首页 > 基础资料 博客日记
java查询数据库百万条数据,优化之:多线程+数据库
2023-12-14 21:28:20基础资料围观663次
Java资料网推荐java查询数据库百万条数据,优化之:多线程+数据库这篇文章给大家,欢迎收藏Java资料网享受知识的乐趣
java百万查询语句优化
业务需求
今天去面试时hr问了个关于大量数据查询的问题。
面试官:“我们公司是做数据分析的,每次需要从数据库中查询100万条数据进行分析,该接口不能用分页(不限制具体怎么实现),请问怎么优化sql或者java代码呢??”
如果用普通查询需要5分多分钟才查询完毕,所以我们用索引加多线程来实现。
那我们就开始吧!GO!!GO!!
数据库设计
编写数据库字段
然后要生成100万条数据
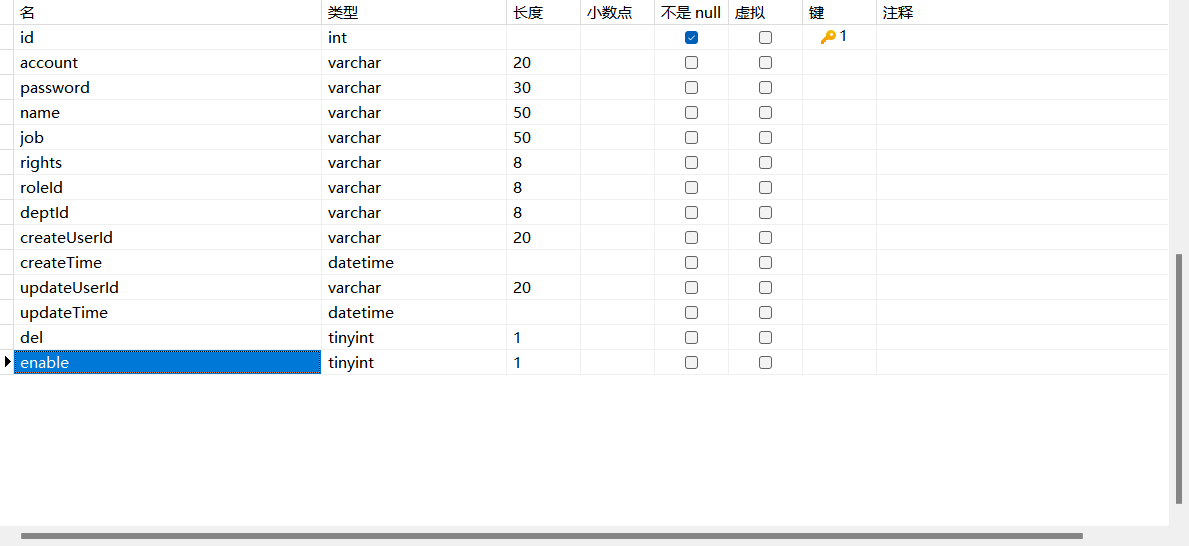
在数据库添加索引

索引这个方面我还是不太了解,大家懂的可以优化索引
代码实现
java编写
controller类编写
package com.neu.controller;
import com.neu.mapper.UserMapper;
import com.neu.pojo.User;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
import javax.annotation.Resource;
import java.util.*;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 用户查询多线程用户Controller
* @author 薄荷蓝柠
* @since 2023/6/6
*/
@Controller
public class ExecutorUtils {
@Resource
private UserMapper userMapper;
// 一个线程最大处理数据量
private static final int THREAD_COUNT_SIZE = 5000;
@RequestMapping("Executor")
public List<User> executeThreadPool() {
//计算表总数
Integer integer = userMapper.UserSum();
//记录开始时间
long start = System.currentTimeMillis();
//new个和表总数一样长的ArrayList
List<User> threadList=new ArrayList<>(integer);
// 线程数,以5000条数据为一个线程,总数据大小除以5000,再加1
int round = integer / THREAD_COUNT_SIZE + 1;
//new一个临时储存List的Map,以线程名为k,用做list排序
Map<Integer,ArrayList> temporaryMap = new HashMap<>(round);
// 程序计数器
final CountDownLatch count = new CountDownLatch(round);
// 创建线程
ExecutorService executor = Executors.newFixedThreadPool(round);
// 分配数据
for (int i = 0; i < round; i++) {
//该线程的查询开始值
int startLen = i * THREAD_COUNT_SIZE;
int k = i + 1;
executor.execute(new Runnable() {
@Override
public void run() {
ArrayList<User> users = userMapper.subList(startLen);
//把查出来的List放进临时Map
temporaryMap.put(k,users);
System.out.println("正在处理线程【" + k + "】的数据,数据大小为:" + users.size());
// 计数器 -1(唤醒阻塞线程)
count.countDown();
}
});
}
try {
// 阻塞线程(主线程等待所有子线程 一起执行业务)
count.await();
//结束时间
long end = System.currentTimeMillis();
System.out.println("100万数据查询耗时:" + (end - start) + "ms");
//通过循环遍历临时map,把map的值有序的放进List里
temporaryMap.keySet().forEach(k->{
threadList.addAll(temporaryMap.get(k));
