首页 > 基础资料 博客日记
【C++学习】线程库 | IO流 | 空间配置器
2023-07-24 16:42:24基础资料围观640次
🐱作者:一只大喵咪1201
🐱专栏:《C++学习》
🔥格言:你只管努力,剩下的交给时间!

目录
一、线程库
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差。
C++11中最重要的特性就是支持了多线程编程,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。
1.1 thread
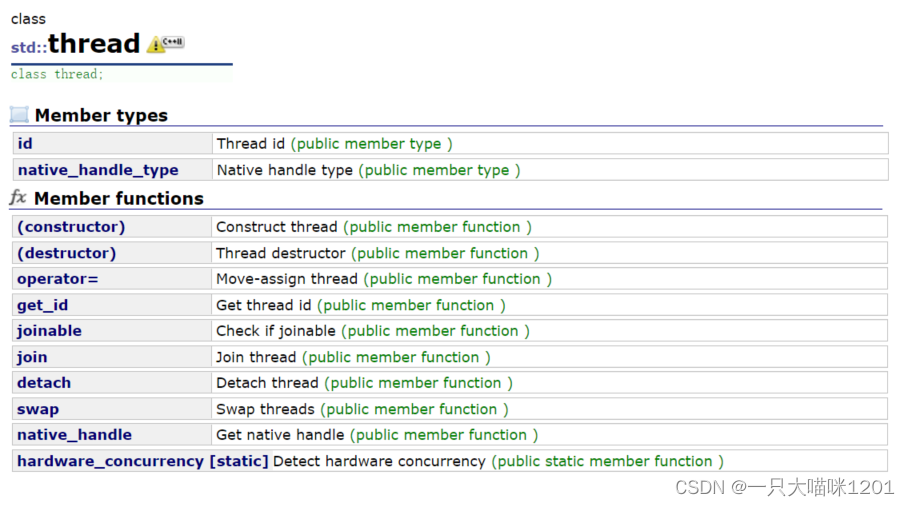
如上图所示,C++11提供了thread库,thread是一个类,在使用的时候需要包含头文件pthread。
构造函数:

- 默认构造函数
thread()
使用该构造函数创建的线程对象仅是创建对象,从线程并没有被创建,也没有允许。
thread(Fn&& fn, Args&&... args),这是一个万能引用模板。
使用该构造函数时,第一个参数是可调用对象,可以是左值也可以是右值,比如函数指针,仿函数对象,lambda表达式等等。
后面的可变参数就是传给线程函数的实参,是一个参数包,也就是可变参数。
thread(const thread&) = delete,线程之间是禁止拷贝的。thread(thread&& x),移动构造函数。
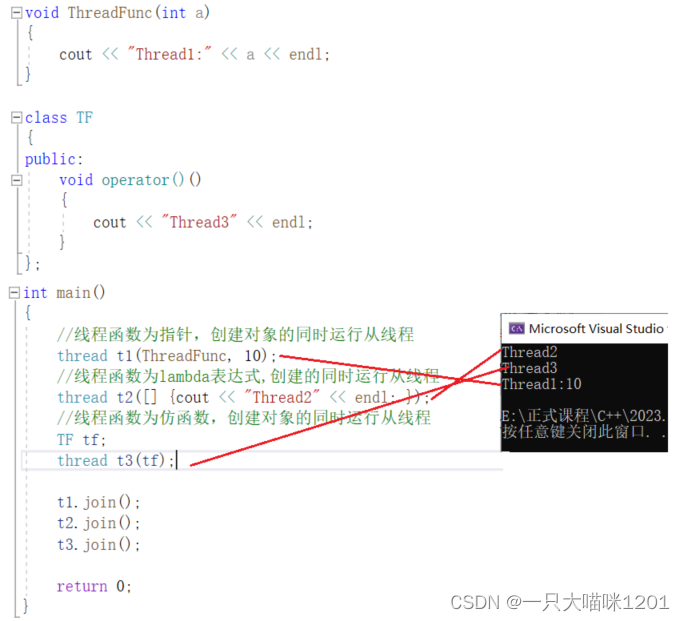
- 上图中代码创建了3个新线程,加上主线程一共四个线程,并且它们同时运行。
- 但是具体是哪个从线程先启动是由操作系统的调度器决定的,此时我们看到的是先执行的线程2,再执行线程3,再执行线程1,和代码顺序并不相同。
其成员函数:
-
get_id,用来获取当前线程的tid值。
调用该函数通常都是当前线程,但是当前的从线程从并没有自己的thread对象。
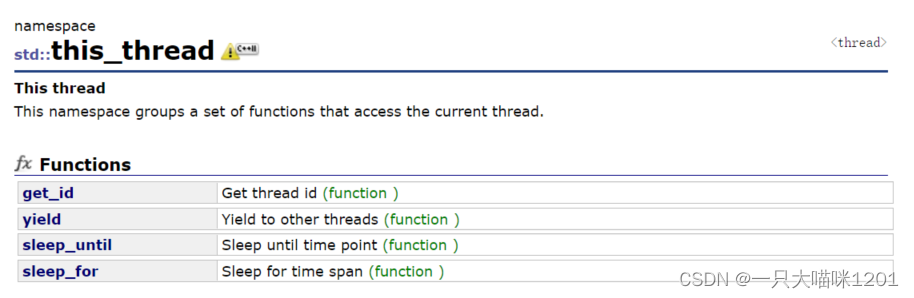
所以线程库由提供了一个命名空间,该空间中有上图所示的几个函数,可以通过命名空间来直接调用,如:
this_thread::get_id();//获取当前线程tid值
哪个线程执行这条语句就返回哪个线程的tid值,命名空间中的其他几个函数的用法也是这样。
yield调用该接口的线程会让其CPU,让CPU调度其他线程。sleep_until调用该接口的线程会延时至一个确定的时间点。sleep_for调用该接口的线程会延时一个时间段,如1s。
-
operator=(thread&& t),移动赋值。

将一个线程对象赋值给另一个线程对象,通常用在:
thread t1;//仅创建对象,不创建线程
t1 = thread(func);//t1线程函数并且执行
此时原本只创建的线程对象就有一个线程在跑了。
注意:只能赋右值,不能赋左值,因为赋值运算符重载被禁掉了,只有移动赋值。
-
join,线程等待,用来回收线程资源。
一般主线程会调用该函数,以t.join()的形式,t就是需要被等待的线程对象,此时主线程会阻塞在这里,直到从线程运行结束。
如上图中的多线程一样,必须使用join,否则线程资源不会回收,而且如果从线程运行的时间比主线程长的话,主线程会直接运行完并且回收所有资源,导致从线程被强制结束。
-
joinable,用来判断线程是否有效。
如果是以下任意情况则线程无效:
- 采用无参构造函数构造的线程对象
- 线程对象的状态已经转移给其他线程对象
- 线程已经调用join或者detach结束
detach,线程分离,从线程结束后自动回收资源。
其他的就不介绍了,用到的时候自行查文档即可。
要谨记:thread是禁止拷贝的,不允许拷贝构造以及赋值,但是可以移动构造和移动赋值。
1.2 mutex

如上图所示,C++11提供了mutex库,mutex同样是一个类,在使用的时候要包含头文件mutex。
构造函数:
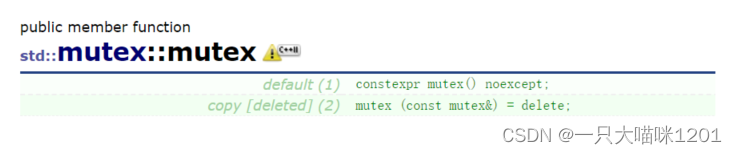
- 只有默认构造函数
mutex(),在创建互斥锁的时候不需要传任何参数。 mutex(const mutex&)=delete,禁止拷贝。
其他成员函数:
lock(),给临界区加锁,加锁成功继续向下执行,失败则阻塞等待。unlock(),给临界区解锁。try_lock(),给临界区尝试加锁,加锁成功返回true,加锁失败返回false。
使用try_lock时,如果申请失败则不阻塞,跳过申请锁的部分,执行非临界区代码。
来看伪代码:
mutex mtx;
if(mtx.try_lock())
{
//临界区代码
//......
}
else
{
//非临界区代码
//......
}
mutex不能递归使用,如下面伪代码所示:
void Func(int n)
{
lock();//加锁
//临界区代码
//......
Func(n - 1);//递归调用
unlock();//解锁
}
在递归中不能使用这样的锁,这样会造成死锁。
其他种类的锁:
recursive_mutex递归锁,在递归情况中使用这个锁。timed_mutex定时锁,如果不主动解锁,设定的时间到了后自定解锁。recursive_timed_mutex,递归调用定时锁。
RAII锁

lock_guard是一个类,采用了RAII方式来加锁解锁——将锁的生命周期和对象的生命周期绑定在一起。
构造函数:

lock_guard(mutex_type& m),在创建这个对象的时候需要传入一把锁,在构造函数中,进行了加锁操作。lcok_guard(const lock_guard&)=delete,该对象禁止拷贝,因为互斥锁就不可以拷贝。
析构函数的作用就是将lock_guard对象的资源释放,也就是进行解锁操作。
lock_guard只有构造函数和析构函数,使用该类对象加锁时不需要我们去关心锁的释放,但是它不能在对象生命周期结束之前主动解锁。
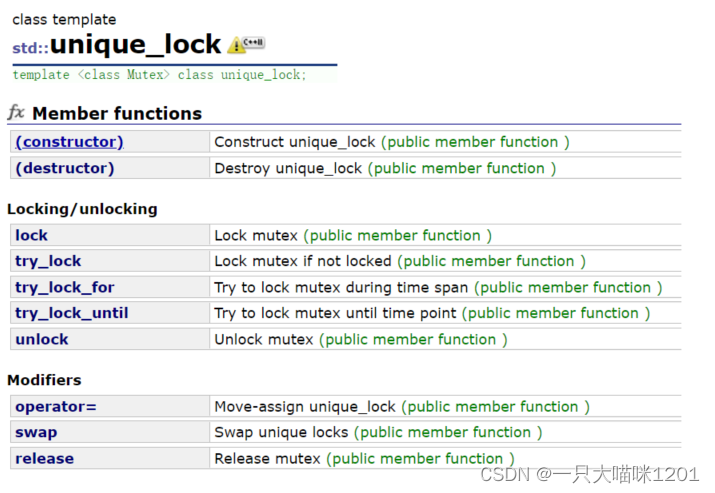
unique_lock也是一种RAII的加锁对象,它和lock_guard的功能一样,将锁的生命周期和对象的生命周期绑定在一起,但是又有区别。
构造函数:

可以看到,它的构造函数重载了很多,所以使用的方式也有很多,但是我们常用的就只有几个。
unique_lock(mutex_type& m),这个和lock_guard的用法一样,在构造函数中加锁。unique_lock(const unique_lock&)=delete,同样禁止拷贝。
析构函数中和lock_guard一样,也是进行解锁操作。
其他成员函数:
lock,加锁。unlock,解锁。try_lock,尝试加锁。
在lock_guard中就没有这几个接口,所以unique_lock可以在析构之前主动解锁,主动解锁后仍然可以再主动加锁,这一点lock_guard是不可以的。
try_lock_for,尝试加锁一段时间,时间到后自动解锁。try_lock_until,尝试加锁到指定时间,时间到来后自动解锁。
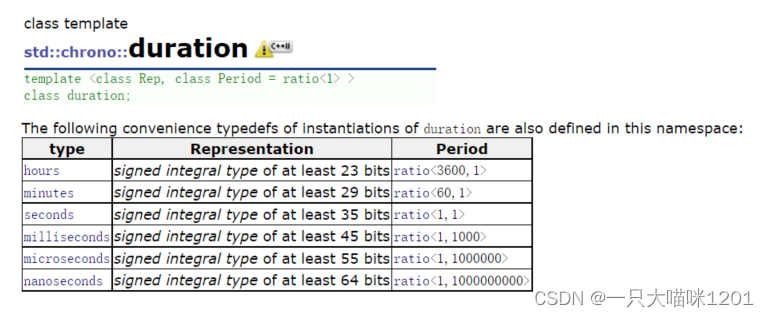
加锁的时间可以通过命名空间chrono中的duration类模板来设定。
#include <chrono>
chrono::duration<int, milli> ms(60*60*24);//86400000ms
用法很多,需要使用的时候可以结合库文档来使用。
1.3 atomic
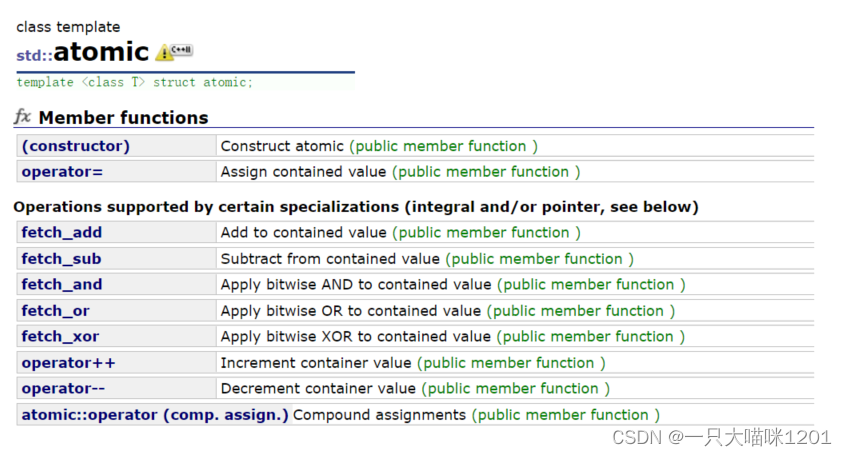
C++11提供了原子操作,我们知道,线程不安全的主要原因就是访问某些公共资源的时候,操作不是原子的,如果让这些操作变成原子的后,就不会存在线程安全问题了。
CAS原理:
原子操作的原理就是CAS(compare and swap)。
- CAS包含三个操作数:内存位置(V),预期原值(A)和新值(B)。
- 如果内存位置的值与预期原值相等,那么处理器就会自定将该位置的值更新为新值。
- 如果内存位置的值与预期原值不相等,那么处理器不会做任何操作。
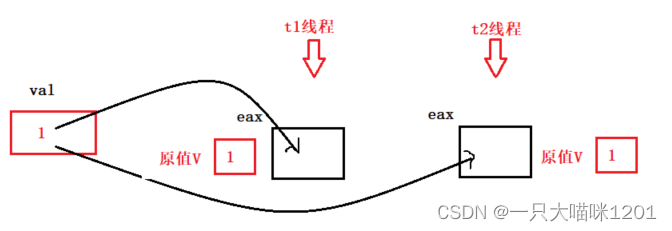
val是临界资源,两个线程t1和t2同时对这个值进行加加操作,每个线程都是将该值先拿到寄存器eax中。
- 线程将
val值拿到寄存器eax中时,同时将该值放入原值V中。 - 在修改
val值之前,CPU会先判断eax中的值与原值V中的值是否相等,如果相等则修改并且更新值,如果不相等则不修改。
伪代码原理:
while(1)
{
eax = val;//将val值取到寄存器eax中
if(eax = V)//和原值相同可以修改
{
eax++;
V = eax;//修改原值
val = eax;//修改val值
break;//访问结束,跳出循环
}
}
- t1和t2虽然同时运行,但是时间粒度划分到极小的时候,CPU仍然是一个个在执行。
t1线程将val值拿到寄存器中,并且赋原值,经过判断发现和原值相同,所以修改val值,并放回到val的地址中。
此时t2线程被唤醒,它将val值拿到寄存器中后与最开始的原值V相比,发现不相同了,所以就不进行修改,而且继续循环,知道寄存器中的值和原值相等才会改变。
- 原子操作虽然保证了线程安全,但是另一个无法写的的线程会不停的循环,而这也会占用一定的CPU资源。
CAS具体的原理有兴趣的小伙伴可以自行下去了解。
构造函数:

atomic也是一个类,所以也有构造函数。
- 经常使用的是
atomic(T val),在创建的时候传入我们想要进行原子操作的变量。
int a = atomic(1);
此时变量a的操作就都成了原子操作了,在多线程访问的时候可以保证线程安全。
成员函数:

该类重载了++,–等运算符,可以直接对变量进行操作。
++a;
--a;
1.4 condition_variable

C++11中同样也有条件变量,用来实现线程的同步。
构造函数:

- 在创建条件变量的时候不用传入参数,同样是不允许被拷贝的。
其他成员函数:
放入等待队列:

wait(unique_lock<mutex>& lock),该接口是将调用它的线程放入到条件变量的等待队列中。wait(unique_lock<mutex>& lck, Predicate pred),该接口和上面的作用一样,只是多了一个pred参数,当这个参数为true的话不放入等待队列,为false时放入等待队列。- 这里传入的锁是
unique_lock而不是lock_guard。
这是因为,当一个线程申请到锁进入临界区,但是条件不满足被放入条件变量的等待队列中时,会将申请到的锁释放。
lock_guard只能在对象生命周期结束时自动释放锁。unique_lock可以在任意位置释放锁。
如果使用了lock_guard的话就无法在进入等待队列的时候释放锁了。
wait_for和wait_until都是等待指定时间,一个是在等待队列中待指定时间,另一个是在等待队列中带到固定的时间点后自定唤醒。
唤醒等待队列中的线程:

notify_one唤醒等待队列中的一个线程,notify_all唤醒等待队列中的所有线程。
1.5 线程库的使用
- 写一个程序:支持两个线程交替打印,一个打印奇数,一个打印偶数。
分析:
- 首先创建一个全局的变量
val,让两个线程去访问该变量并且进行加一操作。 - 考虑到线程安全,所以需要给对应的临界区加互斥锁
mutex - 又是交替打印,所以要使用条件变量
condition_variable来控制顺序,为了方便管理,使用的锁是unique_lock<mutex>。
代码实现:
int val = 0;//全局变量
int main()
{
mutex mtx;//创建互斥锁
condition_variable cond;//创建条件变量
int n = 100;//打印值的范围
//打印奇数线程
thread t1([&] {
while (val < n)
{
unique_lock<mutex> lock(mtx);//加锁
while (val % 2 == 0)//判断是否是偶数
{
//是偶数则放入等待队列中等待
cond.wait(lock);
}
//是奇数时打印
cout << "thread1:" << this_thread::get_id() << "->" << val++ << endl;
cond.notify_one();//唤醒等待队列中的一个线程去打印偶数
}
});
//打印偶数线程
thread t2([&] {
while (val <= n)
{
unique_lock<mutex> lock(mtx);//加锁
while (val % 2 == 1)//判断是否是奇数
{
//是奇数放入等待队列中
cond.wait(lock);
}
//是偶数时打印
cout << "thread2:" << this_thread::get_id() << "->" << val++ << endl;
cond.notify_one();//唤醒等待队列中的一个线程去打印奇数
}
});
//阻塞等待两个从线程
t1.join();
t2.join();
return 0;
}
上面代码两个线程执行的函数对象是lambda表达式,所以创建线程对象时,调用的是移动构造函数。
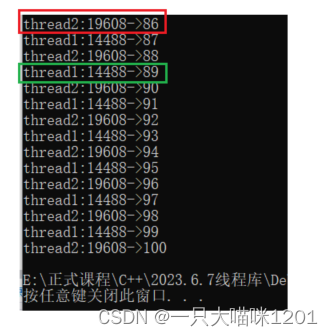
- 线程t1负责打印奇数,t2负责打印偶数,两个线程通过条件变量的控制交替打印。
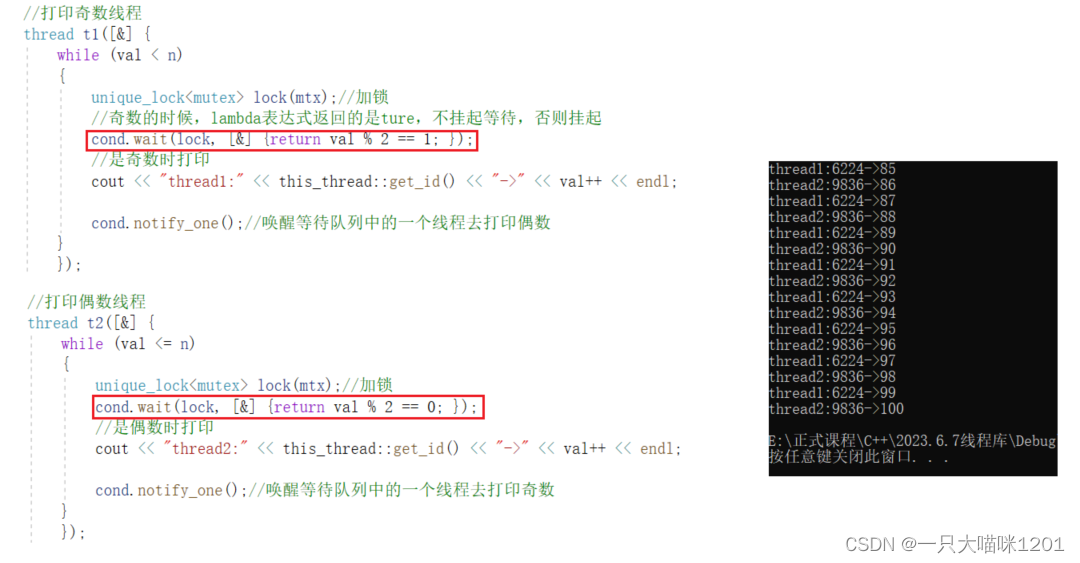
是用上图红色框中的代码仍然可以实现交替打印的功能。
wait()的第二个参数是false的时候,该线程被挂起到等待队列中,是true的时候不挂起,而且执行向下执行。- 第二个参数的
false和true可以是返回值,如上图代码就是使用的lambda表达式的返回值。
二、IO流
- 流是什么:“流”即是流动的意思,是物质从一处向另一处流动的过程,是对一种有序连续且具有方向性的数据( 其单位可以是bit,byte,packet )的抽象描述。
C++流是指信息从外部输入设备(如键盘)向计算机内部(如内存)输入和从内存向外部输出设备(显示器)输出的过程。这种输入输出的过程被形象的比喻为“流”。
它的特点:有序连续、具有方向性。
C++定义了I/O标准类库来实现这种流动,这些每个类都称为流/流类,用以完成某种特定的功能:
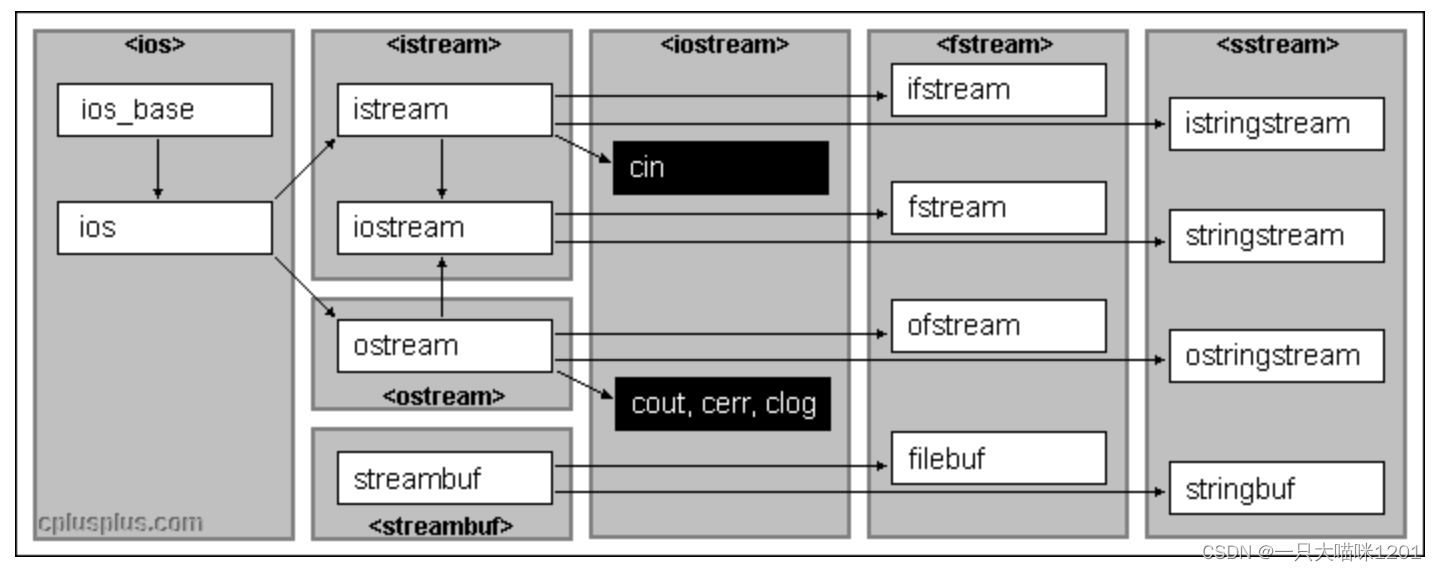
C++系统实现了一个庞大的类库,其中ios是基类,其他类都是直接或者间接继承自ios类。
2.1 标准IO流
iostream类也叫做标准IO流,根据上面IO库可以看到,iostream是同时继承了istream标准输入和ostream标准输出。
标准输入:
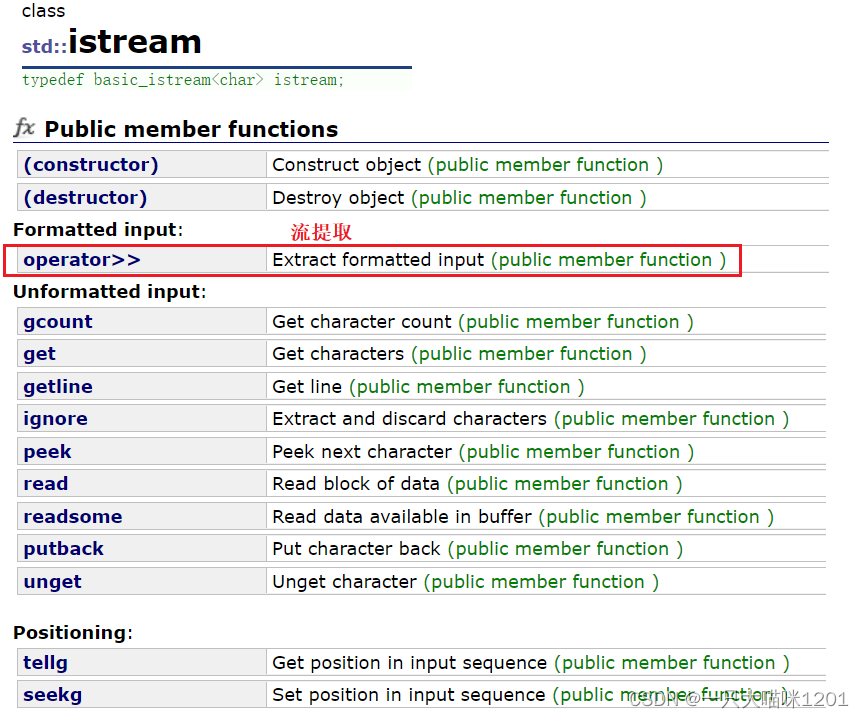
对于标准输入,只要包含了C++的IO库,就会有一个全局的istream对象cin,用来从IO流中将数据提取到内存中的指定位置。
而为了能实现数据从标准外设到内存的流动,重载了>>运算符,如上图红色框中所示函数operator>>,这个运算符也形象的表示了数据流动的方向,是向右流动的。
int a;
cin >> a;
如上面代码所示,数据从cin对象流到了变量a中,其中cin这个全局对象就代表标准输入(如键盘)。
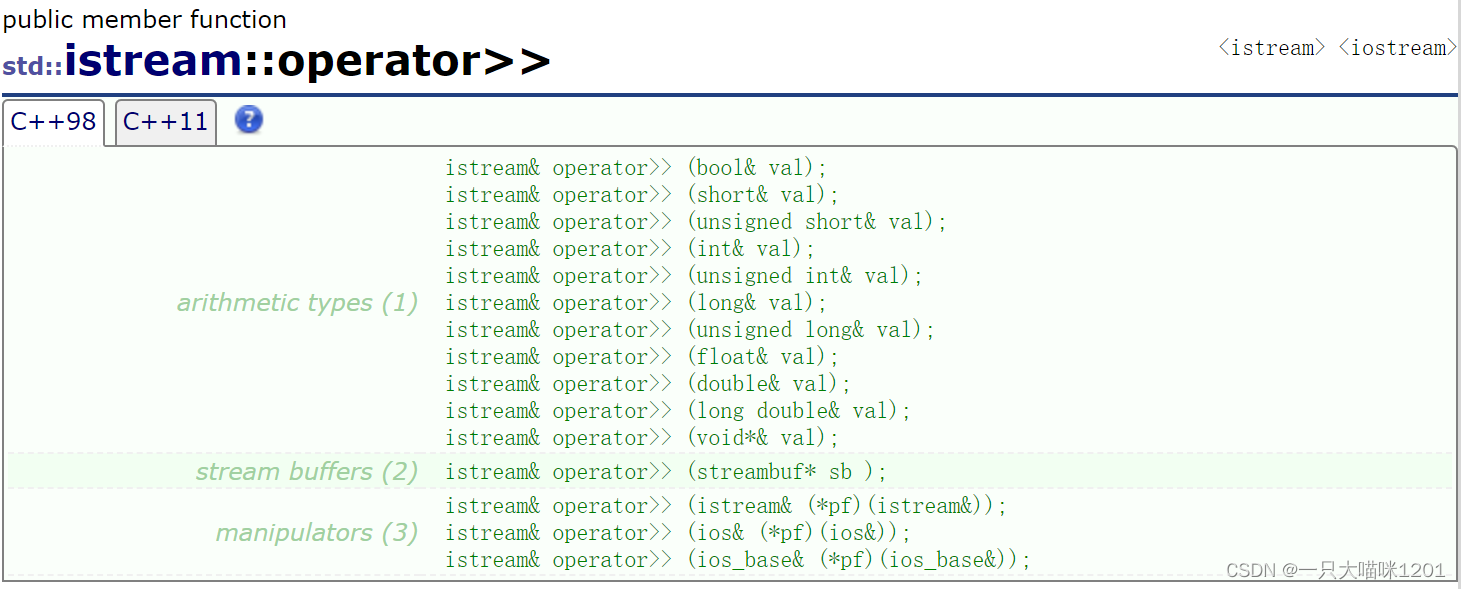
从operator>>的成员函数定义中,可以看到,所有的内置类型都进行了重载,这个工作是由C++IO库来完成的,我们可以直接使用。
而对于内置类型需要我们自己来实现>>的重载,拿日期类来举例:
class Date
{
friend istream& operator>>(istream& in, Date& d);
public:
Date(int year = 1970, int month = 1, int day = 1)
:_year(year)
,_month(month)
,_day(day)
{}
private:
int _year;
int _month;
int _day;
};
//流提取运算符重载
istream& operator>>(istream& in, Date& d)
{
in >> d._year >> d._month >> d._day;
return in;
}
针对自定义类型Date,重载流提取>>运算符,此时直接从标准输入向Date类对象中写入数据了。
- 流提取运算符是在
Date类外重载的,所以需要进行友元friend声明,否则无法直接向private成员中写入数据。- 如果是重载为成员函数,那么调用方就成了
Date对象,如d>>cin,此时流向的对象就在前面了,和常规情况相差较大。
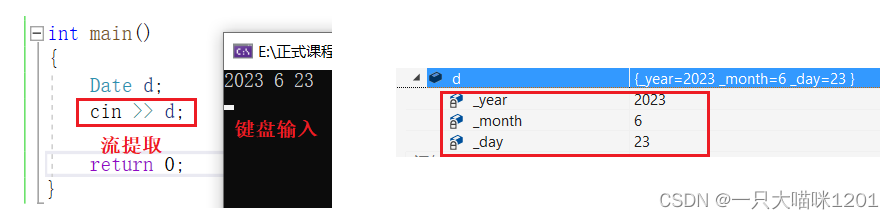
此时进行流提取的时候,从键盘上输入的内容成功写入到了Date对象中。
注意:
- cin为缓冲流。键盘输入的数据保存在缓冲区中,当要提取时,是从缓冲区中拿。如果一次输入过多,会留在那儿慢慢用,如果输入错了,必须在回车之前修改,如果回车键按下就无法挽回了。只有把输入缓冲区中的数据取完后,才要求输入新的数据。
- 输入的数据类型必须与要提取的数据类型一致,否则出错。出错只是在流的状态字state中对应位置位(置1),程序继续。
- 空格和回车都可以作为数据之间的分格符,所以多个数据可以在一行输入,也可以分行输入。但如果是字符型和字符串,则空格(ASCII码32)无法用cin输入,字符串中也不能有空格。回车符也无法读入。
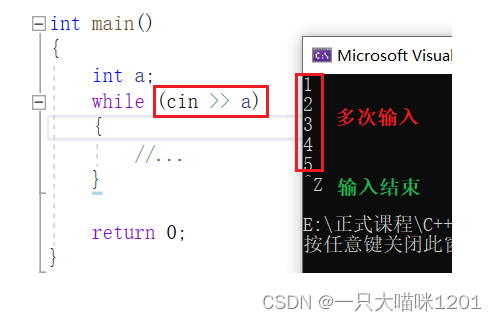
经常有上图所示的代码,cin>>a成为判断条件,此时就可以不停的进行输入,每从键盘上输入一个值,按下回车后,该值就会流入到变量a中,并且继续等待输入。
- 只有输入crtl + Z,然后按下回车,才会结束输入。
根据前面C++库中的istream& operator>>()重载函数中,可以看到返回值是一个istream类型,而while(条件)中的条件需要的是bool值或者整形指针等。
那么此时while(cin >> a)又是如何进行逻辑判断的呢?

