首页 > 基础资料 博客日记
Java - ThreadPoolExecutor线程池分析
2023-08-31 21:31:40基础资料围观677次
Java - ThreadPoolExecutor源码分析
1. 为什么要自定义线程池
首先ThreadPoolExecutor中,一共提供了7个参数,每个参数都是非常核心的属性,在线程池去执行任务时,每个参数都有决定性的作用。
但是如果直接采用JDK提供的方式去构建,可见设置的核心参数最多就两个,这样就会导致对线程池的控制粒度很粗。所以在阿里规范中也推荐自己创建自定义线程池。
自定义构建线程池,可以细粒度的控制线程池,去管理内存的属性,并且针对一些参数的设置可能更好的在后期排查问题。
ThreadPoolExecutor 七大核心参数:
public ThreadPoolExecutor(int corePoolSize, // 核心工作线程(当前任务执行结束后,不会销毁)
int maximumPoolSize, // 最大工作线程(代表当前线程池中一共可以有多少工作线程)
long keepAliveTime, // 非核心工作线程在阻塞队列位置等待时间
TimeUnit unit, // 非核心工作线程在阻塞队列位置等待时间的单位
BlockingQueue<Runnable> workQueue, // 任务在没有核心工作线程处理时,任务先到阻塞队列中
ThreadFactory threadFactory, // 构建线程的线程工厂,可以自定义thread信息
RejectedExecutionHandler handler) // 当线程池无法处理处理任务时,执行拒绝策略
2.ThreadPoolExecutor应用
JDK提供的几种拒绝策略:
- AbortPolicy: 当前拒绝策略会在无法执行任务时,直接抛出一个异常
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
- CallerRunsPolicy: 当前拒绝策略会在无法执行任务时,将任务交给调用者处理
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
- DiscardPolicy:当前拒绝策略会在无法执行任务时,直接将任务丢弃
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
- DiscardOldestPolicy: 当前拒绝策略会在无法执行任务时,将阻塞队列中最早的任务丢弃,将当前任务再次交接线程池处理
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
- 当然也可以自定义拒绝策略,根据自己业务修改实现逻辑, 只需实现 RejectedExecutionHandler 类中的 rejectedExecution 方法。
3. ThreadPoolExecutor的核心属性
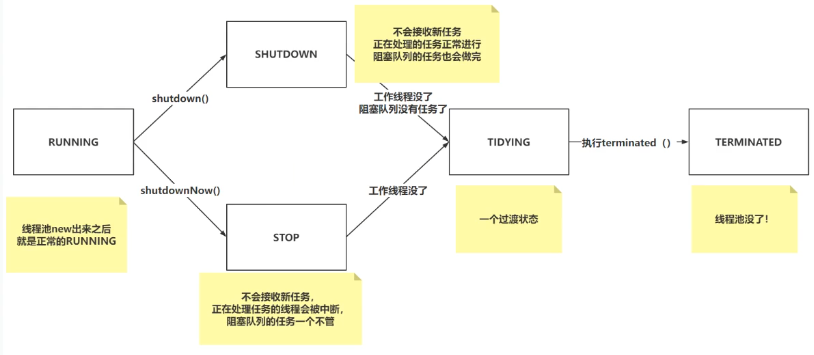
线程池的核心属性就是ctl,它会基于ctl拿到线程池的状态以及工作线程个数。
// 当前线程的核心属性
// 当前的ctl其实就是一个int类型的数值,内部是基于AtomicInteger套了一层,进行运算时,是原子操作
// ctl表示线程池的两个核心属性
// 线程池的状态: ctl的高3位,表示线程池状态
// 工作线程的数量: ctl的低29位,表示工作线程的个数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// Integer.SIZE: 获取Integer的bit位个数
// 声明一个常量: COUNT_BITS = 29
private static final int COUNT_BITS = Integer.SIZE - 3;
// CAPACITY就是当前工作线程能记录的工作线程的最大个数
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池状态表示
// 当前五个状态中,只有RUNNING状态表示线程池正常,可以正常接收任务处理
// 111: 代表RUNNING状态,RUNNING可以处理任务,并且处理阻塞队列中的任务
private static final int RUNNING = -1 << COUNT_BITS;
// 000: 代表SHUTDOWN状态,不会接收新任务,正在处理的任务正常进行,阻塞队列中的任务也会处理完
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 001: 代表STOP状态,不在接收新任务,正在处理的任务会被中断,阻塞队列中的任务不在处理
private static final int STOP = 1 << COUNT_BITS;
// 010: 代表TIDYING状态,这个状态是SHUTDOWN或者STOP转换过来的,代表线程池马上关闭,过度状态
private static final int TIDYING = 2 << COUNT_BITS;
// 011: 代表TERMINATED状态,这个状态是TIDYING转换过来的,转换过来需要执行terminated方法
private static final int TERMINATED = 3 << COUNT_BITS;
