首页 > 基础资料 博客日记
项目中使用雪花算法id生成工具
2024-02-26 16:00:05基础资料围观641次
文章项目中使用雪花算法id生成工具分享给大家,欢迎收藏Java资料网,专注分享技术知识
今天参与新项目,发现项目中使用的是uuid,写一篇优化方案给领导
1、雪花算法id与uuid的对比
| 雪花算法 | UUID | |
|---|---|---|
| 类型 | Long | 字符串 |
| 占用空间 | 8byte | 16byte |
| 顺序性 | 自增有序 | 无序 |
| 索引结构影响 | 无影响 | 新增、删除数据会导致索引结构重排序 |
| 数据库要求 | mysql官方强烈建议不要使用uuid |
首先,使用 UUID 作为主键可能会导致索引性能下降,因为 UUID 是随机生成的字符串,不像自增主键是连续的数字。这可能会导致索引分散在整个表中,而不是集中在一起,从而影响查询性能。
其次,使用 UUID 作为主键可能会导致存储空间的浪费,因为 UUID 是一个较长的字符串,需要更多的存储空间。这可能会影响数据库的性能和可伸缩性,尤其是在处理大型数据集时。
2、项目中整合雪花算法
2.1、hutool工具包中提供了雪花算法生成工具类
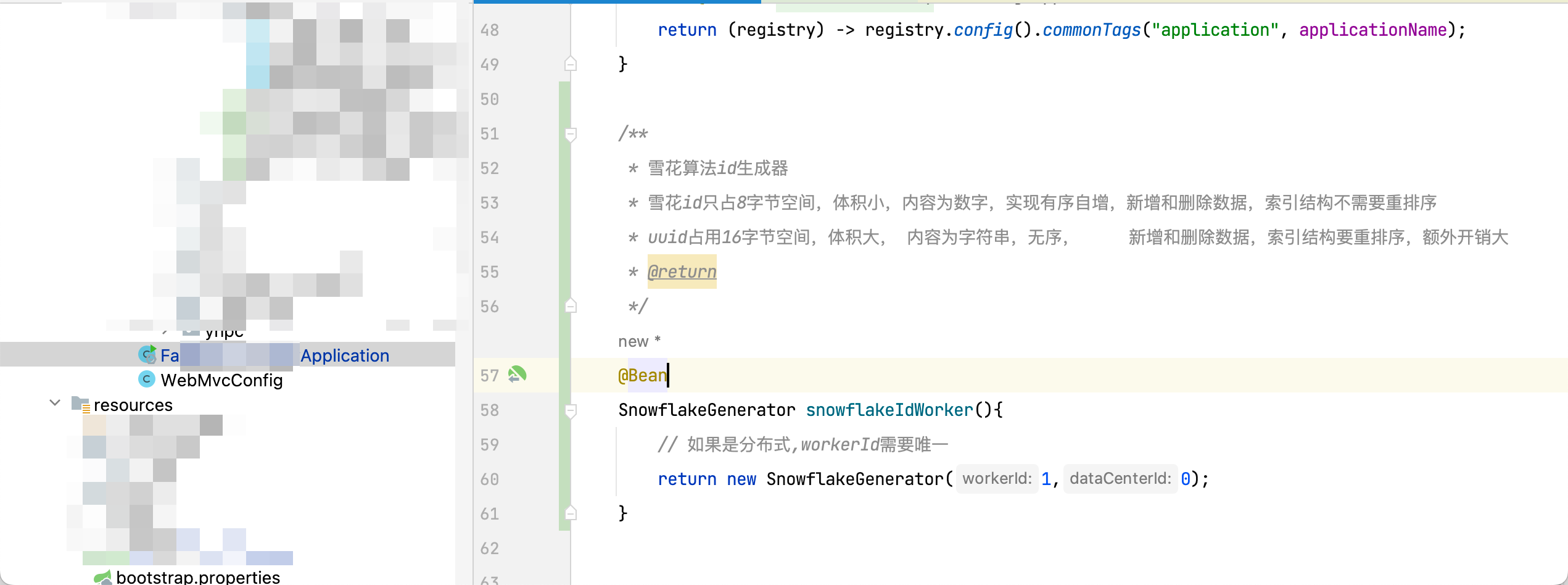
2.1.1、在启动类中配置SnowflakeGenerator,将其注册到spring容器中
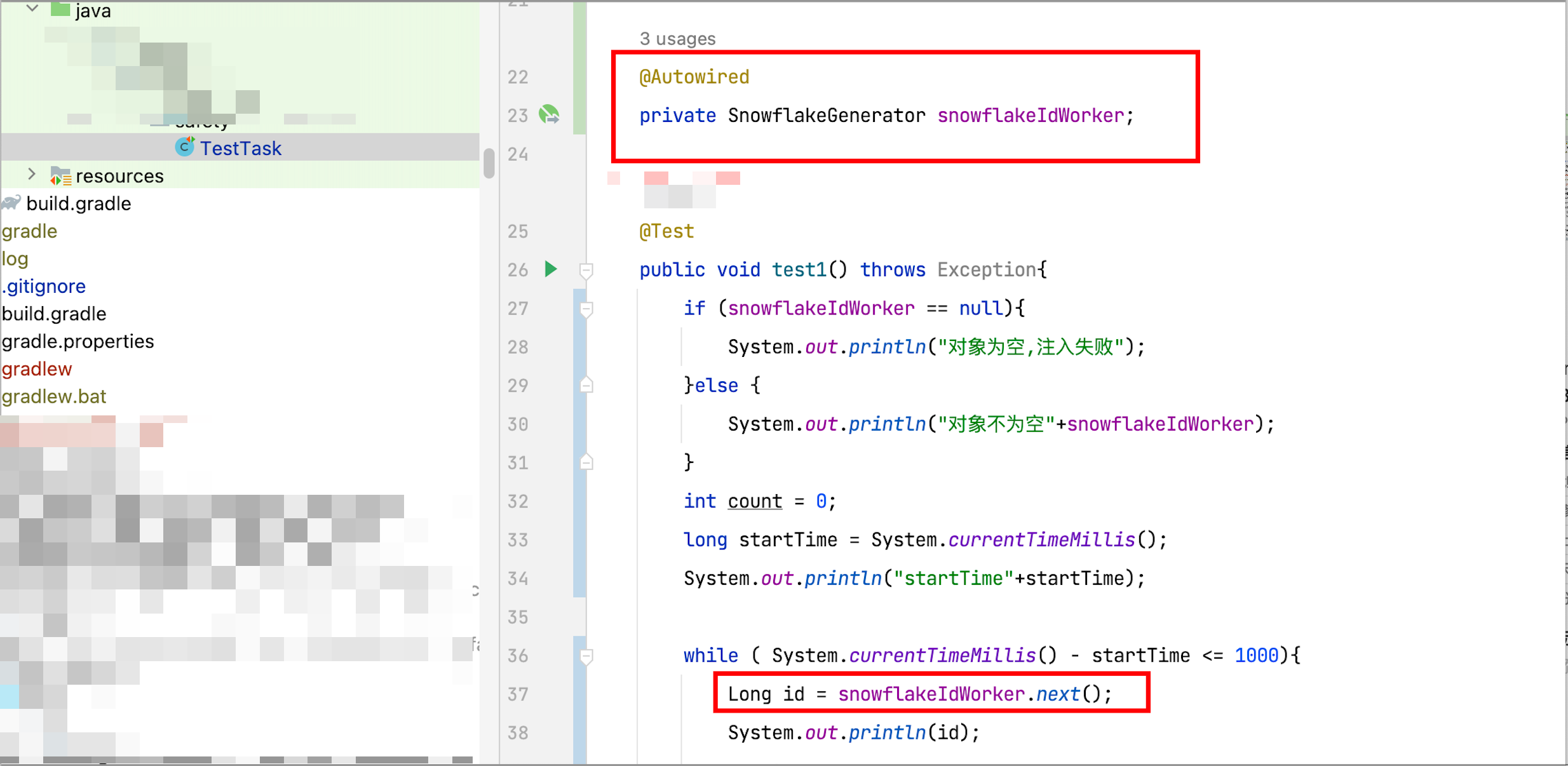
2.1.2、使用方式
在需要使用的类中,注入SnowflakeGenerator即可食用
生成的id内容:
1632932158878258313
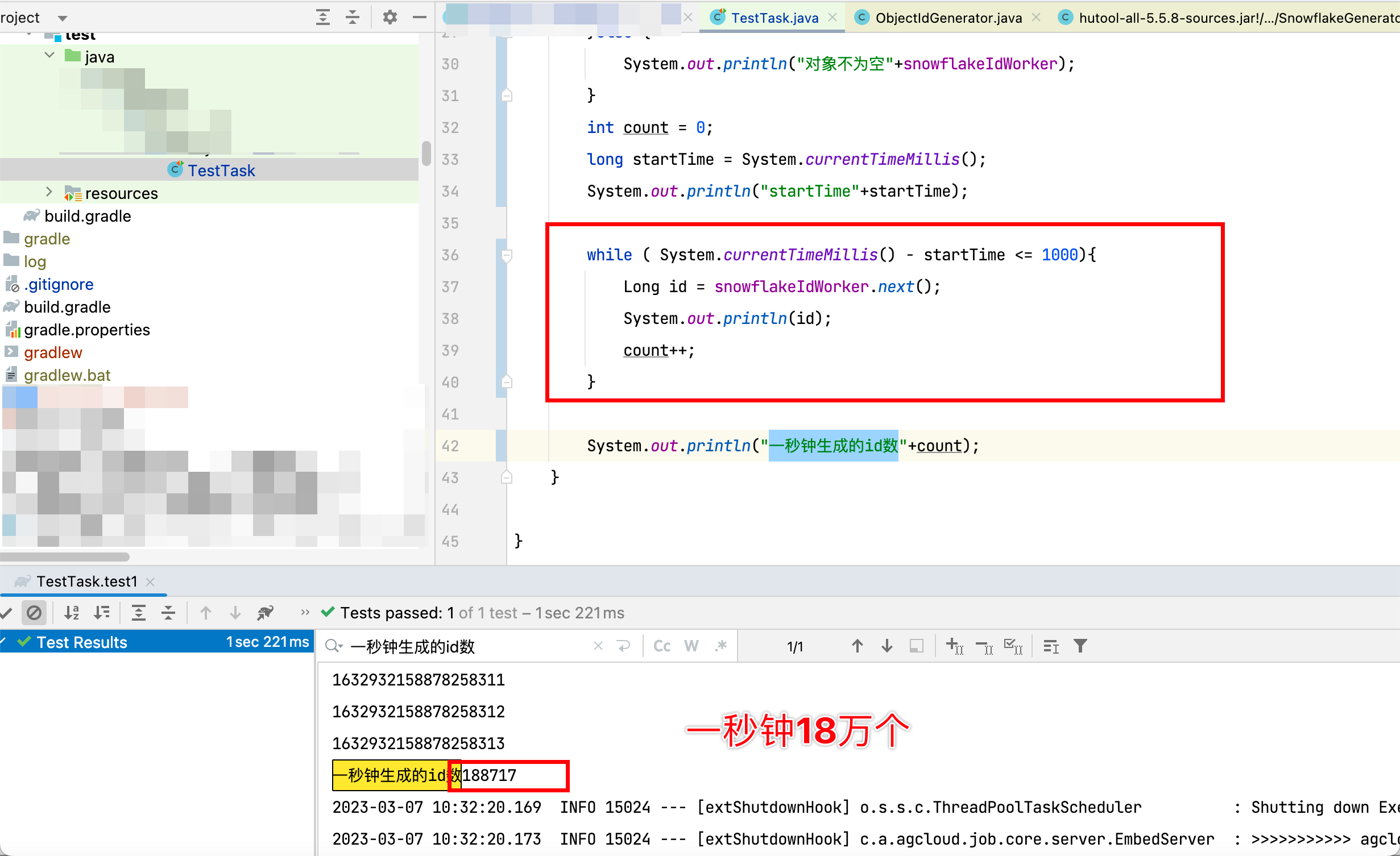
