首页 > 基础资料 博客日记
java集合(超详细)
2023-07-24 10:54:01基础资料围观637次
1 - 概述
所有的集合类和集合接口都在java.util包下。
在内存中申请一块空间用来存储数据,在Java中集合就是替换掉定长的数组的一种引用数据类型。
2 - 集合与数组的区别
长度区别
数组长度固定,定义长了造成内存空间的浪费,定义短了不够用。
集合大小可以变,用多少空间拿多少空间。
内容区别
数组可以存储基本数据类型和引用数据类型
集合中能存储引用数据类型(存储的为对象的内存地址)
list.add(100);//为自动装箱,100为Integer包装的
元素区别
数组中只能存储同一种类型成员
集合中可以存储不同类型数据(一般情况下也只存储同一种类型的数据)
集合结构
在java中每一个不同的集合,底层会对应不同的数据结构。往不同的集合中
存储元素,等于将数据放到了不同的数据结构当中。什么是数据结构?数据存储的
结构就是数据结构。不同的数据结构,数据存储方式不同。
-
单列集合 Collection
-
List可以重复:ArrayList/LinkedList
-
Set不可重复:HashSet/TreeSet
-
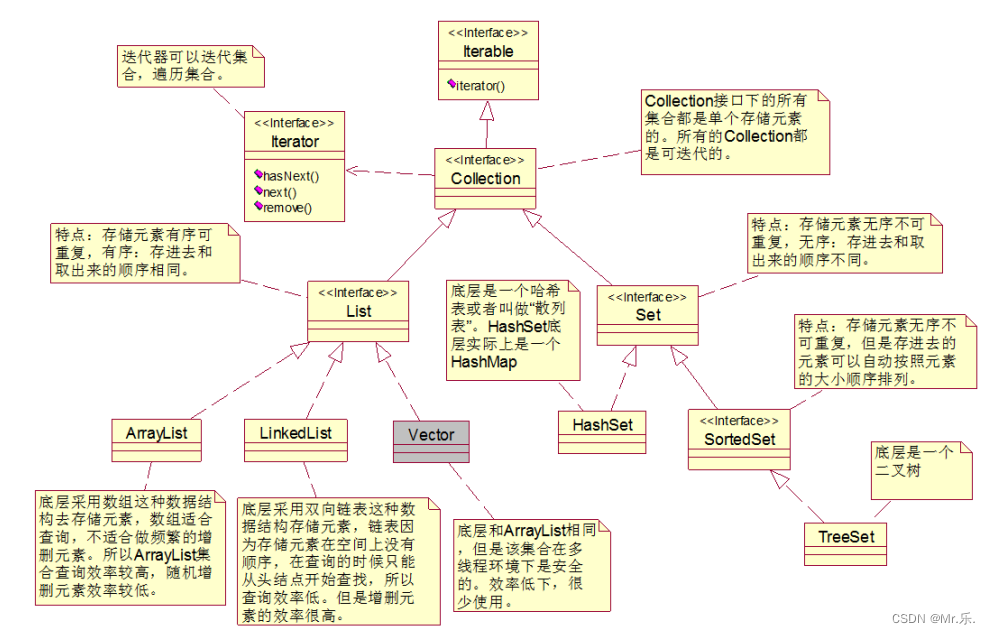
(大量文字插入会导致图片不清,所以在此进行更详细的描述)
-
List特点:此处顺序并不是大小顺序,而是存入数据的先后顺序。有序因为List集合都有下标,下标从0开始,以递增。
-
Set特点:取出顺序不一定为存入顺序,另外Set集合没有下标。
-
ArrayList是非线程安全的。
-
HashSet集合在new的时候,底层实际上new了一个HashMap集合。向HashSet集合中存储元素,实际上是存储到了HashMap的key中了。HashMap集合是一个Hash表数据结构。
-
SortedSet集合存储元素的特点:由于继承了Set集合,所以他的特点也是无序不可重复,但是放在SortedSet集合中的元素可以自动排序。放到该集合中的元素是自动按照大小顺序排序的。
-
TreeSet集合底层实际上是TreeMap。TreeSet集合在new的时候,底层实际上new了一个TreeMap集合。向TreeSet集合中存储元素,实际上是存储到了TreeMap的key中了。TreeMap集合是一个二叉树数据结构。
-
-
双列集合Map:HashMap/TreeMap

粗体是接口 斜体是实现类
3 - Collection集合
3.1 - 概述
单列集合的顶层接口,既然是接口就不能直接使用,需要通过实现类!~
3.2 - Collection集合的的常用方法
| 方法名 | 说明 |
|---|---|
boolean add(E e) | 添加元素到集合的末尾(追加) |
boolean remove(Object o) | 删除指定的元素,成功则返回true(底层调用equles) |
void clear() | 清空集合 |
boolean contains(Object o) | 判断元素在集合中是否存在,存在则返回true(底层调用equles) |
boolean isEmpty() | 判断集合是否为空,空则返回true |
int size() | 返回集合中元素个数 |
import java.util.ArrayList;
import java.util.Collection;
/**
* @author Mr.乐
* @Description
*/
public class Collection_01 {
public static void main(String[] args) {
//父类的引用指向子类的对象,形成多态
Collection<String> con = new ArrayList<>();
//追加的方式添加元素
con.add("东邪");
con.add("西毒");
con.add("南帝");
con.add("北丐");
con.add("中神通");
//删除,通过元素名称删除元素
System.out.println(con.remove("西毒"));
//判断集合中是否包含指定参数元素
System.out.println(con.contains("西毒")); //false
System.out.println(con.contains("东邪")); //true
//获取集合中元素个数
System.out.println(con.size());
//判断是否为空
System.out.println(con.isEmpty());//false
//清空集合
con.clear();
//判断是否为空
System.out.println(con.isEmpty());//true
System.out.println(con);//打印集合的元素
}
}3.3 - Collection集合的遍历
以下迭代方式,是所有Collection通用的一种方式。在Map集合中不能使用,在所有的Collection以及子类中使用。
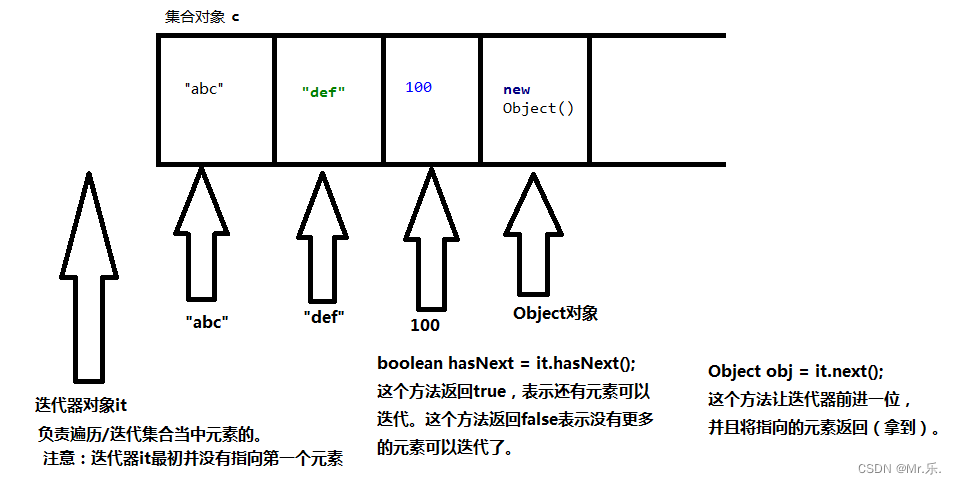
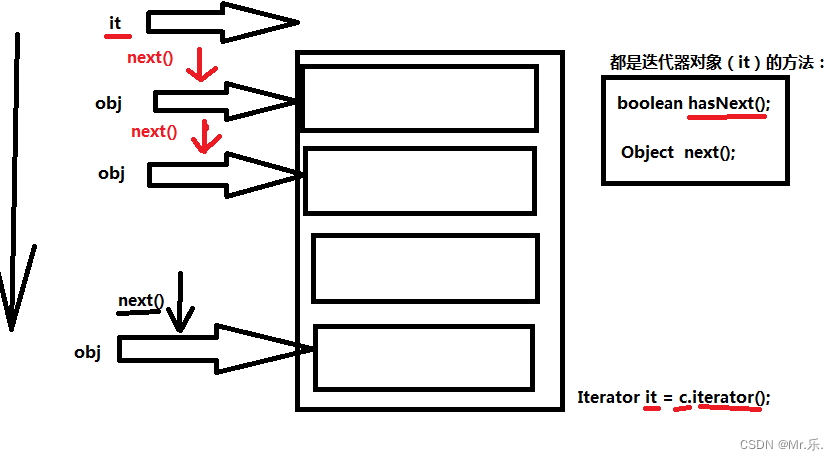
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author Mr.乐
* @Description Collection 集合的遍历
*/
public class Connection_02 {
public static void main(String[] args) {
//多态
Collection<String> con = new ArrayList<>();