在istream中,C++98重载了void*,C++11重载了bool这两个重载都是为了进行逻辑判断,而且重载的是类型而不是运算符。
通过上面的重载,将cin >> a返回的istream转换成了bool值,从而进行逻辑判断。当输入ctrl + z并且按下回车的时候,重载函数中就会返回false从而结束while的逻辑判断。
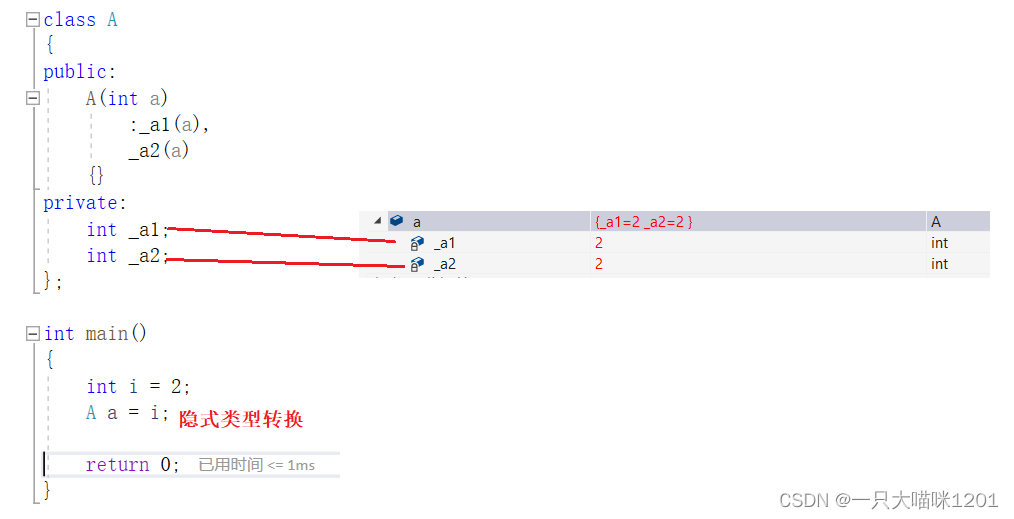
如上图代码所示,在创建a对象的时候发生了隐式类型转换,相当于将整形变量i转换成了自定义类型a。

但是,将自定义类型a转换成内置类型i就不可以,但是将int重载以后就可以了:
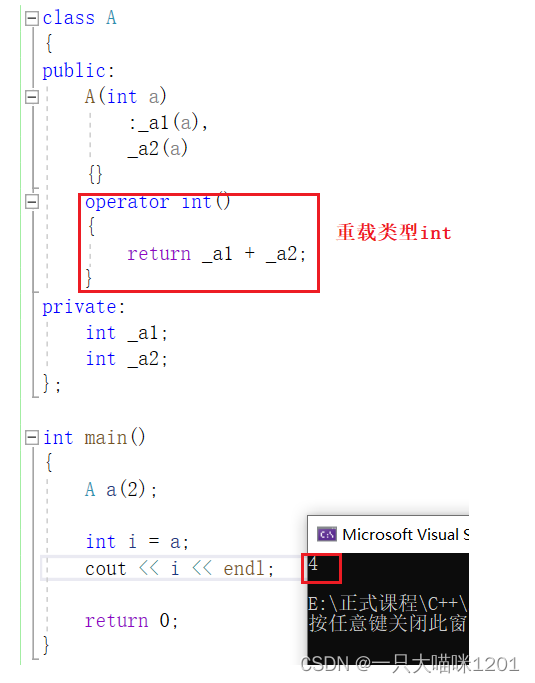
如上图所示,在类A中,将内置类型int进行重载,此时就可以将自定义变量a转换成内置类型i了,而且转换的逻辑是由我们在重载函数中自己定义的。
此就对istream类中operator bool()的理解就更加深刻了,他们的原理都是一样的,只是重载的类型不同。
- 按道理说,最好理解的方式是将
cin返回的istream类型使用()强制为bool类型,但是()的重载已经被仿函数用掉了,所以这里就只能将bool类型进行重载了。
标准输出:
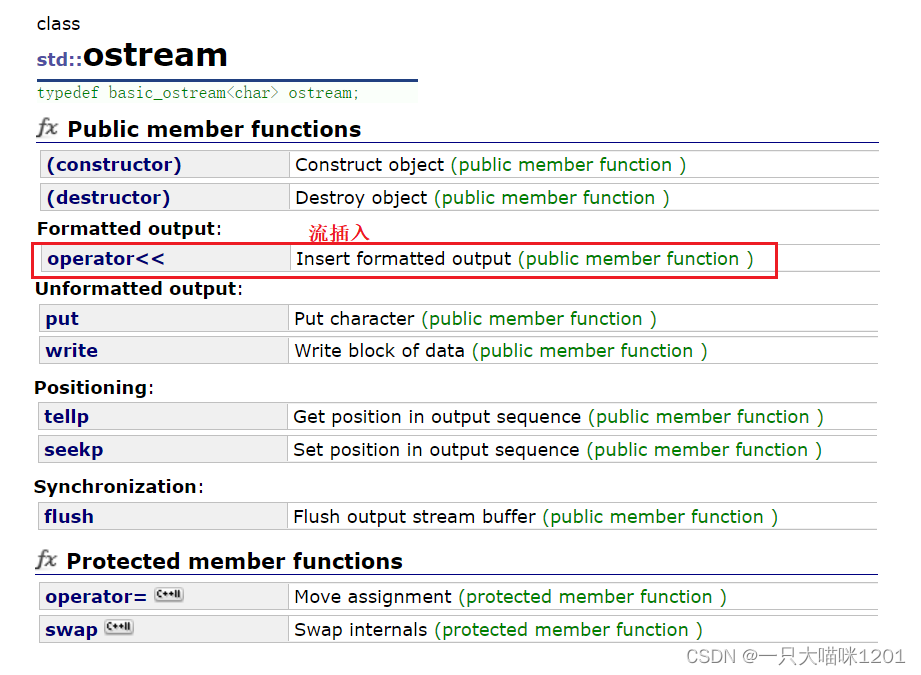
同样,ostream也重载了流插入<<运算符,用来将数据从内存中流向IO流中。
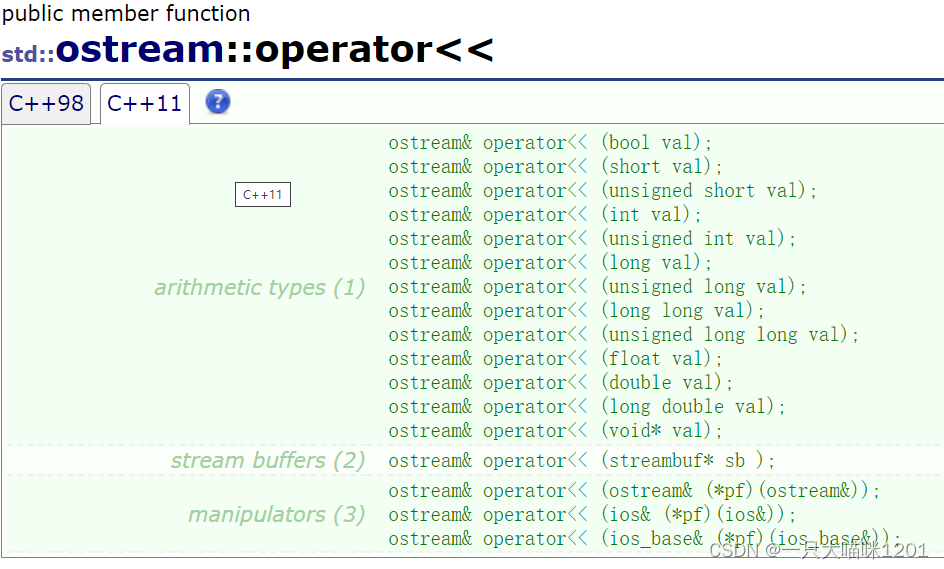
对于内置类型,C++IO库中提供了operator<<,直接使用就可以,和标准输入一样。
C++标准库提供了3个全局输出流对象cout、cerr、clog。
cout进行标准输出,即数据从内存流向控制台(显示器)。cerr用来进行标准错误的输出。clog进行日志的输出。
从上IO流的那张关系图可以看出,cout、cerr、clog是ostream类的三个不同的对象:

无论使用哪个ostream,结果都是在显示器上输出字符串,所以仅仅是应用的场景不同,但是结果相同。
对于内置类型,同样需要重载operator<<,继续拿日期类来举例:

如上图代码所示,重载流插入运算符<<,在标准输出日期类对象d的时候,直接使用cout<<d<<endl即可,此时就支持了自定义类型的标准输出。
- 同样,流插入运算符重载函数必须是
Date的友元,否则无法访问private成员。- 如果是重载函数是成员函数,在调用的时候就成了
d<<cout,同样和常规情况相差较大。
根据C++IO库的关系图中,还有一个类是iostream,可以看到,该类同时继承了istream和ostream,所以它既能进行标准输入,也能进行标准输出,并且我们平时写代码的时候,包含的头文件也是<iostream>。
根据图可以看到,iostream是一个菱形继承,因为istream和ostream同时继承了ios类,所以会存在数据冗余和二义性,同样的,C++IO库中,将这里设计成了虚拟继承(virtual)的方式。
2.2 文件IO流
文件输入
关系图中的ifstream就是用来将数据从文件流向内存的类,它继承自istream,所以标准输入的成员它都有。
- 自己的成员函数:
构造函数:

在ifstream的构造函数中,可以不传任何参数构造ifstream对象,也可以使用传参的构造函数:
- 第一个参数是要操作的文件名,可以是
string对象,也可以是const char*类的字符串。 - 第二个参数是操作文件的方式,而且有缺省值,对于
ifstream,缺失值是in方式,也就是数据从文件中流向内存中。
open():
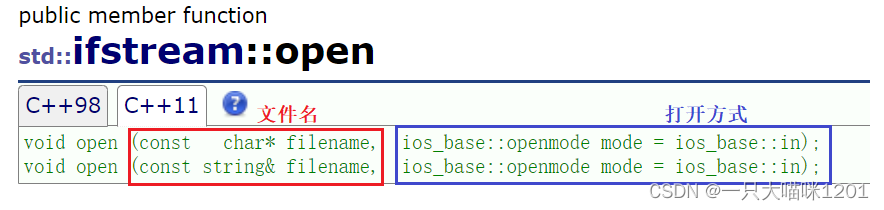
open()接口和C语言中的fopen()类似,传入的两个参数一个是文件名,另一个是打开方式。
使用open针对的是使用默认构造函数创建的ifstream对象,在创建对象的时候没有打开文件,在需要打开文件的时候使用open打开。
如果在构造ifstream的时候就打开了文件,那么就不再需要使用open打开文件了。
- 二进制读:
read():

ifstream中的read接口是从istream继承下来的,它的作用就是将ifstream对象打开的文件中的数据流向目标地址char* s,读取的数据的大小是n个字节。
二进制读就是严格按照一个字节一个字节从文件中读取,并且把读的内容再按字节放入到内存中。
- 文本读

在ifstream中仍然有operator>>,这同样是从istream中继承下来的,在这里使用流提取>>运算符,就是将ifstream中打开的文件中的数据,以文本的形式流向内存中。
ifs >> dest;
其中ifs是ifstream对象,也就是打开的文件,而dest就是目标地址,此时数据从文件流向内存。
文件输出:
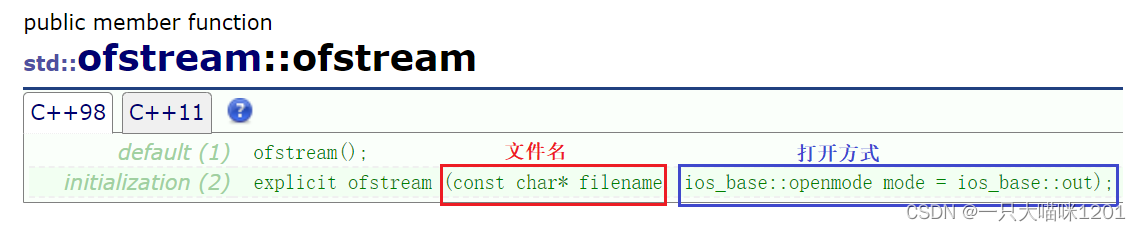
文件输出ofstream是继承自ostream,它的用法和ifstream一样,如上图所示的构造函数,在构造对象的时候可以使用默认构造函数,也可以使用带参数的构造函数,此时就在构建对象的同时打开了文件。
open:
同样也有open接口用来打开文件。
- 二进制写
write:

在使用write向打开的文件中写入数据的时候,第一个参数是要写入的内容,同样是以字符串形式写入,第二个参数是要写入数据的大小,以字节为单位。
- 文本写
同样,ofstream中也继承了ostream里的operator<<,用来将数据以文本的形式从内存中流向文件中。
ofs << dest;
ofs是ofstream对象,也就是打开的文件,dest是内存中的地址,也是数据的起始地址。
打开文件的方式:
无论是向文件中写还是读,在打开文件的时候都需要只能打开文件的方式,也就是在构建ifstream和ofstream,或者使用open的时候传入的第二个参数:

操作文件的方式有上图所示几种,以哪种方式操作文件,就在打开文件的时候将操作方式传给第二个参数。
- 输入方式打开的文件,操作方式的缺省值是in。
- 输出方式打开的文件,操作方式的缺省值是out。
如果是二进制方式输出:
ofstream(filename, ofstream::out | ofstream::binary);
只需要将多种操作方式或起来即可,即方式1 | 方式2,本质是将用来标志操作方式的那个变量的不同比特位置为1。
文件关闭:
无论是iftream还是ofstream都有一个close接口,用来关闭打开的文件,但是一般情况下不需要调用,因为文件也是通过RAII的方式在管理,当ifstream或者ofstream对象声明周期结束时,在析构函数中会自定关闭打开的文件。
同样的,还存在一个fstream类,该类继承自iostream,既可以进行文件输入,也可以进行文件输出,我们一般使用的时候,都喜欢只包含这个头文件```。
虽然看到C++对文件的操作有很多的类,也有不同的接口,感觉没有C语言那么简洁,但是实际用起来却是比C语言的接口方便了很多。
struct ServerInfo
{
char _address[32];
int _port;
};
创建一个网络服务信息的结构体,包含网络地址,以及端口信息。现在对这个结构体进行文件输入输出操作。
class ConfigManager
{
public:
ConfigManager(const char* filename)
:_filename(filename)
{}
//二进制读写
void WriteBin(const ServerInfo& info)
{
ofstream ofs(_filename, ofstream::out | ostream::binary);//打开文件流
ofs.write((char*)&info, sizeof(info));//进行写入
}
void ReadBin(ServerInfo& info)
{
ifstream ifs(_filename, ifstream::in | ifstream::binary);//打开文件流
ifs.read((char*)&info, sizeof(info));//进行读取
}
//文本读写
void WriteText(const ServerInfo& info)
{
ofstream ofs(_filename);//打开文件流
ofs << info._address << endl;
ofs << info._port << endl;//必须有换行或者空格
}
void ReadText(ServerInfo& info)
{
ifstream ifs(_filename);//打开文件流
ifs >> info._address;
ifs >> info._port;
}
private:
string _filename;
};
写一个管理信息的类,如上面代码所示,包含二进制写WriteBin,二进制读ReadBin,文本写WriteText,文本读ReadText等四个接口,成员变量仅有一个文件名名_filename。
- 二进制读写
使用二进制方式对文件进行读写的时候,在创建ifstream和ofstream的时候就将文件打开,因为是二进制方式操作,所以需要指定方式。由于操作方式都是继承下来的,所以就使用ifstream::binary这样的派生类加域作用限定符再加方式即可。
进行数据流动的时候,使用read和wirte接口即可,此时数据的流动严格按照一个字节一个字节来。
- 文本读写
在创建文件流对象的时候,不需要再传第二个参数,因为此时使用缺省值就够用,ifstream的缺失值是ifstream::in,ofstream的缺省值是ofstream::out。
在向文件中写的时候,由于是文本的方式,本质上就是字符串,所以不同类型的变量之间必须加换行或者空格来分隔,否则写入的所有变量都会被当作一个字符串处理。
在读取的时候,不需要再去关注空格或者换行,直接读取即可,因为文件中的数据在存放的时候就已经根据不同类型分类好了。
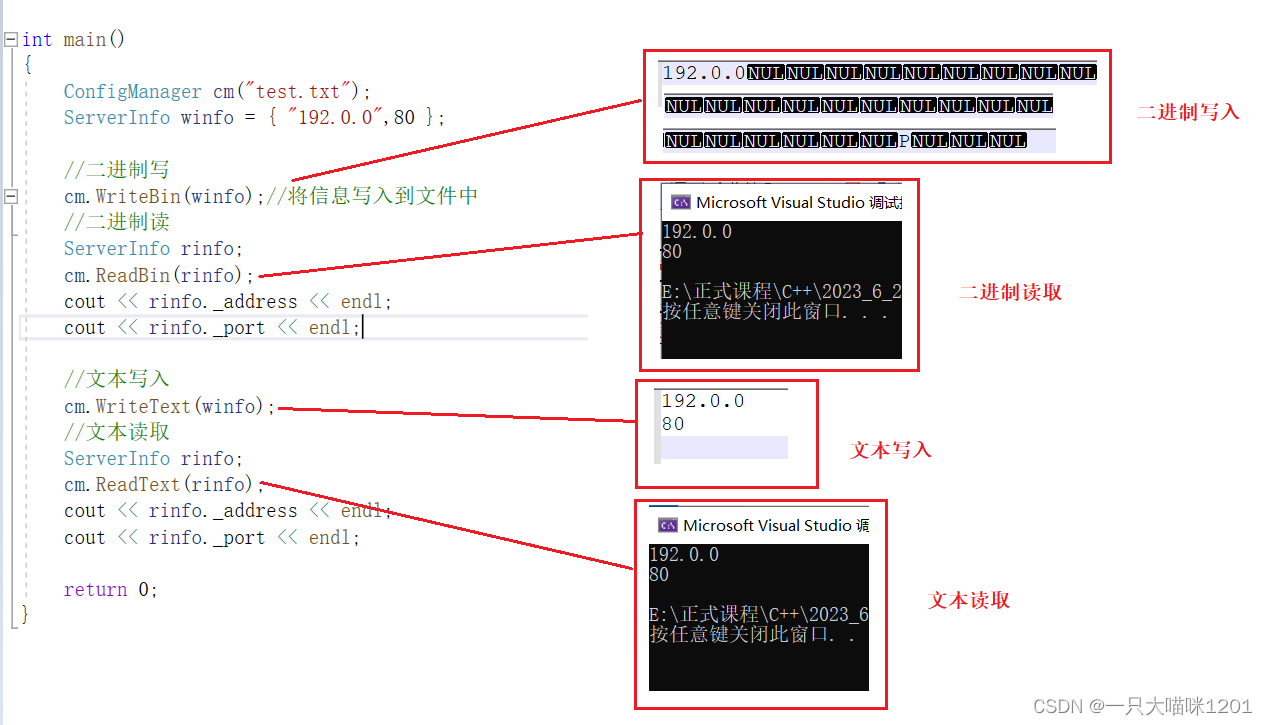
以二进制方式向文件中写入时,调用的是WriteBin接口,生成的文件中的有很多的NULL(三行内容其实是一行),这其实就是ServerInfo变量在内存中的样子,那些NULL就是因为内存对齐而保留的空间。
以二进制方式从文件中读取内容,调用的是ReadBin接口,ServerInfo变量中的两个成员成功从文件中获取到了值,而且打印出来也符合预期。
以文本方式向文件中写入时,调用的是WriteText接口,生成的文件中的内容就是我们所输入的样子,因为此时输入的就是字符串,所以输入什么,在文件中就保存什么。以字符串的方式向文件中输入,可以清除的看到内容。
以文本方式从文件中读取内容,调用的是ReadText接口,结果和也符合我们的预期。
但是在写入的时候,不同类型的变量必须用空格或者换行分割开,否则所有变量就被当成是一个字符串了,在读取的时候也不能正确读取。