});
} catch (Exception e) {
e.printStackTrace();
} finally {
//清除临时map,释放内存
temporaryMap.clear();
// 终止线程池
// 启动一次顺序关闭,执行以前提交的任务,但不接受新任务。若已经关闭,则调用没有其他作用。
executor.shutdown();
}
//输出list的长度
System.out.println("list长度为:"+threadList.size());
return threadList;
}
}
编写Mapper
package com.neu.mapper;
import java.util.ArrayList;
import java.util.List;
import org.apache.ibatis.annotations.*;
import com.neu.pojo.User;
/**
* 用户查询多线程用户Controller
* @author 薄荷蓝柠
* @since 2023/6/6
*/
@Mapper
public interface UserMapper {
/**
* 检索user表的长度
* @return 表长度
*/
@Select("SELECT count(id) as sum FROM sysuser")
Integer UserSum();
/**
* 检索user表的所有记录,
* SELECT * 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
* @return 所有记录信息
*/
@Select("select id,account,password,name,job,rights,roleId,createUserId,createTime,updateUserId,updateTime,del,enable from sysuser LIMIT #{startLen},5000")
ArrayList<User> subList(@Param("startLen") int startLen);
}
编写完成后我们测试一波–>
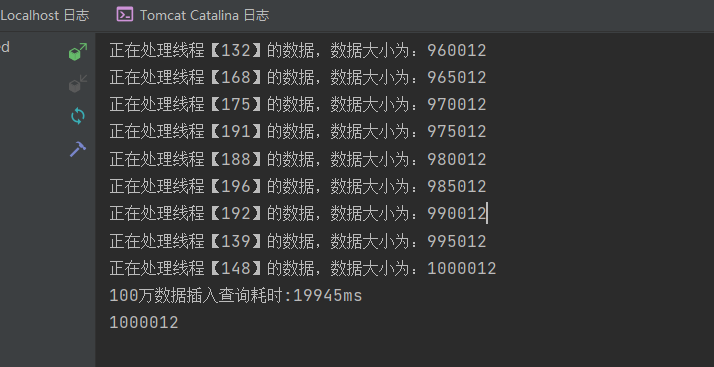
测试结果20秒内,比之前快了好多
模糊查询
模糊查询呢?
咱测试一下:
修改Mapper
package com.neu.mapper;
import java.util.ArrayList;
import java.util.List;
import org.apache.ibatis.annotations.*;
import com.neu.pojo.User;
/**
* 用户查询多线程用户Controller
* @author 薄荷蓝柠
* @since 2023/6/6
*/
@Mapper
public interface UserMapper {
/**
* 检索user表id包含有“0”的长度
* @return 表长度
*/
@Select("SELECT count(id) as sum FROM sysuser where id like concat('%',0,'%')")
Integer UserSum();
/**
* 检索user表id包含有“0”的所有记录
* SELECT * 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
* @return 所有记录信息
*/
@Select("select id,account,password,name,job,rights,roleId,createUserId,createTime,updateUserId,updateTime,del,enable from sysuser where id like concat('%',0,'%') LIMIT #{startLen},5000")
ArrayList<User> subList(@Param("startLen") int startLen);
}
修改完成后我们再测试一波–>

耗时5秒左右,可以满足业务需求
结束
目前基本的查询已经写完
看到这个文章的还可以对以下方面进行优化:
- 索引进行优化。
- 每个线程查询多少条数据最为合适??
- 如果配置有线程池可以使用:总条数/线程数==每个线程需要查询多少条数据。
- 进行代码优化,优化一些耗时的代码。
文章来源:https://blog.csdn.net/m0_57647880/article/details/131064291
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
