首页 > 基础资料 博客日记
【经典算法】LeetCode133克隆图(Java/C/Python3实现含注释说明,中等)
2024-05-08 10:00:08基础资料围观533次
🙊🙊作者主页: 🔗进朱者赤的博客
📔📔 精选专栏:🔗经典算法
作者简介:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名)💞💞觉得文章还不错的话欢迎大家点赞👍➕收藏⭐️➕评论💬支持博主🤞
————————————————-
- 标签(题目类型):图、图的遍历、DFS、BFS
题目描述
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
public int val;
public List<Node> neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),
第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:
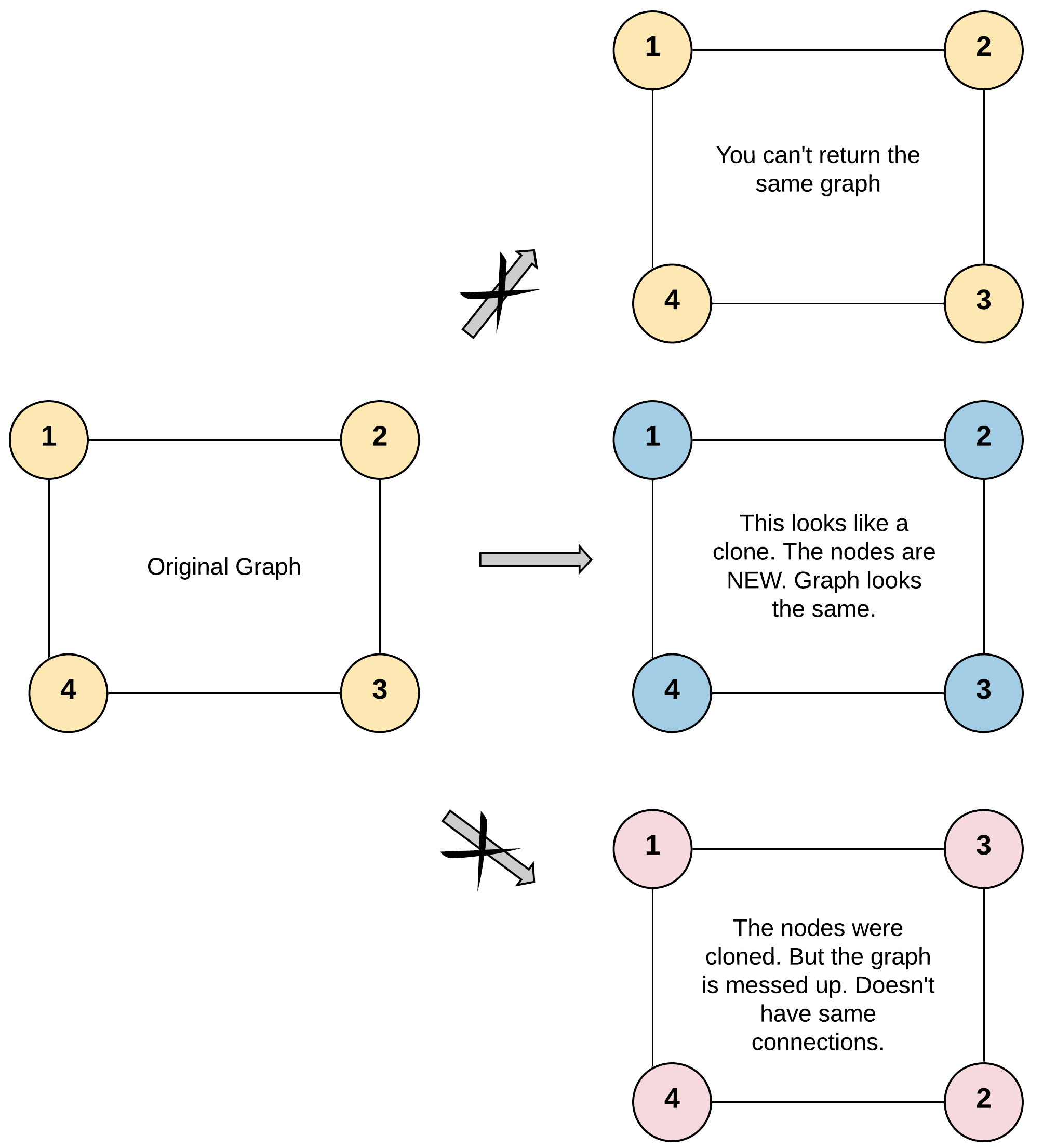
输入:adjList = [[2,4],[1,3],[2,4],[1,3]]
输出:[[2,4],[1,3],[2,4],[1,3]]
解释:
图中有 4 个节点。
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
示例 2:
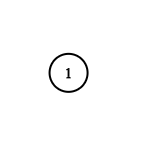
输入:adjList = [[]]
输出:[[]]
解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
示例 3:
输入:adjList = []
输出:[]
解释:这个图是空的,它不含任何节点。
提示:
这张图中的节点数在 [0, 100] 之间。
1 <= Node.val <= 100
每个节点值 Node.val 都是唯一的,
图中没有重复的边,也没有自环。
图是连通图,你可以从给定节点访问到所有节点。
原题:LeetCode 133
思路及实现
方式一:深度优先搜索(DFS)
思路
对于图中的每个节点,我们可以使用深度优先搜索(DFS)来遍历图,并在遍历的过程中复制节点和边。首先,我们需要创建一个与原始图相同大小的空图来存储克隆结果。然后,我们可以从任意节点开始,递归地遍历图,并在遍历过程中复制节点和边。
在遍历过程中,我们需要使用一个哈希表来存储原始节点和克隆节点之间的映射关系,以避免重复复制节点。当我们遇到一个尚未复制的节点时,我们创建它的克隆节点,并将其添加到克隆图中。然后,我们递归地复制与该节点直接相连的所有节点,并在克隆图中添加相应的边。
代码实现
Java版本
import java.util.*;
class Node {
public int val;
public List<Node> neighbors;
public Node() {
val = 0;
neighbors = new ArrayList<Node>();
}
public Node(int _val) {
val = _val;
neighbors = new ArrayList<Node>();
}
public Node(int _val, ArrayList<Node> _neighbors) {
val = _val;
neighbors = _neighbors;
}
}
public class Solution {
private Map<Node, Node> visited = new HashMap<>();
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
// 如果已经访问过该节点,则直接返回克隆节点
if (visited.containsKey(node)) {
return visited.get(node);
}
// 创建克隆节点
Node cloneNode = new Node(node.val);
visited.put(node, cloneNode); // 将原始节点和克隆节点映射关系存入哈希表
