首页 > 基础资料 博客日记
Springboot集成kafka(环境搭建+演示)|超级详细,建议收藏
2023-09-03 17:51:01基础资料围观735次
Springboot集成kafka
一、前言🔥
上一期,我是带着大家入门了SpringBoot整合WebSocket,今天我再来一期kafka的零基础教学吧。不知道大家对kafka有多少了解,反正我就是从搭建开始,然后再加一个简单演示,这就算是带着大家了个门哈,剩下的我再后边慢慢出教程给大家说。
二、环境说明🔥
演示环境:idea2021 + springboot 2.3.1REALSE + CentOS7 + kafka
三、概念🔥
kafka是linkedin开源的分布式发布-订阅消息系统,目前归属于Apache的顶级项目。主要特点是基于pull模式来处理消息消费,追求高吞吐量,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统。
一开始的目的是日志的收集和传输。0.8版本开始支持复制,不支持事务,对消息的丢失,重复,错误没有严格要求 适用于产生大量数据的互联网服务的数据收集业务。在廉价的服务器上都能有很高的性能,这个主要是基于操作系统底层的pagecache,不用内存胜似使用内存。
综上所述,kafka是一款开源的消息引擎系统(消息队列/消息中间件) 分布式流处理平台
四、CentOS7安装kafka🔥
1.下载kafka安装包
下载地址:https://kafka.apache.org/downloads.html
CSDN:kafka_2.12-2.2.1.zip
2.下载好后,进行解压
通过ftp将kafka安装包kafka_2.11-0.9.0.1.tgz上传到服务器 /opt/monitor/kafka目录下
执行命令unzip kafka_2.12-2.2.1.zip 解压上传的kafka安装包
unzip kafka_2.12-2.2.1.zip
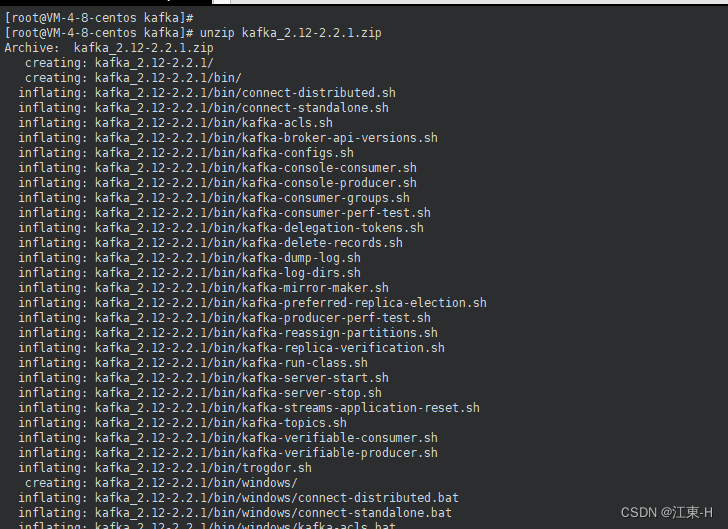
输入命令ll查询解压情况
