据的操作(增删改),查询操作是不记录的,因为没对数据没有发生变化
AOF持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令 达到恢复数据的目的。与RDB相比可以简单理解为由记录数据改为记录数据产生的变化
AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
2. AOF执行策略
AOF写数据三种策略(appendfsync)
-
always(每次):每次写入操作均同步到AOF文件中数据零误差,性能较低,不建议使用。
-
everysec(每秒):每秒将缓冲区中的指令同步到AOF文件中,在系统突然宕机的情况下丢失1秒内的数据 数据准确性较高,性能较高,建议使用,也是默认配置
-
no(系统控制):由操作系统控制每次同步到AOF文件的周期,整体过程不可控
3. AOF重写
什么叫AOF重写?
-
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制压缩文件体积。
-
AOF文件重 写是将Redis进程内的数据转化为写命令同步到新AOF文件的过程。
-
简单说就是将对同一个数据的若干个条命令执行结 果转化成最终结果数据对应的指令进行记录。
举个栗子来理解,如下图情况
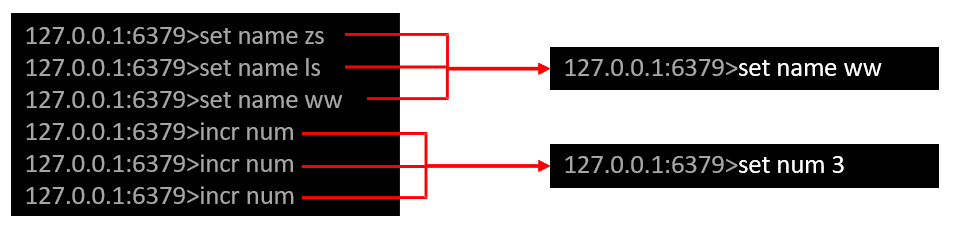
可以看到我们对于一个数据的值修改了多次,但其实这个'name'变量最终值只与最后一条set指令设置的值有关,所以将最后一个语句拎出来到一个新的AOF文件中
同理可得,第二部分我们对于一个数据进行了n次+1操作,但其实就是+n,重写这一部分的语句到新的AOF文件中,这样我们就能极致的压缩AOF文件大小
4.AOF重写的作用
-
降低磁盘占用量,提高磁盘利用率
-
提高持久化效率,降低持久化写时间,提高IO性能
-
降低数据恢复用时,提高数据恢复效率
5. AOF工作流程
①. Client作为命令的来源,会有多个源头以及源源不断的请求命令
②. 在这些命令到达Redis Server 以后并不是直接写入AOF文件,会将其这些命令先放入AOF缓存中进行保存。这里的AOF缓冲区实际上是内存中的一片区域,存在的目的是当这些命令达到一定
量以后再写入磁盘,避免频繁的磁盘IO操作
③. AOF缓冲会根据AOF缓冲区同步文件的三种写回策略将命令写入磁盘上的AOF文件
④. 随着写入AOF内容的增加为避免文件膨胀,会根据规则进行命令的合并(又称AOF重写),从而起到AOF文件压缩的目的
⑤. 当Redis Server 服务器重启的时候会从AOF文件载入数据。
四、RDB与AOF区别
| 持久化方式 | RDB | AOF |
|---|---|---|
| 占用存储空间 | 小(数据级:压缩) | 大(指令级:重写) |
| 存储速度 | 慢 | 快 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 会丢失数据 | 依据策略决定 |
| 资源消耗 | 高/重量级 | 低/轻量级 |
| 启动优先级 | 低 | 高 |
五、 RDB与AOF应用场景
1. 对数据非常敏感,建议使用默认的AOF持久化方案
AOF持久化策略使用everysecond,每秒钟fsync一次。该策略redis仍可以保持很好的处理性能,当出 现问题时,最多丢失0-1秒内的数据。
注意:由于AOF文件存储体积较大,且恢复速度较慢
2. 数据呈现阶段有效性,建议使用RDB持久化方案
数据可以良好的做到阶段内无丢失(该阶段是开发者或运维人员手工维护的),且恢复速度较快,阶段 点数据恢复通常采用RDB方案
注意:利用RDB实现紧凑的数据持久化会使Redis降的很低,慎重总结:
3.综合比对
-
RDB与AOF的选择实际上是在做一种权衡,每种都有利有弊
-
如不能承受数分钟以内的数据丢失,对业务数据非常敏感,选用AOF
-
如能承受数分钟以内的数据丢失,且追求大数据集的恢复速度,选用RDB
-
灾难恢复选用RDB
-
双保险策略,同时开启 RDB和 AOF,重启后,Redis优先使用 AOF 来恢复数据,降低丢失数据的量
说了半天,其实当然是要RDB和AOF同时开启才能将利益最大化,毕竟这俩都是有利有弊嘛,平时我们采用轻量级的AOF,再定期给数据拍张照(RDB),双重保障更安心
个人感觉持久化应该是很重要的吧,但是我目前没遇到面试有问啊,难道是太简单了,真的太简单了,总结的时候就什么都想写进去,但其实如果真是问到的话也就两句话就能说明白了
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