// 递归复制邻居节点,并添加边到克隆图中
for (Node neighbor : node.neighbors) {
cloneNode.neighbors.add(cloneGraph(neighbor));
}
return cloneNode;
}
}
说明:
使用了一个visited哈希表来存储原始节点和克隆节点之间的映射关系。
递归地复制邻居节点,并在克隆图中添加相应的边。
C语言版本
C语言实现相对复杂,因为C语言没有内置的数据结构如哈希表,需要自己实现图的节点和邻接表,以及节点的复制逻辑。
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// 定义节点结构
struct Node {
int val;
int numNeighbors;
struct Node** neighbors;
};
// 深度优先搜索函数
struct Node* cloneGraphDFS(struct Node* node, struct Node** clones) {
// 如果节点为空,则返回空
if (node == NULL)
return NULL;
// 如果节点已经克隆过,则直接返回克隆节点
if (clones[node->val] != NULL)
return clones[node->val];
// 创建当前节点的克隆节点
struct Node* cloneNode = (struct Node*)malloc(sizeof(struct Node));
cloneNode->val = node->val;
cloneNode->numNeighbors = node->numNeighbors;
cloneNode->neighbors = (struct Node**)malloc(cloneNode->numNeighbors * sizeof(struct Node*));
clones[cloneNode->val] = cloneNode;
// 遍历当前节点的邻居节点
for (int i = 0; i < node->numNeighbors; i++) {
// 递归克隆邻居节点并将克隆节点添加到当前节点的克隆节点的邻居列表中
cloneNode->neighbors[i] = cloneGraphDFS(node->neighbors[i], clones);
}
return cloneNode;
}
// 克隆图函数
struct Node* cloneGraph(struct Node* node) {
// 创建一个数组用于存储已克隆的节点
struct Node* clones[101] = { NULL };
// 调用深度优先搜索函数
return cloneGraphDFS(node, clones);
}
说明:
使用深度优先搜索(DFS)的方式进行图的克隆。通过递归地遍历节点以及节点的邻居节点,创建克隆节点,并将克隆节点的邻居节点也进行克隆,并添加到克隆节点的邻居列表中。使用clones数组来存储已克隆的节点,避免重复克隆。
通过该C语言版本实现的深度优先搜索,在图较大时可能会导致栈溢出。如果需要处理大型图,可以考虑使用循环和栈来替代递归,以减少栈空间的消耗。
Python3版本
class Solution:
def cloneGraph(self, node: 'Node') -> 'Node':
if not node:
return None
visited = {}
def clone(node):
if node in visited:
return visited[node]
# 克隆当前节点
clone_node = Node(node.val)
visited[node] = clone_node
# 遍历当前节点的邻居节点,并进行克隆
for neighbor in node.neighbors:
clone_node.neighbors.append(clone(neighbor))
return clone_node
return clone(node)
说明:
使用了一个visited字典来存储原始节点和克隆节点之间的映射关系。
递归地复制邻居节点,并在克隆图中添加相应的边。
复杂度分析