原本在ServerInfo中,_address使用的是char[32]数组,此时改成字符串string类型,如上图所示。
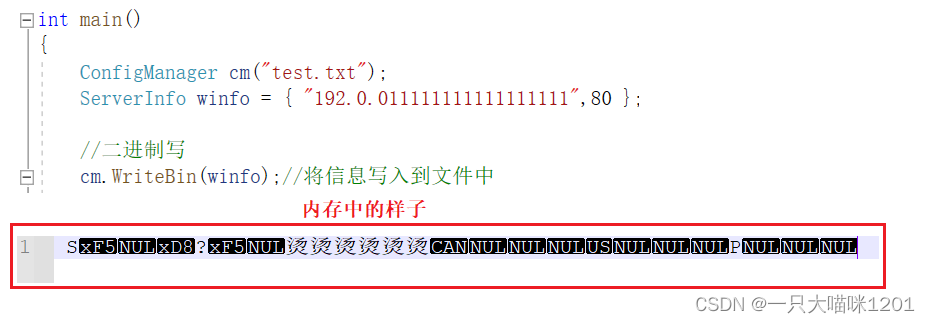
此时将winfo中的内容以二进制的方式写入到文件中,如上图所示。写完后进程结束。
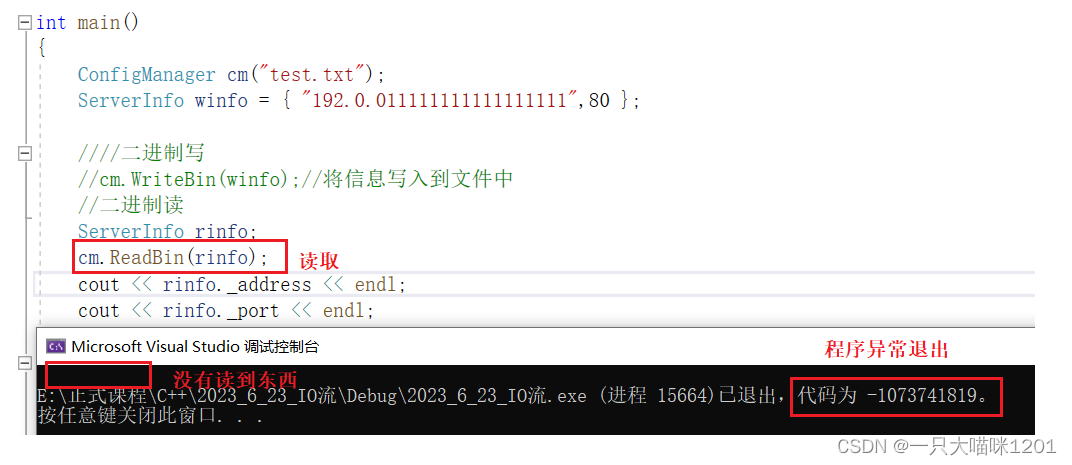
此时再用一个新的进程读取刚刚写入文件中的内容,如上图中所示。此时读取就出现了错误,而且什么都没有读出来。
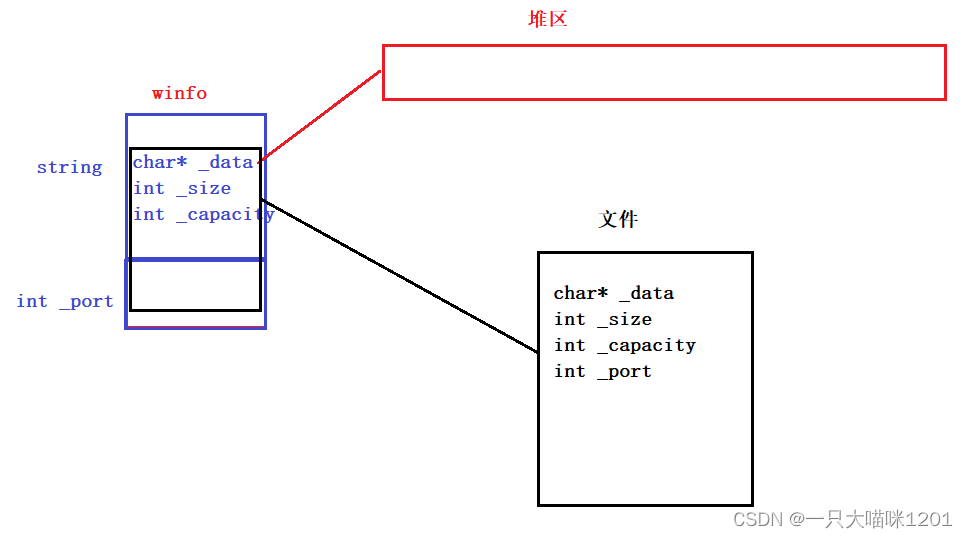
如上图所示,此时的ServerInfo中的成员变量如蓝色框中所示,包括一个string对象,一个int _port,而string中又有三个成员。
在使用二进制方式将ServerInfo中的数据写入到文件中时,严格按照一个字节一个字节的方式复制到了文件中,如上图黑色框中所示。
但是,原本char* _data指向的堆区空间没有被复制到文件中,所以在当前写的进程结束以后,这个堆区就被释放了。当一个新的进程从文件中读取的时候,读取到的是合适框中的四个变量。
再根据读取到的char* data指针去堆区上寻找数据时就找不到了,此时的指针就是一个野指针,所以会出错。
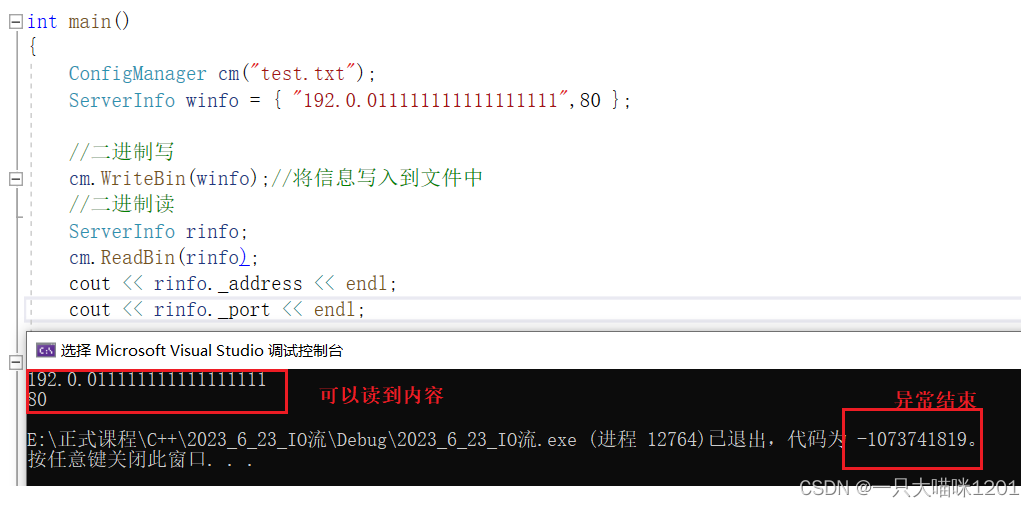
如果在同一个进程中,写进行写入,再进行读取,可以看到可以成功将内容读取出来,但是程序还是异常结束。
这是因为,在读取的时候,从文件中拿到的char* _data指针指向的空间仍然存在,所以可读取到相应的内容。
而异常结束是因为,winfo和rinfo中有两个char* _data的指针指向同一个堆空间,所以在释放的时候会释放两次,所以导致程序异常结束。
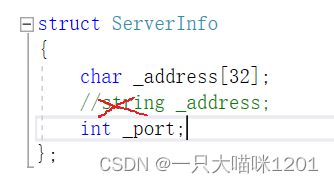
而使用char类型的数组就不会出现这样的问题,因为在将数据按字节放入到文件中时,char _address[32]数组中的数据也会被放到文件中,所以在读取的时候,会正常读取回来。
而以文本的方式操作也不会出现二进制操作的这种错误,因为文本方式存入文档中的就是字符串,并且是连内容一块存放进去的,所以读取也能够正常读取出来。
2.3 stringstream
二进制方式操作文件,虽然能够节省一定的内存,但是文件中的内容我们看不懂,而且有时候还会出各种各样的问题,所以采样文本的方式操作文件就省了很多的事情。
在网络中,传送的数据包通常都是文本形式的文件,不仅可以看到文件中的内容,而且处理也很方便。
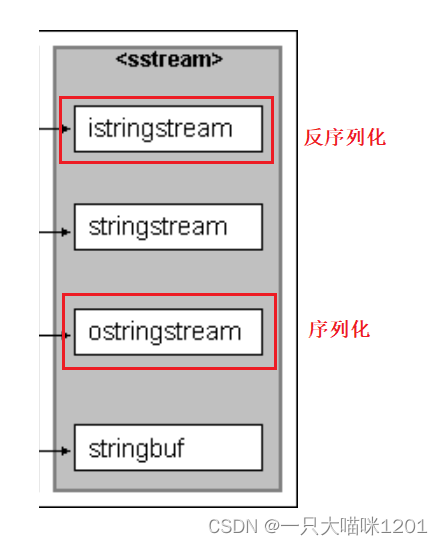
在关系图中,最后一列的几个类就是将任意类型的数据转换成字符串的。
- 序列化:将其他类型的数据转换成字符串。
- 反序列化:将转换后的字符串恢复到原来的类型。
istringstream就是进行反序列化的,ostringstream就是进行序列化的,它们分别继承自istream和ostream。同样的还有一个stringstream,这个类既可以继续序列化也可以进行反序列化,在使用这一些列类的时候,需要包含头文件<sstream>。
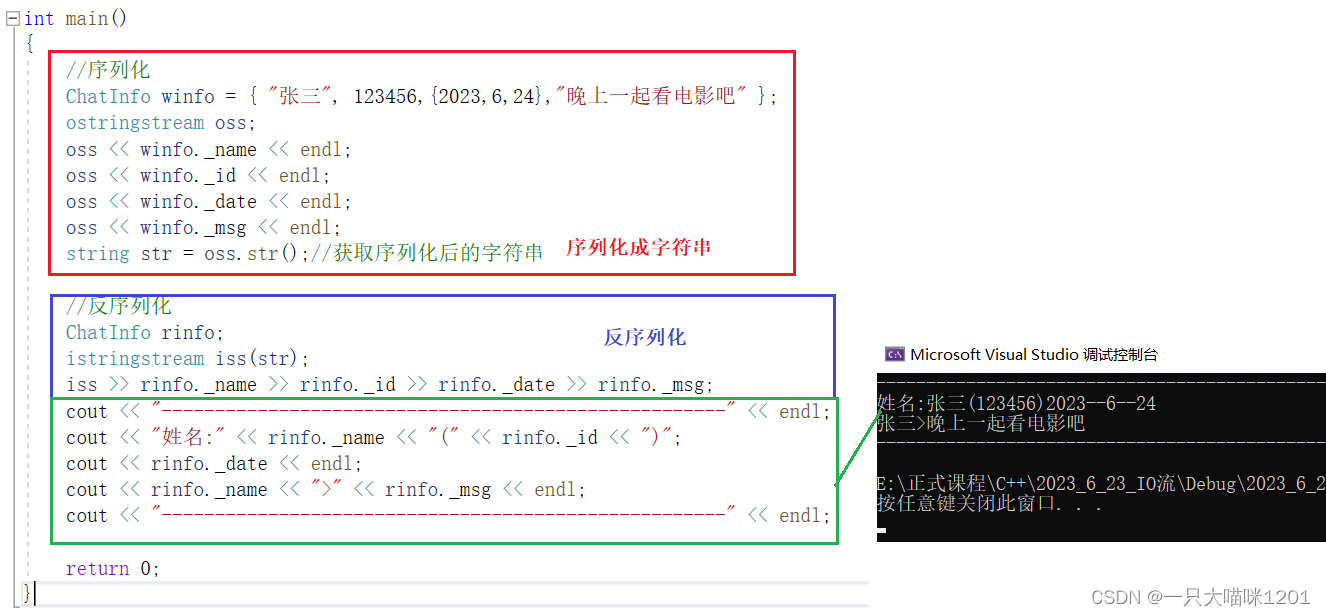
将聊天信息结构体中ChatInfo中的多种类型数据序列化,如上图红色框中所示,同样使用<<运算符,每个类型后同样需要加空格或者换行来进行分隔。
最终将所有变量类型序列化后形成的整体字符串使用str()接口获取到。
再构建反序列化istringstream的时候,给构造函数传序列化后的字符串str,然后就可以通过>>将序列化后的内容反序列化,并且赋值给rinfo,通过打印,可以看到和我预期的结果一样。
- 使用
stringstream的序列化和反序列化局限性太大,因为只能通过空格或者换行来分隔不同类型的变量。- 在学习网络的时候,本喵会介绍其他方式的序列化和反序列化。
三、 空间配置器(了解)
- 空间配置器:为各个容器高效的管理空间(空间的申请与回收)的,在默默地工作。
前面在模拟实现vector、list、map、unordered_map等容器时,所有需要空间的地方都是通过new申请的,虽然代码可以正常运行,但是有以下不足之处:
- 空间申请与释放需要用户自己管理,容易造成内存泄漏。
- 频繁向系统申请小块内存块,容易造成内存碎片。
- 频繁向系统申请小块内存,影响程序运行效率。
- 直接使用malloc与new进行申请,每块空间前有额外空间浪费。
- 申请空间失败怎么应对。
最重要的就是,使用空间配置器来管理内存可以提供程序运行的效率。
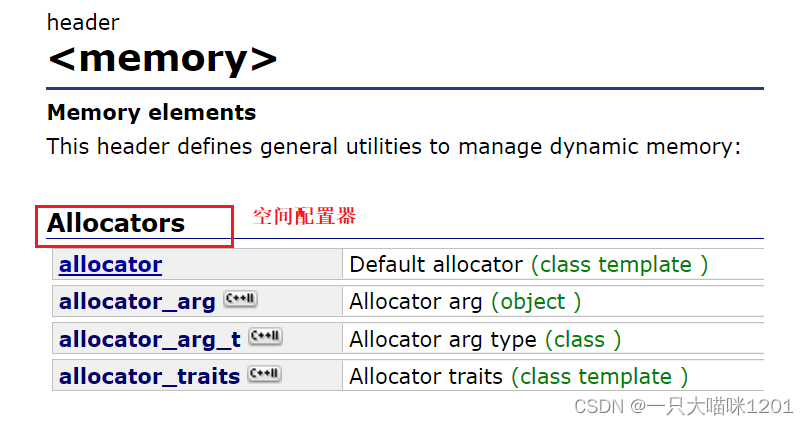
在C++标准库中,存在着空间配置器。
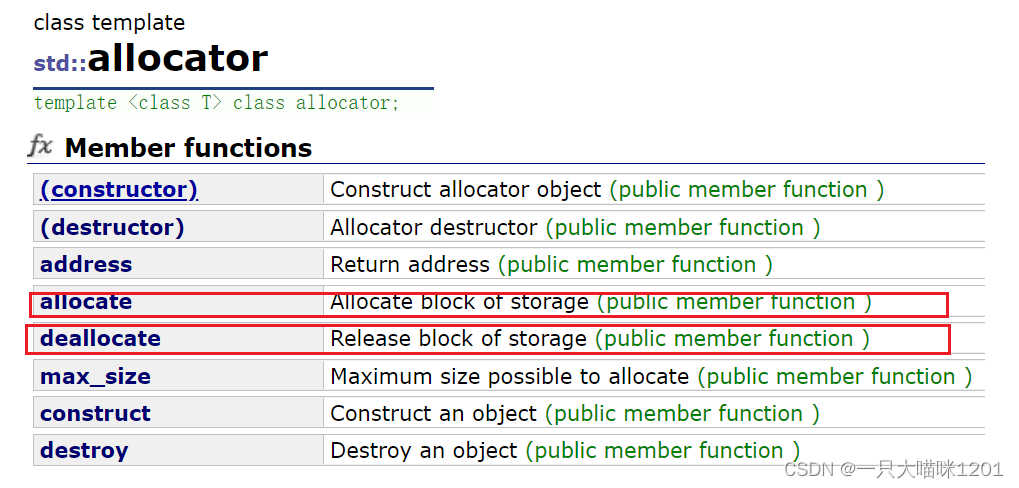
最重要的就是allocate开辟空间以及deallocate释放空间。