// 下面方法是帮助运算ctl值的,需要传入ctl
// 基于&运算的特点,保证获取ctl的高3位的值
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 基于&运算的特点,保证获取ctl的低29位的值
private static int workerCountOf(int c) { return c & CAPACITY; }
// runStateOf 和 workerCountOf 方法都是拆包
// 基于|运算的特点,对线程池状态rs和线程个数wc进行封装
private static int ctlOf(int rs, int wc) { return rs | wc; }
线程池的转换方式:
ThreadPoolExecutor中的execute方法
execute方法是提交任务到线程池的核心方法。
execute源码解析:
// 提交执行任务
// command 就是提交过来的任务
public void execute(Runnable command) {
// 提交的任务不能为null 健壮性判断
if (command == null)
throw new NullPointerException();
// 获取核心属性ctl值,用于后续判断
int c = ctl.get();
// 如果工作线程个数小于核心线程数
// 满足要求,添加核心工作线程
if (workerCountOf(c) < corePoolSize) {
// addWorker(任务,是否是核心线程) ture: 核心线程,false:非核心线程
// addWorker返回true: 代表添加工作线程成功
// addWorker返回false: 代表添加工作线程失败
// addWorker中会基于线程池状态,以及工作线程个数判断,查看能否添加工作线程
if (addWorker(command, true))
// 工作线程构建出来了,任务也交给command去处理了
return;
// 说明线程池状态或者是工作线程个数发生了变化,导致添加失败,需要重新获取ctl值
c = ctl.get();
}
// 添加核心工作线程失败后
// 先判断线程池状态是否是RUNNING状态,如果是正常基于阻塞队列的offer方法,将任务添加到阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
// 如果任务添加到阻塞队列成功,走if内部
// 如果任务在丢到阻塞队列之前,线程池状态发生改变了
// 重新获取ctl
int recheck = ctl.get();
// 如果线程池的状态不是RUNNING状态,将任务从阻塞队列中移除
if (! isRunning(recheck) && remove(command))
// 并且直接拒绝策略
reject(command);
// 在这,说明阻塞队列有我刚放进去的任务
// 查看一下工作线程数是不是0个
// 如果工作线程为0个,需要添加一个非核心工作线程去处理阻塞队列中的任务
// 发生这种情况有两种:
// 1. 构建线程池时,核心线程数可以是0个
// 2. 即使有核心线程,可以设置核心线程也允许超时,设置allowCoreThreadTimeOut(默认false)为ture
else if (workerCountOf(recheck) == 0)
// 为了避免阻塞队列中的任务堆积,添加一个非核心线程去处理
addWorker(null, false);
}
// 任务添加到阻塞队列失败
// 构建一个非核心工作线程
// 如果添加非核心工作线程成功,直接完成
else if (!addWorker(command, false))
// 添加失败,执行拒绝策略
reject(command);
}
execute方法流程图:
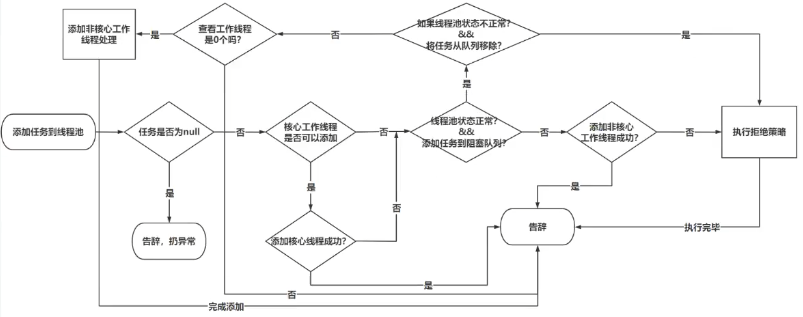
ThreadPoolExecutor中的addWorker方法
addWorker方法中主要分为两大块:
- 第一块:校验线程池的状态以及工作线程个数
- 第二块:添加工作线程并且启动工作线程
// 校验和添加启动工作线程
private boolean addWorker(Runnable firstTask, boolean core) {
// =======================第一块====================
// 外层for循环在校验线程池的状态
// 内层for循环是在校验工作线程的个数
// retry是给外层for循环添加的一个标记,为了方便在内层for循环跳出到外层for循环
retry:
for (;;) {
// 获取ctl
int c = ctl.get();
// 拿到ctl的高3位的值
int rs = runStateOf(c);
// =====================线程池状态判断==========================
// 如果线程池状态是SHUTDOWN,并且此时阻塞队列有任务,工作线程为0,则添加一个工作线程去处理阻塞队列的任务
// 判断线程池的状态是否大于等于SHUTDOWN,满足则说明线程不是RUNNING状态
if (rs >= SHUTDOWN &&
// 如果这三个条件都满足,就代表是要添加非核心工作线程去处理阻塞队列中任务