- 时间复杂度:O(N+E),其中 N 是节点的个数,E 是边的个数。
- 空间复杂度:O(N),使用哈希表来存储已克隆的节点。
方式二:(可选)广度优先搜索(BFS)
思路
使用广度优先搜索(BFS)遍历图,并在遍历过程中进行节点的克隆。为了避免重复克隆已经访问过的节点,可以使用一个哈希表来存储已经克隆的节点。具体实现时,可以使用一个队列来辅助进行广度优先搜索,并通过队列来顺序访问节点的邻居节点并进行克隆。
代码实现
Java版本
class Solution {
public Node cloneGraph(Node node) {
if (node == null)
return null;
// 创建HashMap用于存储已克隆的节点
Map<Node, Node> visited = new HashMap<>();
// 创建队列用于辅助广度优先搜索
Queue<Node> queue = new LinkedList<>();
// 初始节点克隆
Node cloneNode = new Node(node.val, new ArrayList<>());
visited.put(node, cloneNode);
queue.offer(node);
while (!queue.isEmpty()) {
Node currNode = queue.poll();
// 遍历当前节点的邻居节点
for (Node neighbor : currNode.neighbors) {
if (!visited.containsKey(neighbor)) {
// 如果邻居节点未克隆过,则进行克隆
visited.put(neighbor, new Node(neighbor.val, new ArrayList<>()));
queue.offer(neighbor);
}
// 将克隆的邻居节点添加到当前节点的克隆节点的邻居列表中
visited.get(currNode).neighbors.add(visited.get(neighbor));
}
}
return cloneNode;
}
}
说明:
利用HashMap存储已克隆的节点,以避免重复克隆。
使用队列辅助进行BFS遍历,从初始节点开始,一层一层地克隆节点并处理邻居节点。
C语言版本
/** Definition for a Node. */
struct Node {
int val;
int numNeighbors;
struct Node** neighbors;
};
struct Node* cloneGraph(struct Node* node) {
if (node == NULL)
return NULL;
// 创建一个HashMap用于存储已克隆的节点
struct Node* clones[101] = { NULL };
// 创建一个队列用于辅助广度优先搜索
Queue* queue = createQueue();
// 创建初始节点克隆
struct Node* cloneNode = (struct Node*)malloc(sizeof(struct Node));
cloneNode->val = node->val;
cloneNode->numNeighbors = node->numNeighbors;
cloneNode->neighbors = (struct Node**)malloc(cloneNode->numNeighbors * sizeof(struct Node*));
clones[cloneNode->val] = cloneNode;
// 将原始节点入队
enqueue(queue, node);
while (!isEmpty(queue)) {
// 出队当前节点
struct Node* currNode = dequeue(queue);
// 遍历当前节点的邻居节点
for (int i = 0; i < currNode->numNeighbors; i++) {
// 如果邻居节点未克隆过,则进行克隆
if (clones[currNode->neighbors[i]->val] == NULL) {