//添加元素
con.add("abc");
con.add("def");
con.add("100");
con.add("444");
//Collection集合的遍历方式
//因为没有索引的概念,所以Collection集合不能使用fori进行遍历
//增强版for循环,其实底层使用的也是迭代器,在字节码文件中查看
for (String str : con) {
System.out.print(str + "\t");
}
System.out.println();//换行
//迭代器,集合专属的遍历工具
Iterator<String> it = con.iterator();//创建迭代器对象
while (it.hasNext()){//判断下一个位置是否有元素
System.out.print(it.next() + "\t");//获取到下一个位置的元素
}
}
}
3.4 - Iterator的remove
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author Mr.乐
* @Description
*/
public class Connection_remove {
public static void main(String[] args) {
// 创建集合
Collection c = new ArrayList();
// 注意:此时获取的迭代器,指向的是那是集合中没有元素状态下的迭代器。
// 一定要注意:集合结构只要发生改变,迭代器必须重新获取。
// 当集合结构发生了改变,迭代器没有重新获取时,调用next()方法时:java.util.ConcurrentModificationException
Iterator it = c.iterator();
// 添加元素
c.add(1); // Integer类型
c.add(2);
c.add(3);
// 获取迭代器
//Iterator it = c.iterator();
/*while(it.hasNext()){
// 编写代码时next()方法返回值类型必须是Object。
// Integer i = it.next();
Object obj = it.next();
System.out.println(obj);
}*/
Collection c2 = new ArrayList();
c2.add("abc");
c2.add("def");
c2.add("xyz");
Iterator it2 = c2.iterator();
while(it2.hasNext()){
Object o = it2.next();
// 删除元素
// 删除元素之后,集合的结构发生了变化,应该重新去获取迭代器
// 但是,循环下一次的时候并没有重新获取迭代器,所以会出现异常:java.util.ConcurrentModificationException
// 出异常根本原因是:集合中元素删除了,但是没有更新迭代器(迭代器不知道集合变化了)
//c2.remove(o); // 直接通过集合去删除元素,没有通知迭代器。(导致迭代器的快照和原集合状态不同。)
// 使用迭代器来删除可以吗?
// 迭代器去删除时,会自动更新迭代器,并且更新集合(删除集合中的元素)。
it2.remove(); // 删除的一定是迭代器指向的当前元素。
System.out.println(o);
}
System.out.println(c2.size()); //0
}
}
4 -List
原型ArrayList<E>
-
ArrayList是一个List接口的实现类,底层使用的是一个可以调整大小的数组实现的。
-
<E>:是一种特殊的数据类型(引用数据类型) -- 泛型-
ArrayList<String> 或者 ArrayList<Integer> 或者 ArrayList<Student>
-
4.1 - ArrayList构造和添加方法
| 方法名 | 说明 |
|---|---|
public ArrayList<E>() | 创建一个空集合 |
public boolean add(E e) | 将指定的参数元素追加到集合的末尾 |
public void add(int index ,E e) | 在集合的指定位置添加指定的元素(插入元素) |
public void addAll(E object) | 用于将指定集合中所有元素添加到当前集合中 |
/**
* @author Mr.乐
* @Description ArrayList构造和添加方法
*/
public class ArrayList_01 {
public static void main(String[] args) {
//创建空集合
ArrayList<String> list = new ArrayList<>();//泛型定义为String
//采用默认追加的方式添加元素
System.out.println(list.add("刘德华"));
System.out.println(list.add("张学友"));
System.out.println(list.add("郭富城"));
System.out.println(list.add("黎明"));
//插入的方式添加元素
// list.add(10,"谭咏麟");//插入元素方法索引值不能大于集合中元素个数
// list.add(4,"谭咏麟");//表示在集合中最后位置插入元素,与追加相同
list.add(1,"谭咏麟");//指定位置插入元素,索引位置之后的元素会自动向后进行移动