2.2、性能测试
3、数据库主键建议
雪花算法是64位二进制位的大整数,64/8 = 8字节
mysql使用bitint,bigint类型有64位,64/8 = 8字节, 刚好满足
postgresql使用int8, int8一共8字节空间,刚好满足
4、手撸一个雪花算法id生成工具类
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
/**
* @Author bytesMaster
* @Date 2023/3/7
* @Description 雪花算法id生成器
* 雪花id只占8字节空间,体积小,内容为数字,实现有序自增,新增和删除数据,索引结构不需要重排序
* uuid占用16字节空间,体积大, 内容为字符串,无序, 新增和删除数据,索引结构要重排序,额外开销大
*/
public class SnowFlakeIdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1678154396522L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public SnowFlakeIdWorker(){
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId
* 工作机器ID
* @param datacenterId
* 序列号
*/
public SnowFlakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一次 ID 生成的时间戳,说明发生时钟回拨,为保证ID不重复抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* 获取 maxWorkerId
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* 数据标识id部分
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}
5、传输前端后精度丢失
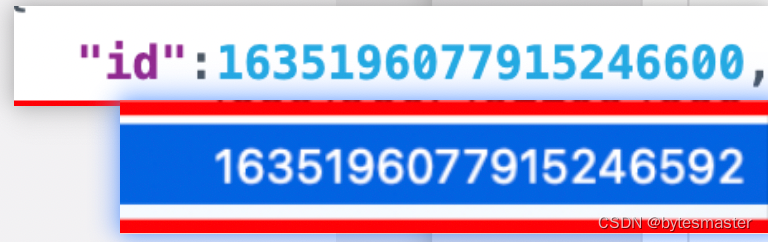
数据库中的id是: 1635196077915246592
前端接收到的是:1635196077915246600
被四舍五入了
这是因为JS是弱语言,前端接收数字类型参数为number
最大接收长度为16位,超出长度则会丢失精度
而JAVA的Long类型长度为19位,所以传输到前端的后三位精度丢失
所以我们解决该问题的思路就是:把java里的Long类型转换为String返回给前端
在实体类中的id字段加上注解:
@ApiModelProperty(value = "雪花算法生成的主键")
@JsonFormat(shape = JsonFormat.Shape.STRING)//此句为问题关键相当于吧Long转换为String
@JSONField(serializeUsing = ToStringSerializer.class) //此处标识得在序列化的时候转换为字符串
private Long id;
需要引入:com.fasterxml.jackson.core依赖
返回给前端的id就变成字符串了
文章来源:https://blog.csdn.net/weixin_43550533/article/details/129381199
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