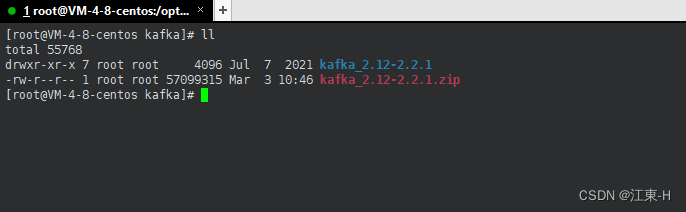
执行命令 cd /opt/monitor/kafka/kafka_2.12-2.2.1 进入kafka目录
cd /opt/monitor/kafka/kafka_2.12-2.2.1
1 配置并启动zookeeper
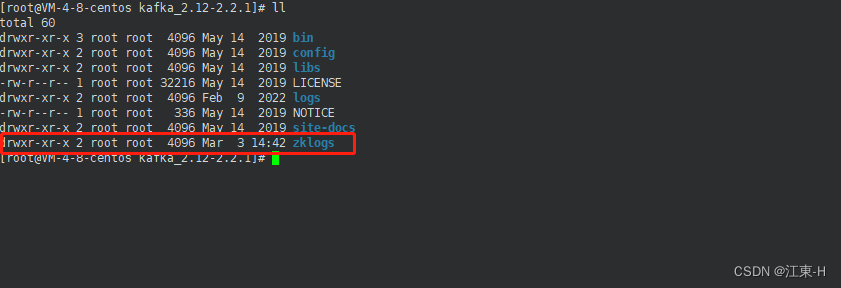
执行命令 创建zookeeper日志文件存放路径
mkdir zklogs
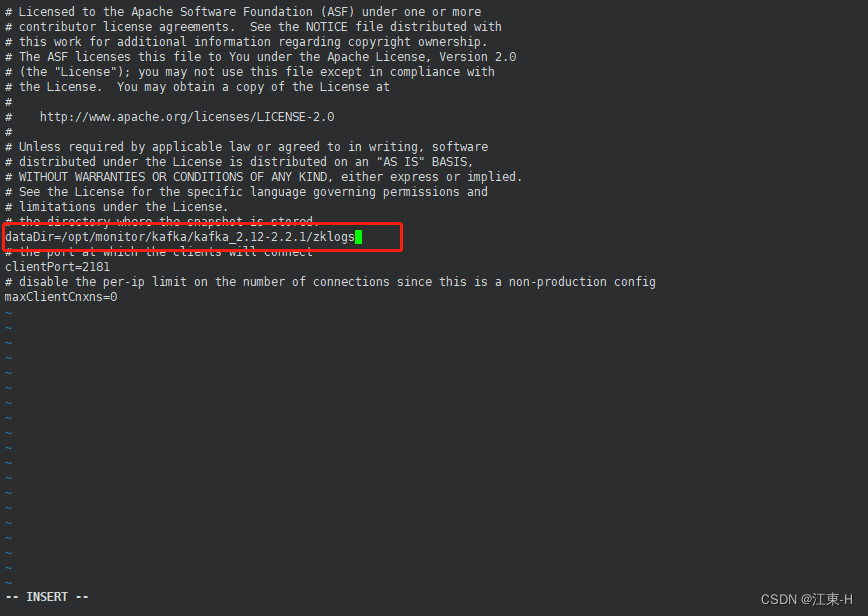
执行命令 修改zookeeper的配置信息
vim config/zookeeper.properties
按一下键盘上的 i 键进入编辑模式,将光标移动到日志文件存放路径配置信息所在行,并修改dataDir=/opt/monitor/kafka/kafka_2.12-2.2.1/zklogs
dataDir=/opt/monitor/kafka/kafka_2.12-2.2.1/zklogs