ArrayList<String> newList = new ArrayList<>();//创建新的集合
newList.add("小沈阳");
newList.add("宋小宝");
newList.add("赵四");
newList.add("刘能");
//查看集合中的元素
System.out.println("原集合内部元素:" + list);
System.out.println("新集合内部元素:" + newList);
list.addAll(newList); //将新集合全部元素添加到原集合中
System.out.println("原集合内部元素:" + list);
}
}
4.2 - ArrayList集合常用方法
| 方法名 | 说明 |
|---|---|
public boolean remove(Object o) | 删除指定的元素,成功则返回true |
public E remove(int index) | 删除指定索引位置的元素,返回被删除的元素 |
public E set(int index,E e) | 修改指定索引位置的元素,返回修改前的元素 |
public E get(int index) | 获取指定索引对应的元素 |
public int size() | 获取结合中元素个数 |
import java.util.ArrayList;
import java.util.Iterator;
/**
* @author Mr.乐
* @Description ArrayList集合常用方法
*/
public class ArrayList_02 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
//追加方式添加元素
list.add("东邪");
list.add("西毒");
list.add("南帝");
list.add("北丐");
list.add("中神通");
//删除
System.out.println(list.remove("西毒"));//通过元素名称删除,返回boolean
System.out.println(list.remove(1));//通过索引删除元素,返回被删除元素名
//修改
System.out.println(list.set(1,"西毒"));//指定索引位置修改元素,并返回被修改元素
System.out.println("原集合中元素有:" + list);
//获取方法
System.out.println(list.get(1));//通过指定索引位置获取集合元素
//获取集合元素个数
System.out.println(list.size());
//集合的遍历,普通for循环
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + "\t");
}
System.out.println();
//增强版for循环
for (String name : list) {
System.out.print(name+ "\t");
}
System.out.println();
//迭代器
Iterator<String> it = list.iterator();//创建迭代器
while (it.hasNext()){//判断下一个位置是否有元素
System.out.print(it.next() + "\t"); //next方法表示获取下一个位置的元素
}
System.out.println();
//Stream流
list.stream().forEach(System.out::println);
}
}
4.3 -ArrayList实现原理
底层代码:
属性:
DEFAULT_CAPACITY = 10 默认长度,初始化容量为10
Object[] EMPTY_ELEMENTDATA = {} //有参构造所创建
Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {} //无参构造所创建的
Object[] elementData;底层为Object类型的数组,存储的元素都在此。
int size 实际存放的个数
构造方法 :
//一个参数的构造
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//参数如果大于零,则为创建数组的长度;
//参数如果等于零,EMPTY_ELEMENTDATA;
//参数如果小于0,抛出异常。
//无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//DEFAULTCAPACITY_EMPTY_ELEMENTDATA new对象时默认为0 当添加第一个元素的时候,数组扩容至10add方法源码:(jdk1.8与之不同,此处为jdk16)
//源码
public boolean add(E e) {
modCount++;//操作次数
add(e, elementData, size);
//e 操作对象; elementData 底层操作的数组;size 默认大小0
return true;
}
------------------------------------------------
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)//ture
elementData = grow();
elementData[s] = e; //存数据
size = s + 1; //最小需要长度
}
----------------------------------------------------------