// 如果三个条件有一个不满足,返回false配合!,就不需要添加
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
// 不需要添加工作线程
return false;
for (;;) {
// ===============工作线程个数判断==========================
// 基于ctl拿到低29位的值,代表工作线程的个数
int wc = workerCountOf(c);
// 如果工作线程个数大于最大工作线程数CAPACITY值,就不可以添加,返回false
if (wc >= CAPACITY ||
// 基于core来判断添加的是否是核心工作线程
// 如果是核心: 基于corePoolSize去判断
// 如果是非核心: 基于maximumPoolSize去判断
wc >= (core ? corePoolSize : maximumPoolSize))
// 代表不能添加,工作线程个数不满足要求
return false;
// 针对ctl + 1 , 采用CAS操作
if (compareAndIncrementWorkerCount(c))
// CAS成功后,直接退出外层循环,代表可以进行执行添加工作线程操作了
break retry;
// 重新获取一次ctl值
c = ctl.get(); // Re-read ctl
// 判断重新获取的ctl中,线程池的状态与之前是否有区别
// 如果状态发生改变,需要重新去判断线程状态
if (runStateOf(c) != rs)
// 重新进入外层for循环
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// =======================第二块====================
// 添加工作线程以及启动工作线程
// 声明了三个变量
// workerStarted 表示工作线程启动状态,默认false
boolean workerStarted = false;
// workerAdded 表示工作线程添加状态,默认false
boolean workerAdded = false;
// w 表示工作线程
Worker w = null;
try {
// 构建工作线程,并且将任务传递进去
w = new Worker(firstTask);
// 获取worker中的thread对象
final Thread t = w.thread;
// 判断thread是否不为null, 在new worker时,内部会通过给予的threadFactory去构造thread交给worker
// 一般如果为null,代表ThreadFactory有问题
if (t != null) {
// 加锁,保证使用worker成员变量以及对largestPoolSize赋值时,保证线程安全
final ReentrantLock mainLock = this.mainLock;
// 加锁, 因为后续要操作HashSet是线程不安全的
mainLock.lock();
try {
// 再次获取线程池状态
int rs = runStateOf(ctl.get());
// 再次判断
// 如果满足 rs < SHUTDOWN,说明线程池是RUNNING状态,可以继续执行
// 如果线程池状态为SHUTDOWN,并且firstTask为null,添加非核心线程处理阻塞队列任务
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 进入这里,就可以添加工作线程
// 将threadFactory构建线程后,不能直接启动线程,如果启动则抛出异常
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
/**
* 包含池中所有工作线程的集合。只有在获得mainLock时才能访问
* private final HashSet<Worker> workers = new HashSet<Worker>();
* 将创建好的worker放入工作线程集合中
*/
workers.add(w);
// 获取工作线程集合的大小,拿到工作线程个数
int s = workers.size();
// largestPoolSize在记录最大线程个数的记录
// 如果当前工作线程个数,大于最大线程个数的记录,就赋值
if (s > largestPoolSize)
largestPoolSize = s;
// 设置工作线程添加成功
workerAdded = true;
}
} finally {
// 释放锁
mainLock.unlock();
}
// 如果工作线程添加成功
if (workerAdded) {
// 直接启动worker中的线程
t.start();
// 设置启动工作线程成功
workerStarted = true;
}
}
} finally {
// 做补偿的操作,如果工作线程启动失败,将这个添加失败的工作线程处理掉
if (! workerStarted)
// 从工作线程的集合中移除掉
addWorkerFailed(w);
}
// 返回工作线程释放启动成功
return workerStarted;
}
线程池为啥要构建空任务的非核心线程?