clones[currNode->neighbors[i]->val] = (struct Node*)malloc(sizeof(struct Node));
clones[currNode->neighbors[i]->val]->val = currNode->neighbors[i]->val;
clones[currNode->neighbors[i]->val]->numNeighbors = currNode->neighbors[i]->numNeighbors;
clones[currNode->neighbors[i]->val]->neighbors = (struct Node**)malloc(clones[currNode->neighbors[i]->val]->numNeighbors * sizeof(struct Node*));
enqueue(queue, currNode->neighbors[i]);
}
// 将克隆的邻居节点添加到当前节点的克隆节点的邻居列表中
cloneNode->neighbors[i] = clones[currNode->neighbors[i]->val];
}
}
return cloneNode;
}
说明
利用clones数组存储已克隆的节点,下标为节点值。
使用自定义的队列数据结构辅助进行BFS遍历。
Python3版本
class Solution:
def cloneGraph(self, node: 'Node') -> 'Node':
if not node:
return None
# 创建字典用于存储已克隆的节点
visited = {}
# 创建队列用于辅助广度优先搜索
queue = deque()
# 初始节点克隆
clone_node = Node(node.val)
visited[node] = clone_node
queue.append(node)
while queue:
curr_node = queue.popleft()
# 遍历当前节点的邻居节点
for neighbor in curr_node.neighbors:
if neighbor not in visited:
# 如果邻居节点未克隆过,则进行克隆
visited[neighbor] = Node(neighbor.val)
queue.append(neighbor)
# 将克隆的邻居节点添加到当前节点的克隆节点的邻居列表中
visited[curr_node].neighbors.append(visited[neighbor])
return clone_node
说明:
利用visited字典存储已克隆的节点,以避免重复克隆。
使用内置的deque数据结构实现队列,辅助进行BFS遍历。
复杂度分析
- 时间复杂度:O(N + E),其中N是节点的个数,E是边的个数。
- 空间复杂度:O(N),用于存储已克隆的节点和队列的空间。
总结
| 方式 | 优点 | 缺点 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| DFS | 直观易理解 | 可能需要较多递归调用栈空间 | O(V + E) | O(V) |
| BFS | 层次遍历 | 需要额外维护队列 | O(V + E) | O(V) |
相似题目
| 相似题目 | 难度 | 链接 |
|---|---|---|
| 图的深度优先搜索 | 中等 | LeetCode 200 |
| 图的广度优先搜索 | 中等 | LeetCode 130 |
| 克隆含有随机指针的节点 | 困难 | LeetCode 138 |
注意:上述相似题目中的链接是指向类似问题的LeetCode题目,而不是直接关联到克隆图问题的相似题目。对于克隆图这类特定问题,可能没有直接的相似题目,但它可以看作是图遍历问题的一个变种。
欢迎一键三连(关注+点赞+收藏),技术的路上一起加油!!!代码改变世界
关于我:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名),回复暗号,更能获取学习秘籍和书籍等
—⬇️欢迎关注我的公众号:
进朱者赤,认识不一样的技术人。⬇️—
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