private Object[] grow() {
return grow(size + 1);
}
-----------------------------------------------------
private Object[] grow(int minCapacity) { //初始传入为size+1 为1
int oldCapacity = elementData.length; //初始为0
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//if条件为初始数组长度>0或者数组不是无参构造构建的
int newCapacity = ArraysSupport.newLength(oldCapacity, //旧数组的长度
minCapacity - oldCapacity, /* minimum growth */
//最小需要长度-旧数组的长度 大于0代表空间不足
oldCapacity >> 1 /* preferred growth */);
//二进制位右移1位 位旧数组长度/2
return elementData = Arrays.copyOf(elementData, newCapacity);
将数据放入新数组中
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
//数组长度 DEFAULT_CAPACITY为10 此处代表无参构造默认长度为10
}
}
----------------------------------------------------
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
// assert oldLength >= 0
// assert minGrowth > 0
int newLength = Math.max(minGrowth, prefGrowth) + oldLength;
//如果prefGrowth>minGrowth 扩容1.5倍 minGrowth>prefGrowth为需要多少给多少
if (newLength - MAX_ARRAY_LENGTH <= 0) {
//MAX_ARRAY_LENGTH为int最大值 表示新数组长度如果小于int的最大值
return newLength;
}
return hugeLength(oldLength, minGrowth);
//返回int最大值
}
ArrayList集合底层是数组,怎么优化?
尽可能少的扩容。因为数组扩容效率比较低,建议在使用ArrayList集合 的时候预估计元素的个数,给定一个初始化容量。
数组优点:
检索效率比较高。(每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址,
然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高。)
数组缺点:
随机增删元素效率比较低。
另外数组无法存储大数据量。(很难找到一块非常巨大的连续的内存空间。)
向数组末尾添加元素,效率很高,不受影响。
4.4 -LinkedList实现原理
底层代码
属性:
transient int size = 0;//初始长度
transient Node<E> first;//头节点
transient Node<E> last;//尾节点add方法源码:(jdk1.8与之不同,此处为jdk16)
public boolean add(E e) {
linkLast(e);
return true;
}
--------------------------------------
void linkLast(E e) {
final Node<E> l = last; //初始为null
final Node<E> newNode = new Node<>(l, e, null);
//参数1:位上一个节点的内存地址,参数2:e为插入的数据,参数3:下一个节点的内存地址
last = newNode; // 最后节点为新节点
if (l == null) //如果newNode的前一个节点为null,则将新节点赋给first
first = newNode;
else
l.next = newNode; //尾节点下一个节点为新节点
size++;//大小
modCount++;//操作数
}4.5 -LinkedList和ArrayList
LinkedList和ArrayList方法一样,只是底层实现不一样。ArrayList底层为数组存储,LinkedList是以双向链表存储。LinkedList集合没有初始化容量。最初这个链表中没有任何元素。first和last引用都是null。
链表的优点: 由于链表上的元素在空间存储上内存地址不连续。 所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。 在以后的开发中,如果遇到随机增删集合中元素的业务比较多时,建议 使用LinkedList。 链表的缺点: 不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头 节点开始遍历,直到找到为止。所以LinkedList集合检索/查找的效率 较低。 ArrayList:把检索发挥到极致。(末尾添加元素效率还是很高的。) LinkedList:把随机增删发挥到极致。 加元素都是往末尾添加,所以ArrayList用的比LinkedList多。
4.6 -Vector
1、底层也是一个数组。
2、初始化容量:10
3、怎么扩容的?