无论使用哪种STL中的容器,都会有一个空间配置器的模板参数,默认的是给了一个缺省值的,也就是C++库中实现的空间配置器,我们也可以才入自己实现的空间配置器,但是必须要有allocate和deallocate这两个接口。
3.1 一级空间配置器
一级空间配置器原理非常简单,直接对malloc与free进行了封装。
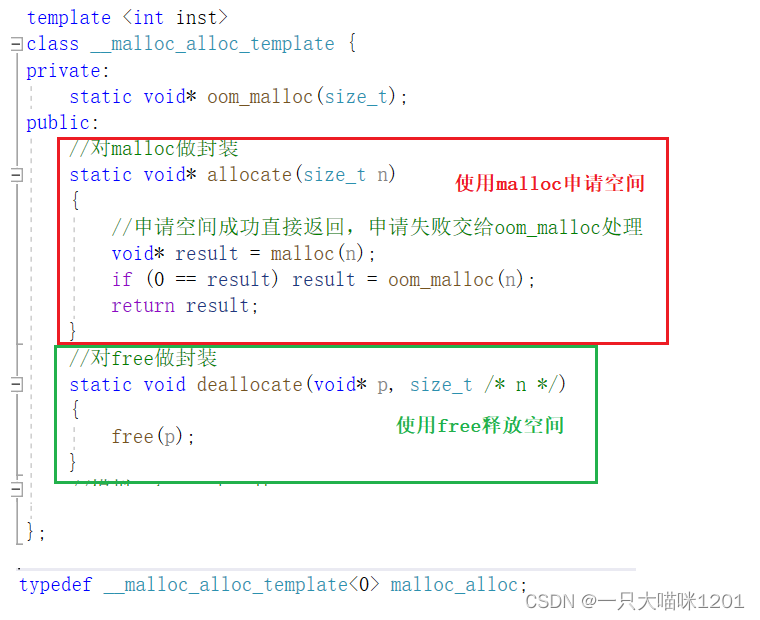
上图代码是STL一级空间配置器的部分源码,其本质就是将malloc和free进行了封装,去开开辟和释放空间。
- 一级空间配置器就可以理解为使用malloc去开辟空间,使用free去释放空间。
3.2 二级空间配置器
- 二级空间配置器专门负责处理小于128字节的小块内存。
- 采用了内存池的技术来提高申请空间的速度以及减少额外空间的浪费,采用哈希桶的方式来提高用户获取空间的速度与高效管理。
- 内存池:先申请一块比较大的内存块做备用,当需要内存时,直接到内存池中去取,当池中空间不够时,再向内存使用
malloc中去取,当用户不用时,直接还回内存池即可。 - 避免了频繁向系统申请小块内存所造成的效率低、内存碎片以及额外浪费的问题。
二级空间配置器中存在3个成员变量:
template <int inst>
class __default_alloc_template
{
char* start;
char* end;
size_t heap_size;
};
start表示内存池的起始位置,end表示内存池的结束位置,heap_size表示内存池的大小。