- 第一个:在 execute 方法中有个判断工作线程是否为0,是就添加一个空任务的非核心线程;
else if (workerCountOf(recheck) == 0) addWorker(null, false);
- 第二个:在工作线程 Worker 启动后,工作线程会运行 runWorker 方法,该方法中有个操作,当工作线程结束之后会执行 processWorkerExit 方法,在这个方法内部又有添加一个空任务的非核心线程;
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
综合上诉,Java它有一个这样的场景:
在初始化线程池的时候可能设置线程池的核心线程数为0 或者 设置allowCoreThreadTimeOut(默认false)为ture导致核心线程超时释放,存在没有核心线程的情况。
当我们把任务添加到阻塞队列之后,没有工作线程导致阻塞队列任务堆积,直到后续有新任务加入才会去创建工作线程。

/** * If false (default), core threads stay alive even when idle. * If true, core threads use keepAliveTime to time out waiting * for work. * 如果为false(默认值),核心线程即使在空闲时也会保持活动状态。 * 如果为true,核心线程将使用keepAliveTime超时等待工作 */ private volatile boolean allowCoreThreadTimeOut;
综上所述,因此线程池需要构建空任务的非核心线程去处理这种情况。
线程池使用完为什么必须执行shutdown方法或者shutdownNow方法?
- 第一点:在线程池 addWorker 方法中我们可以看到,
线程池启动线程也是基于 Thread 对象去进行的一个 start 方法启动的,像这种它会占用jvm的栈,
所以属于GC Roots 通过垃圾回收的可达性分析算法,这种线程就不能被回收,会一直占用jvm的资源,
因此不能及时的调用 shutdown 或者 shutdownNow 方法,就可能造成内存泄漏问题!!!
- 第二点:线程池启动对象是基于你 Worker 对象内部的 Thread 对象启动的,
当执行Thread对象的 start方法时,它会执行 Worker对象的 run 方法,
该方法中的runWorker 方法传入的是 this 就是当前的Worker对象,
就会导致启动的线程还指向了Worker对象,这个Worker对象是不能回收的,
又因为Worker对象属于线程池的内部类,
导致整个 ThreadPoolExecutor 线程池对象也不会被回收!!!
综上所述,当使用完线程池对象后,没有及时的调用关闭方法,会导致堆内存资源消耗很严重,最后会导致内存泄漏问题!
线程池的核心参数该如何设置?
主要的难点在于任务类型无法控制,比如:
cpu密集型: cpu不断的处理任务,大量的计算等操作。
IO密集型: 不需要cpu一直调度,大多数时间都是等待结果的,如:调用第三方服务等待网络响应、等待IO响应、查询数据库等待数据库响应等等。
混合型:上面两种都会有。
大多数情况都需自己去测试,调试!没有绝对固定的一个公式。可以参考:
N thread = N cpu * U cpu * ( 1 + W / C )
线程数 = cpu的个数 * cpu的利用率 * ( 1 + 等待时间 / 计算时间 ) 注:W/C 是程序运行时 等待时间和计算时间的比值
1 * 100% * (1 + 50% / 50% )= 2
公式只是给定一个调试的初始值,需要自己后续测试调试!
以上可能还有不足,仅供参考!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