扩容之后是原容量的2倍。
10--> 20 --> 40 --> 80
4、Vector中所有的方法都是线程同步的,都带有synchronized关键字,
是线程安全的。效率比较低,使用较少了。
5、怎么将一个线程不安全的ArrayList集合转换成线程安全的呢?
使用集合工具类:
java.util.Collections;
java.util.Collection 是集合接口。
java.util.Collections 是集合工具类。
Collections.synchronizedList();//将及格转换为线程安全的。
5 -Set
5.1 -概述
-
Set集合也是一个接口,继承自Collection,与List类似,都需要通过实现类来进行操作。
-
特点
-
不允许包含重复的值
-
没有索引(就不能使用普通的for循环进行遍历)
-
import java.util.HashSet;
import java.util.Set;
/**
* @author Mr.乐
* @Description Set集合
*/
public class Demo01 {
public static void main(String[] args) {
//使用多态,父类的引用指向子类对象
Set<String> set = new HashSet<>();
//添加元素
set.add("黄固");
set.add("欧阳锋");
set.add("段智兴");
set.add("洪七公");
set.add("段智兴");
System.out.println(set);//打印集合
//[洪七公, 黄固, 欧阳锋, 段智兴]
//HashSet集合对于元素的读写顺序不做保证
//相同的元素,多次存储,只能保留一个,并且不会报错
//List集合可以存储重复元素,Set集合不行
}
}
例:双色球
import java.util.Random;
import java.util.TreeSet;
/**
* @author Mr.乐
* @Description 双色球 -Set版
*/
public class Demo02 {
public static void main(String[] args) {
Random ran = new Random();//创建随机类对象
int blueBall = ran.nextInt(16) + 1;
// HashSet<Integer> redBalls = new HashSet<>();//创建集合用来存储红球
TreeSet<Object> redBalls = new TreeSet<>();//TreeSet集合自带排序规则
while (redBalls.size() < 6){
redBalls.add(ran.nextInt(33) + 1);//将当前生成的红球直接存进集合中
//因为Set集合不能存储重复的元素,所以去重的操作可以省略不做。
}
System.out.println("红球:" + redBalls + "篮球 [" + blueBall + "]");
}
}
5.2 -哈希值
Set集合的去重原理使用的是哈希值。
哈希值就是JDK根据对象地址 或者 字符串 或者数值 通过自己内部的计算出来的一个整数类型数据
public int hashCode()- 用来获取哈希值,来自于Object顶层类
对象的哈希值特点
同一个对象多次调用
hashCode()方法,得到的结果是相同的。默认情况下,不同的对象的哈希值也是不同的(特殊情况除外)
/**
* @author Mr.乐
* @Description 哈希值
*/
public class Demo03 {
public static void main(String[] args) {
//相同对象哈希值相同
System.out.println("张三".hashCode());//774889
System.out.println("张三".hashCode());//774889
//不同对象哈希值不同
System.out.println(new Object().hashCode());
System.out.println(new Object().hashCode());
//不同的对象的哈希值也有可能相同,例外情况
System.out.println("辂鹅".hashCode());//1179395
System.out.println("较鸦".hashCode());//1179395
System.out.println("辄鸇".hashCode());//1179395
System.out.println("辅鷨".hashCode());//1179395
}
}5.3 -HashSet去重原理
-
HashSet集合的特点
-
底层结构是“哈希表”
-
集合对于读写顺序不做保证
-
没有索引
-
Set集合中的内容不能重复
-
/**
* @author Mr.乐
* @Description HashSet去重原理
*/
public class Demo04 {
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
//添加元素
set.add(new Student("黄固",28));
set.add(new Student("欧阳锋",38));
set.add(new Student("段智兴",48));
set.add(new Student("洪七公",40));
set.add(new Student("段智兴",48));
//从程序的角度来考虑,两个段智兴不是同一个对象,都有自己的存储空间,所以哈希值也不一样。
for (Student stu : set) {
System.out.println(stu);
}
/*
重写hashcode和equals
Student{name='段智兴', age=48}
Student{name='欧阳锋', age=38}
Student{name='洪七公', age=40}
Student{name='黄固', age=28}
*/
}
}5.4 -LinkedHashSet
-
特点
-
LinkedHashSet是哈希表和链表实现的Set接口,具有可预测的读写顺序。
-
有链表来保证元素有序
-
有哈希表来保证元素的唯一性
-
/**
* @author Mr.乐
* @Description LinkedHashSet
*/
public class Demo05 {
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
//添加元素
set.add("黄固");
set.add("欧阳锋");
set.add("段智兴");
set.add("洪七公");
set.add("段智兴");//重复的元素不能存进去
System.out.println(set);//打印集合 [黄固, 欧阳锋, 段智兴, 洪七公]
}
}
5.5 -TreeSet
1、TreeSet集合底层实际上是一个TreeMap
2、TreeMap集合底层是一个二叉树。
3、放到TreeSet集合中的元素,等同于放到TreeMap集合key部分了。
4、TreeSet集合中的元素:无序不可重复,但是可以按照元素的大小顺序自动排序。
import java.util.TreeSet;
public class TreeSetTest02 {
public static void main(String[] args) {
// 创建一个TreeSet集合
TreeSet<String> ts = new TreeSet<>();
// 添加String
ts.add("zhangsan");
ts.add("lisi");
ts.add("wangwu");
ts.add("zhangsi");
ts.add("wangliu");
// 遍历
for(String s : ts){
// 按照字典顺序,升序!