修改好后按下键盘上的Esc 键后 输入:wq 并按下Enter键保存修改的信息并退出,注意这里的:也是要输入的
执行sh./zookeeper-server-start.sh ./config/zookeeper.properties & 命令后台启动zookeeper

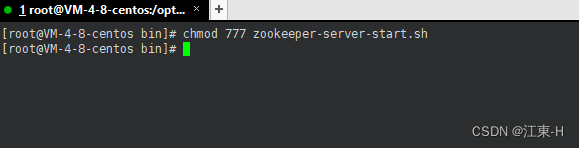
注意这里提示报错权限不足,使用命令修改权限(个人建议把bin的权限全部修改成777)
chmod 777 zookeeper-server-start.sh
显示没有报错启动zookeeper成功
sh ./zookeeper-server-start.sh /opt/monitor/kafka/kafka_2.12-2.2.1/config/zookeeper.properties
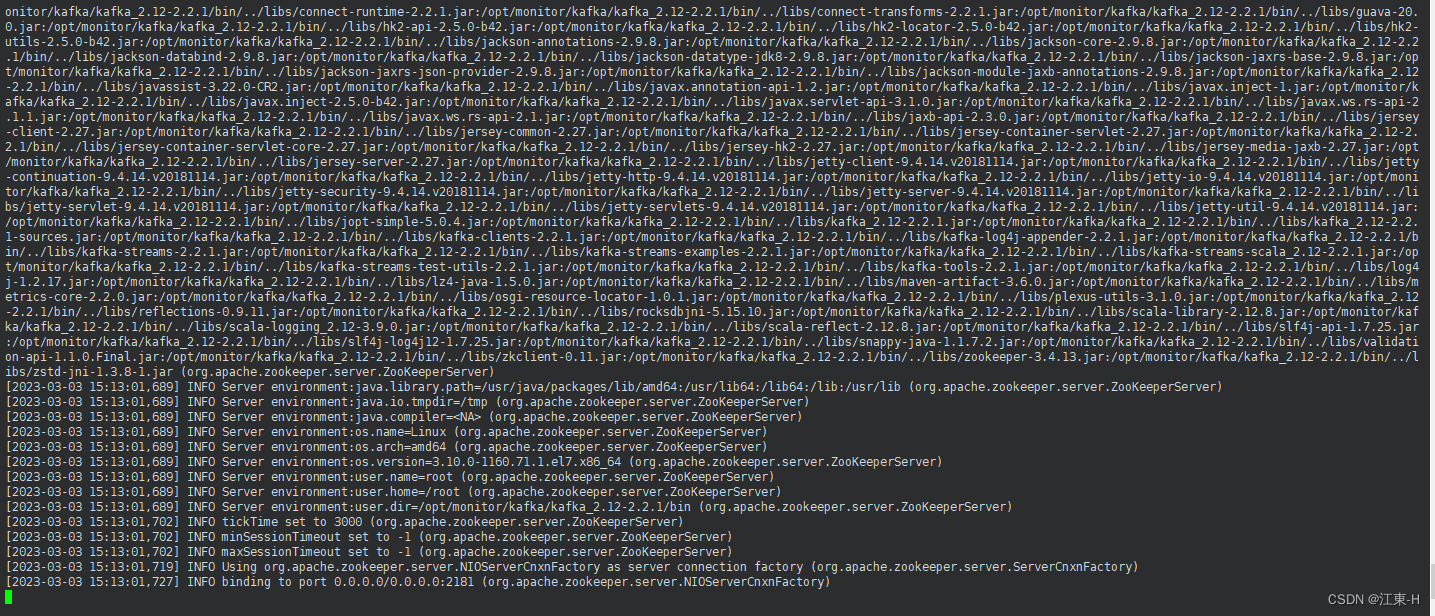
执行命令ps -ef | grep zookeeper 查看zookeeper是否启动成功,出现类型如下信息表示成功启动
2 配置并启动kafka