二级空间配置器的结构如上图所示,存在一个内存池,还有一个哈希表,下面挂着哈希桶。哈希表中的数字,表示挂在这个位置哈希桶的大小,也就是所需要空间的大小。
- 在第一次开辟空间的时候,此时内存池是空的,哈希表中也是空的,没有挂任何一个桶。
假设要new一个16个字节大小的节点,首先会去哈希表中挂载16个字节大小的位置查找有没有哈希桶存在,因为是第一次,所以没有。
此时再去内存池中要内存,但不是仅要16个字节,而是要多个16个字节,STL中采样一次要20个16个字节的内存,也就是一共320个字节,但是此时的内存池同样也没有内存,所以去使用malloc向系统申请,申请好后放在内存池中。
此时内存池中就有20个16个字节的内存,因为new节点需要一个,所以就拿走一个给容器使用,剩下的19个,挂在哈希表中表示16个字节大小的位置处。
- 当之后再次new16个字节的节点时,此时哈希表中挂载着多个16个字节大小的桶。每new一个节点,就从哈希表中拿走一个16个字节的桶。
- 如果有归还的节点,那么就头插到哈希表中,之后再new节点时,归还的桶还可以再用。
- 如果new6个字节大小的节点,那么就去哈希表中寻找大小为8的桶,继续重复上面的操作。
- 哈希表中每个位置挂载的桶的大小是存在对齐的,规律就是8的倍数,但是不超过128。
每个哈希桶又是以什么样的方式挂载的呢?
union obj
{
union obj* next;//下一个哈希桶的地址
char * data[8*i];//大小是8的整数倍
};

挂载的哈希桶是联合体变量,第一个变量是union obj* next也就是下一个哈希桶的指针。
第二个变量才是真正的内存空间,可以供容器存放数据的空间。
- 哈希桶的地址只有在挂载的时候才有意义,而此时存放数据的空间里的内容是不重要的。
- 哈希桶被从哈希表拿走后,它里面存放地址的成员又不重要了,因为此时容器需要的是它存放数据的空间。
- 当这块空间被归还头插到哈希表中的时候,只需要将里面的指针变量指向下一快挂载的空间即可。
这里使用联合体变量可以节省很多的空间,而且充分利用到了联合体的特性。
- 如果是64位的机器,那么指针变量的大小就是8个字节,所以在挂载的是,大小为8的那个桶中,所有的内存块中都只能存放下一个指针。
这也就是为什么哈希桶要采用8的倍数对齐的原因。
- 当某个位置的哈希桶中的内存块都被使用完毕后,在new新的节点时,会继续向内存池中要内存,如果内存池中没有就会向系统malloc申请内存。
如果此时系统中也没有内存了,malloc失败了会怎么办呢?会从哈希表中向后面查找是否存在哈希桶,如果存在就分隔后面的,如果都没有,则申请失败抛异常。
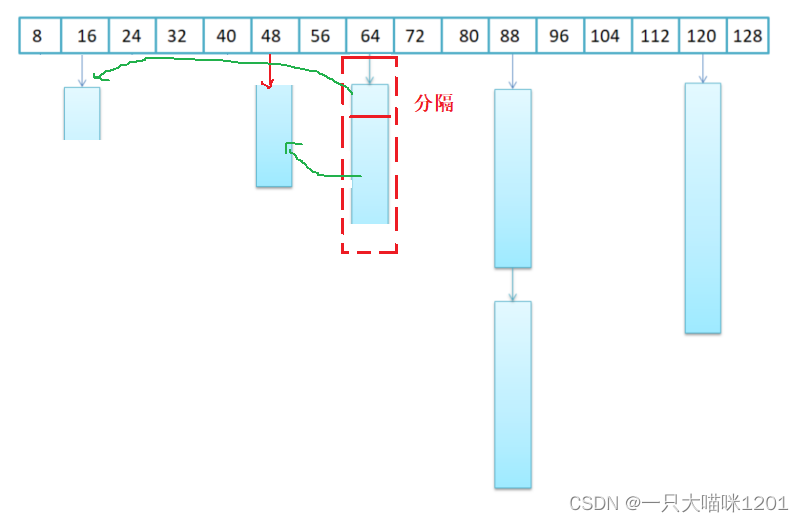
假设在现在申请的new的是16个字节大小的节点,该位置的哈希桶为空,并且系统中也没有内存了。
此时就会向后面的哈希桶中寻找,找到64位置的时候,发现存在哈希桶,就将这里64个字节的内存空分隔成16字节和48字节两部分,16字节的给new出来的新节点使用,48字节的部分挂载在48的位置处。

使用空间配置器管理空间的时候,在申请内存时,如果是大于128字节,那么直接使用一级空间配置器,使用malloc开辟大块空间。如果是小于128字节,那么就使用二级空间配置器去管理内存。
- 当申请的空间大于128的时候,就按照大内存块去处理。
- 一级空间配置器是嵌套在二级空间配置器里面的。
- 由于哈希结构的插入以及查找效率非常高,所以空间配置器能够很大程度上提高程序的运行效率。
3.3 与容器的结合
那么空间配置器又是怎么和容器结合在一起的呢?继续来看部分源码:
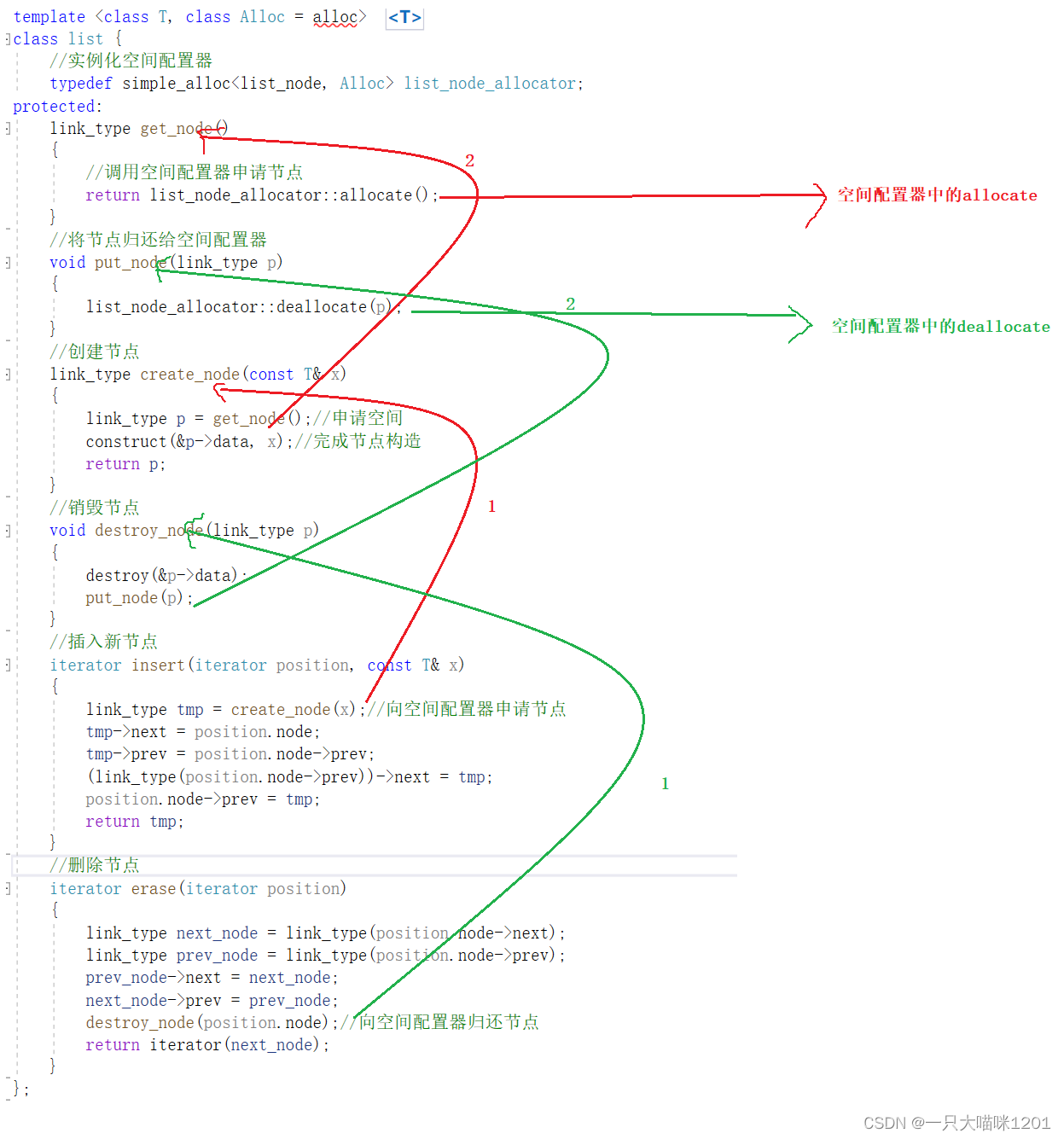
以list为例,在使用insert插入节点的时候,会调用create_node(x),如上图红色标号1,继而在内部继续调用get_node(),如上图红色标号2,继续在内部调用空间配置器的allocate(),从而向空间配置器中申请空间。
在使用erase删除节点的时候,会调用destroy_node(),如上图绿色标号1,继而在内部继续调用put_node(),如上图绿色标号2,继续在内部调用空间配置器的deallocate(),从而将内存归还给空间配置器。
空间配置器只会存在一个,所以可以也是一个单例对象,不同的容器甚至是不同线程都可以使用。比如map归还的空间set可以继续使用。
空间配置器在很早之前就已经有了,现在来看已经有点落后了,所以本喵没有详细讲解,有兴趣的小伙伴可以自行研究它的实现细节。
四、 总结
到这里,本喵的C++学习也告一段落,这篇文章中的线程库,IO流,以及空间配置器,都是本喵目前使用的比较少的内容,所以也没有详细的讲解,在用到的时候可以根据文档查阅着使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
上一篇:解决虚拟机桥接网络没有 VMnet0 的问题
下一篇:Java集合
相关文章
最新发布
点击排行
本站推荐