System.out.println(s);
}
/*
lisi
wangliu
wangwu
zhangsan
zhangsi
*/
TreeSet<Integer> ts2 = new TreeSet<>();
ts2.add(100);
ts2.add(200);
ts2.add(900);
ts2.add(800);
ts2.add(600);
ts2.add(10);
for(Integer elt : ts2){
// 升序!
System.out.println(elt);
}
}
}5.5.1 -自定义排序规则
对于自定义的类无法排序,因为类中对象之间没有比较规则,不知道谁大谁小。
/**
* @author Mr.乐
* @Description 自定义比较器
*/
import java.util.TreeSet;
public class TreeSetTest04 {
public static void main(String[] args) {
Customer c1 = new Customer(32);
Customer c2 = new Customer(20);
Customer c3 = new Customer(30);
Customer c4 = new Customer(25);
// 创建TreeSet集合
TreeSet<Customer> customers = new TreeSet<>();
// 添加元素
customers.add(c1);
customers.add(c2);
customers.add(c3);
customers.add(c4);
// 遍历
for (Customer c : customers){
System.out.println(c);
}
}
}
// 放在TreeSet集合中的元素需要实现java.lang.Comparable接口。
// 并且实现compareTo方法。equals可以不写。
class Customer implements Comparable<Customer>{
int age;
public Customer(int age){
this.age = age;
}
// 需要在这个方法中编写比较的逻辑,或者说比较的规则,按照什么进行比较!
// k.compareTo(t.key)
// 拿着参数k和集合中的每一个k进行比较,返回值可能是>0 <0 =0
// 比较规则最终还是由程序员指定的:例如按照年龄升序。或者按照年龄降序。
@Override
public int compareTo(Customer c) { // c1.compareTo(c2);
return c.age - this.age;
}
public String toString(){
return "Customer[age="+age+"]";
}
}匿名内部类方式
public class TreeSetTest05 {
public static void main(String[] args) {
// TreeSet<Student> ts = new TreeSet<>();//默认排序规则
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int res = o1.getAge() - o2.getAge();
return 0 == res ? o1.getName().compareTo(o2.getName()) : res;
//三目运算符 等于零用姓名排序
}
});//默认排序规则
//添加元素
ts.add(new Student("Andy",19));
ts.add(new Student("Jack",18));
ts.add(new Student("Tom",21));
ts.add(new Student("Lucy",17));
ts.add(new Student("Bob",21)); //当年龄相同时,按照姓名的字典顺序排序
for (Student stu : ts) {
System.out.println(stu);
}
}
}
Comparable和Comparator怎么选择呢?