执行命令 vim config/server.properties 修改kafka的配置信息
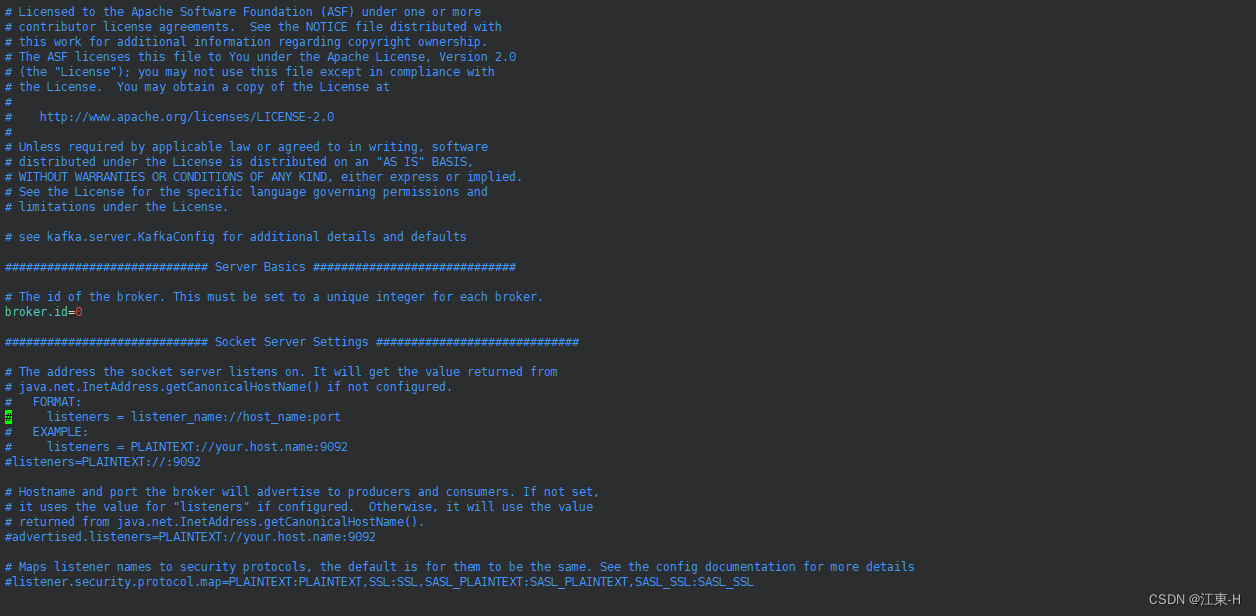
按一下键盘上的 i 键进入编辑模式,修改advertised.listeners=PLAINTEXT://外网IP:9092;
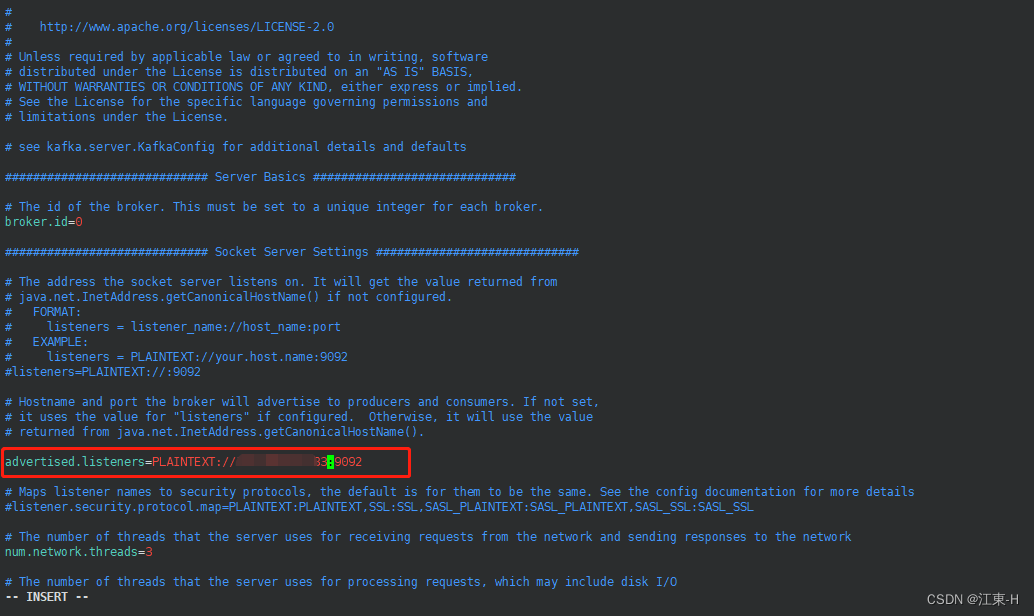
修改log.dirs=/opt/monitor/kafka/kafka_2.12-2.2.1/logs该参数为kafka日志文件存放路径
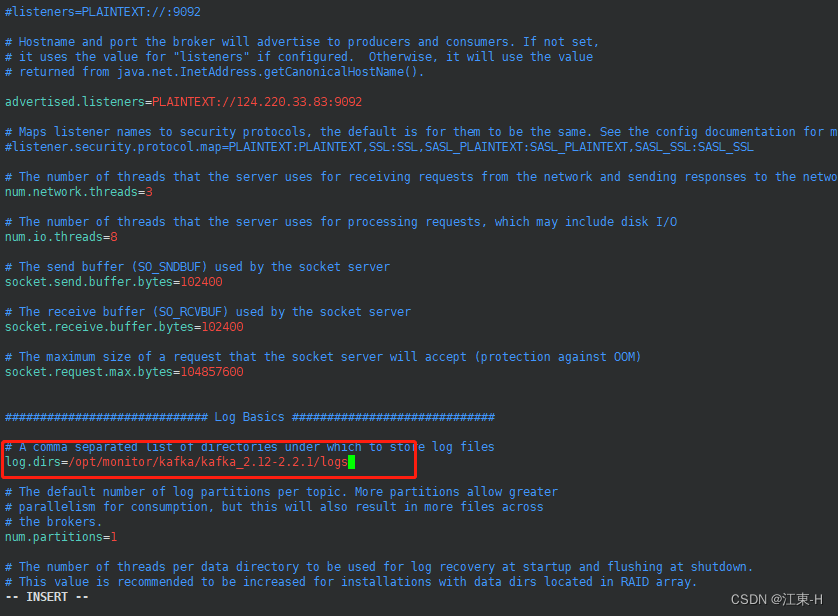
修改每个topic的默认分区参数num.partitions,默认是1,具体合适的取值需要根据服务器配置进程确定
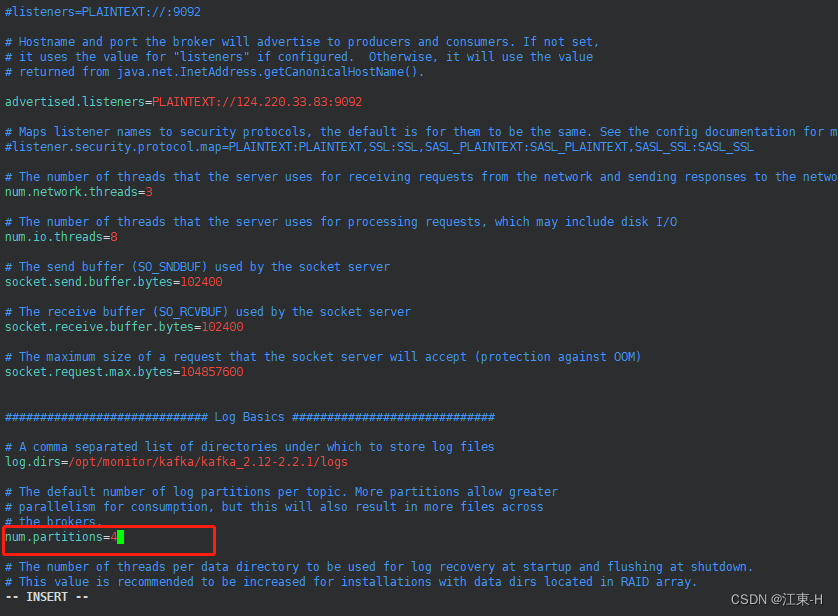
修改完成后按下键盘上的Esc 键后 输入:wq 并按下Enter键 保存修改的信息并退出,注意这里的:也是要输入的.
cd /opt/monitor/kafka/kafka_2.12-2.2.1/bin #进入kafka启动目录
sh kafka-server-start.sh /opt/monitor/kafka/kafka_2.12-2.2.1/config/server.properties #启动kafka服务指定配置文件
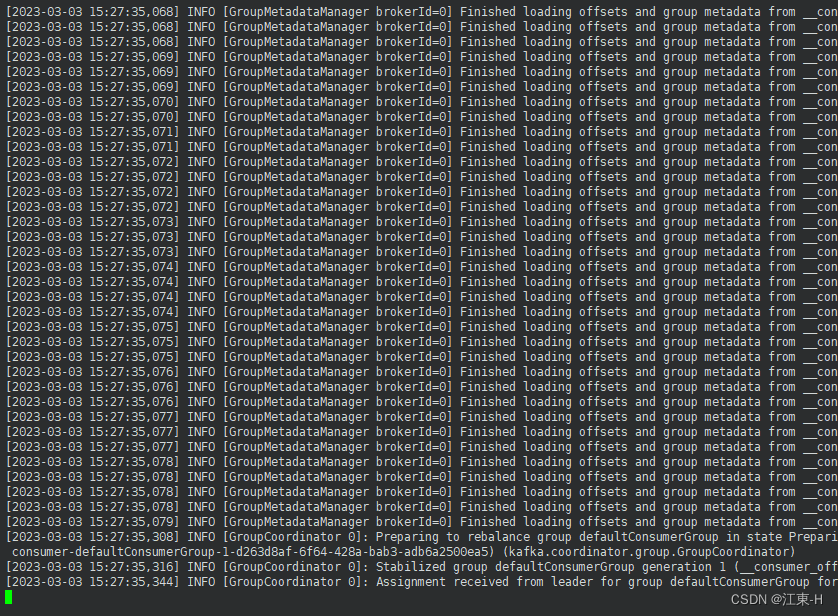
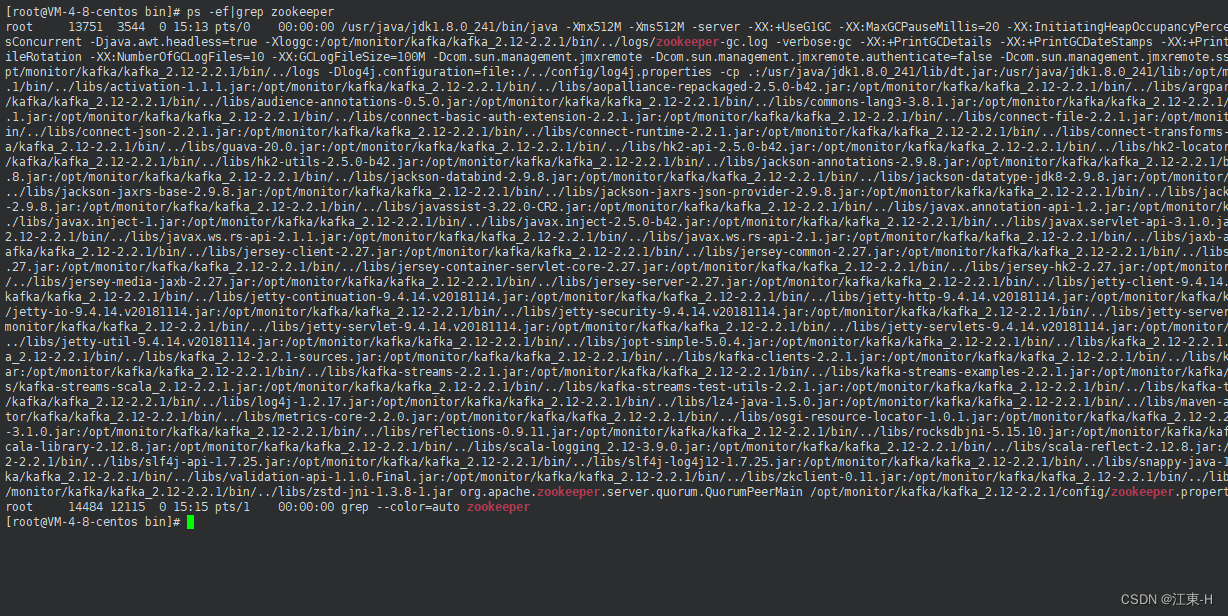
执行命令查看kafka是否启动成功
ps -ef | grep kafka #查看kafka是否启动成功
六、kafka项目集成🔥
1️⃣pom引入
<!--kafka依赖-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2️⃣配置kafka
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
profiles:
active: dev
server:
port: 8070
3️⃣一个kafka消息发送端
package com.suihao.kafka;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* @author suihao
* @Title: KafkaProducer
* @Description TODO
* @date: 2023/03/03 17:
* @version: V1.0
*/
@Component
@Slf4j
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
//自定义topic
public static final String TOPIC_TEST = "topic.test";
//
public static final String TOPIC_GROUP1 = "topic.group1";
//
public static final String TOPIC_GROUP2 = "topic.group2";
public void send(Object obj) {
String obj2String = JSONUtil.toJsonStr(obj);
log.info("准备发送消息为:{}", obj2String);
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
//发送失败的处理
log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
//成功的处理
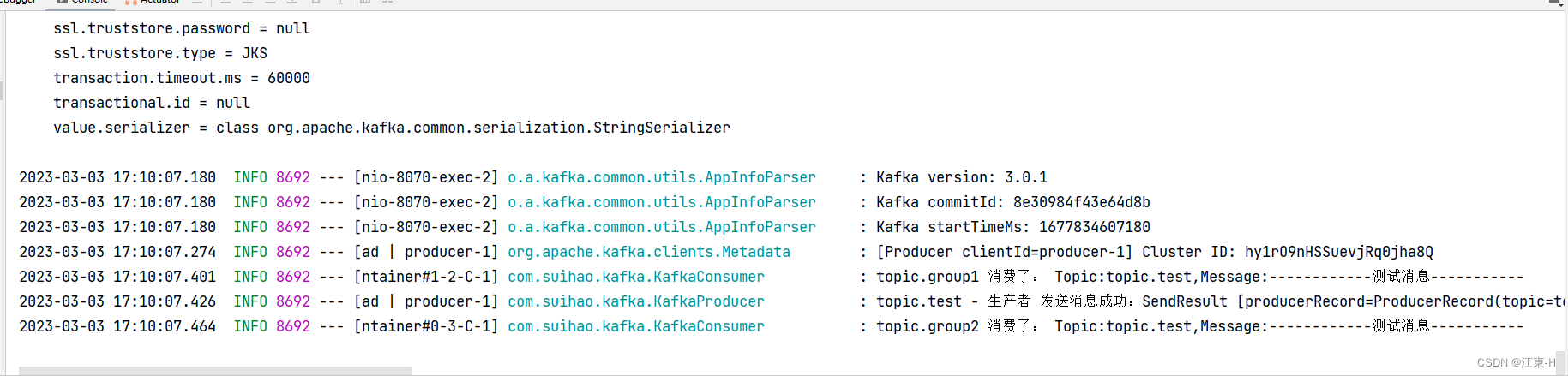
log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());
}
});
}
}
4️⃣定义一个kafka消息消费端
package com.suihao.kafka;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
* @author suihao
* @Title: KafkaConsumer
* @Description TODO
* @date: 2023/03/03 17:
* @version: V1.0
*/
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = KafkaProducer.TOPIC_TEST, groupId = KafkaProducer.TOPIC_GROUP1)
public void topic_test(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
log.info("topic.group1 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
@KafkaListener(topics = KafkaProducer.TOPIC_TEST, groupId = KafkaProducer.TOPIC_GROUP2)
public void topic_test1(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
log.info("topic.group2 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
5️⃣定义一个Controller进行测试
package com.suihao.controller;
import com.suihao.kafka.KafkaProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author suihao
* @Title: KafkaController
* @Description TODO
* @date: 2023/03/03 17:
* @version: V1.0
*/
@RestController
public class KafkaController {
@Autowired
private KafkaProducer kafkaProducer;
@GetMapping("/send")
public void sendMsg(){
kafkaProducer.send("------------测试消息-----------");
}
}
6️⃣测试结果如下
彩蛋: https://gitee.com/suihao666/SpringBoot-Kafka
最后送所有正在努力的大家一句话:
你不一定逆风翻盘,但一定要向阳而生。
期待下次发布好的文章:
山水相逢,我们江湖见。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