当比较规则不会发生改变的时候,或者说当比较规则只有1个的时候,建议实现Comparable接口。
如果比较规则有多个,并且需要多个比较规则之间频繁切换,建议使用Comparator接口。
6 -Map
6.1 -概述
双列集合:用来存储键值对的集合。
interface Map<K,V>: K(key)键 ,V(value)值将键映射到值的对象,不能出现重复的键,每个键最多可以映射到一个值
1、Map和Collection没有继承关系。
2、Map集合以key和value的方式存储数据:键值对
key和value都是引用数据类型。
key和value都是存储对象的内存地址。
key起到主导的地位,value是key的一个附属品。
例子:
| 学号(Key) | 姓名(Value) |
|---|---|
| STU001 | 张三 |
| STU002 | 李四 |
| STU003 | 张三 |
6.2 -Map的基本方法
| 方法名 | 说明 |
|---|---|
V put(K key,V value) | 设置键值对 |
V remove(Object key) | 删除元素 |
void clear() | 清空集合 |
boolean containsKey(Object key) | 判断键是否存在,存在则返回true |
boolean containsValue(Object value) | 判断值是否存在,存在则返回true |
boolean isEmpty() | 判断集合是否为空 |
int size() | 获取集合元素个数 |
import java.util.HashMap;
import java.util.Map;
/**
* @author Mr.乐
* @Description 集合的基本方法
*/
public class Map01 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("STU001","Andy");
map.put("STU002","Jack");
map.put("STU003","Tom");
map.put("STU004","Bob");
map.put("STU004","Smith");//设置(修改)
//如果键不存在,则表示添加元素。如果键存在,则表示设置值。
//删除
System.out.println(map.remove("STU003")); //Tom
//判断是否包含
System.out.println(map.containsKey("STU003")); //false
System.out.println(map.containsKey("STU004")); //true
System.out.println("-----------------------");
System.out.println(map.containsValue("Tom")); //false
System.out.println(map.containsValue("Smith")); //true
System.out.println("-----------------------");
System.out.println(map.isEmpty());//判断集合是否为空 false
map.clear();//清空集合
System.out.println(map.isEmpty()); //true
System.out.println(map); //{}
}
}
6.3 -Map集合的获取功能
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author Mr.乐
* @Description
*/
public class map_get {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("STU001","Andy");
map.put("STU002","Jack");
map.put("STU003","Tom");
map.put("STU004","Bob");
//get通过键获取值
System.out.println(map.get("STU003"));
System.out.println("------------------");
//keySet 获取所有键的Set集合
Set<String> keySet = map.keySet();
System.out.println(keySet);
//values 获取所有值的Collection集合
Collection<String> values = map.values();
System.out.println(values);
//entrySet 获取所有键值对对象的Set集合
Set<Map.Entry<String, String>> es = map.entrySet();
//Map集合通过entrySet()方法转换成的这个Set集合,Set集合中元素的类型是 Map.Entry<K,V>
//Map.Entry和String一样,都是一种类型的名字,只不过:Map.Entry是静态内部类,是Map中的静态内部类
System.out.println(es);
//[STU001=Andy, STU003=Tom, STU002=Jack, STU004=Bob]
for (Map.Entry<String, String> entry:es){
System.out.println("key:"+entry.getKey()+" "+"value:"+entry.getValue());
}
/*
key:STU001 value:Andy
key:STU003 value:Tom
key:STU002 value:Jack
key:STU004 value:Bob
*/
}
}6.4 -哈希表
通过 数组 + 链表 实现的一种数据结构
哈希表的构造方法的参数是一个长度为16个元素的数组,通过哈希值 % 16 的值,作为头节点在数组中选择对应的位置,就形成了哈希表。
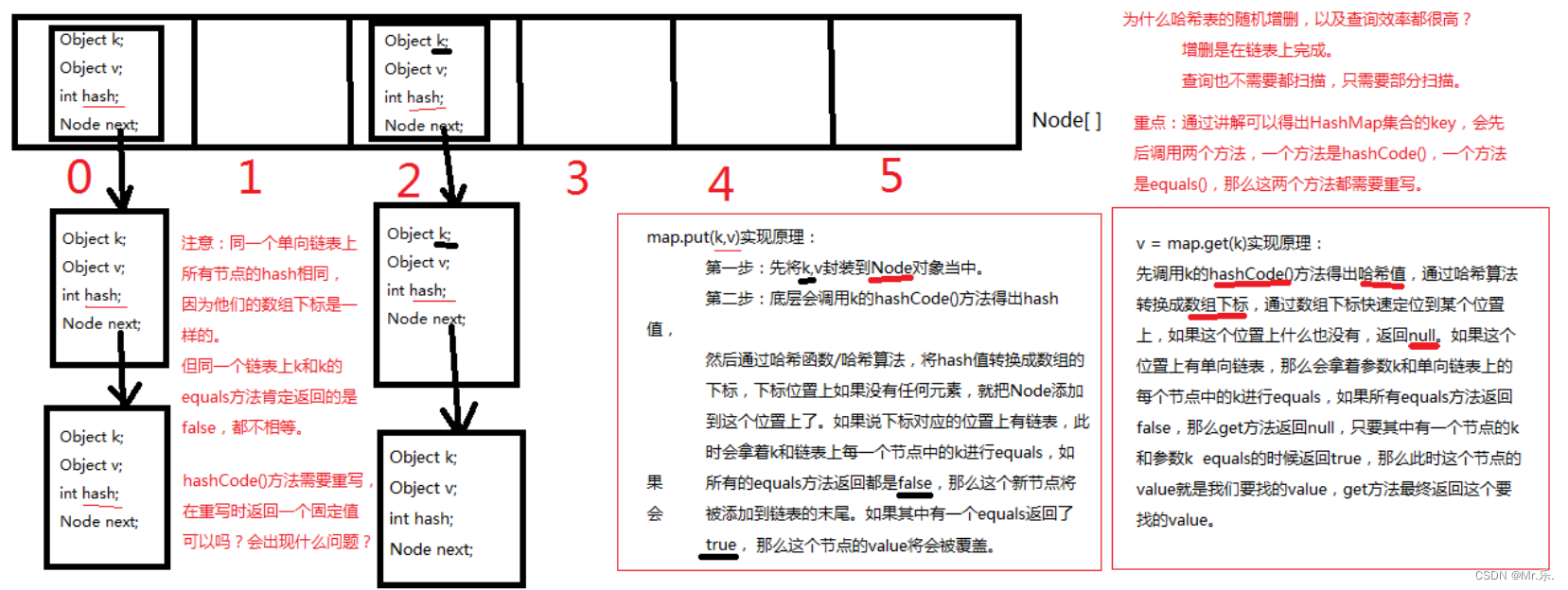 注:图转自动力节点。
注:图转自动力节点。
6.5 -HashMap
6.5.1 -底层源码
public class HashMap{
// HashMap底层实际上就是一个数组。(一维数组)
Node<K,V>[] table;
// 静态的内部类HashMap.Node
static class Node<K,V> {
final int hash; // 哈希值(哈希值是key的hashCode()方法的执行结果。hash值通过哈希函数/算法,可以转换存储成数组的下标。)
final K key; // 存储到Map集合中的那个key
V value; // 存储到Map集合中的那个value
Node<K,V> next; // 下一个节点的内存地址。
}
}6.5.2 -特点
1、无序,不可重复。 为什么无序? 因为不一定挂到哪个单向链表上。 不可重复是怎么保证的? equals方法来保证HashMap集合的key不可重复。 如果key重复了,value会覆盖。 2、放在HashMap集合key部分的元素其实就是放到HashSet集合中了。 所以HashSet集合中的元素也需要同时重写hashCode()+equals()方法。3、HashMap集合的默认初始化容量是16,默认加载因子是0.75 这个默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组以二叉树开始扩容。 重点,记住:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的, 这是因为达到散列均匀,为了提高HashMap集合的存取效率,所必须的。
6.5.3 -注意
1.向Map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法!
equals方法有可能调用,也有可能不调用。
拿put(k,v)举例,什么时候equals不会调用? k.hashCode()方法返回哈希值, 哈希值经过哈希算法转换成数组下标。 数组下标位置上如果是null,equals不需要执行。 拿get(k)举例,什么时候equals不会调用? k.hashCode()方法返回哈希值, 哈希值经过哈希算法转换成数组下标。 数组下标位置上如果是null,equals不需要执行。
4.假设将所有的hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成了 纯单向链表。
这种情况我们成为:散列分布不均匀。
什么是散列分布均匀?
假设有100个元素,10个单向链表,那么每个单向链表上有10个节点,这是最好的, 是散列分布均匀的。假设将所有的hashCode()方法返回值都设定为不一样的值,可以吗,有什么问题? 不行,因为这样的话导致底层哈希表就成为一维数组了,没有链表的概念了。 也是散列分布不均匀。散列分布均匀需要你重写hashCode()方法时有一定的技巧。
7 -Properties
Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型。 Properties被称为属性类对象。 Properties是线程安全的。
7.1 -方法
import java.io.IOException;
import java.util.Properties;
import java.util.Set;
/**
* @author Mr.乐
* @Description Properties特有方法
*/
public class Properties01 {
public static void main(String[] args) throws IOException {
Properties prop = new Properties();
final String SRC = "./myConf.ini";//定义配置信息存储路径
// mySave(prop,SRC);//存储配置文件
myLoad(prop,SRC);//加载配置文件信息
//PASSWORD<--->123456
//DATABASE<--->YX2115
//PORT<--->3306
//USERNAME<--->root
}
private static void myLoad(Properties prop, String src) throws IOException {
FileReader fr = new FileReader(src);
prop.load(fr);//通过流,加载指定路径的配置文件
fr.close();
//遍历
Set<String> keySet = prop.stringPropertyNames();//获取对象键的Set集合
for (String key : keySet) {
System.out.println(key + "<--->" + prop.getProperty(key));//通过键拿到值
}
}
private static void mySave(Properties prop, String src) throws IOException {
//将配置信息存储到对象中
prop.setProperty("USERNAME","root");
prop.setProperty("PASSWORD","123456");
prop.setProperty("DATABASE","YX2115");
prop.setProperty("PORT","3306");
//写入文件
FileWriter fw = new FileWriter(src);//创建输出流对象
prop.store(fw,"MyDataBase Configure!~");
fw.close();
}
}
8 -总结
本篇文章介绍了集合的常用方法以及个别集合的底层是如何实现的。介绍了集合的继承与实现结构。各个集合的扩容方式及扩容大小以及各个集合的优点和用途。希望大家可以根据本篇文章可以更加深刻的理解java中的集合。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
