首页 > 基础资料 博客日记
JavaSE常问问题(集合)
2023-07-24 16:37:07基础资料围观664次
1.1 集合
集合是一个Java存储容器,主要指的是--内存层面--的存储,不涉及到持久化的存储
注:Collection中add的对象都必须要重写equals()
--数组--:
-
特点
-
一旦初始化以后,长度就确定了
-
一旦数组定义好,其元素的类型也就确定了
-
-
缺点
-
初始化后其长度不可修改
-
添加、删除、插入数据操作不便
-
获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用
-
数组存储数据的特点:有序、可重复。对于无序、不可重复的需求不能满足
-
-
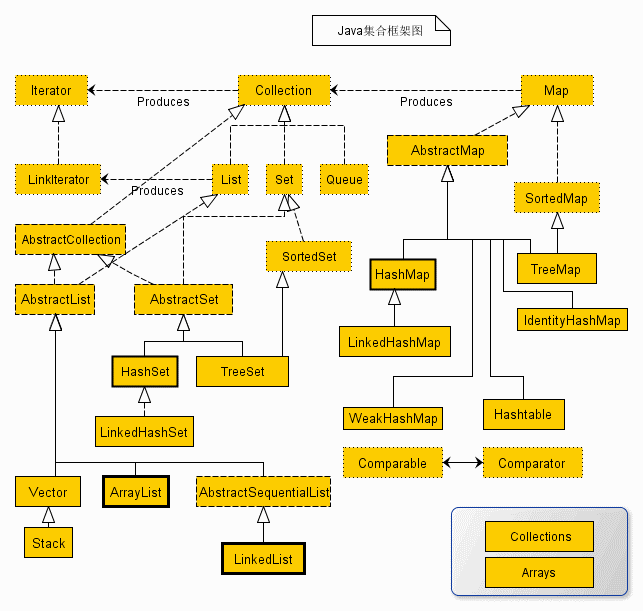
Collection接口
-
--List--接口
-
ArrayList:(jdk1.2)作为List接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData数组存储
-
LinkedList:(jdk1.2)底层使用双向链表存储,对于频繁的插入删除操作,使用此类效率比ArrayList高
-
Vector:(jdk1.0)作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] elementData存储
-
-
--Set--接口
-
HashSet:作为Set接口的主要实现类;线程不安全,可以存储null值
-
LinkedHashSet:作为HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历
-
-
TreeSet:可以按照对象的指定属性,进行排序
-
-
-
Map接口
-
--HashMap--:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value
-
LinkedHashMap:在原有的HashMap底层基础上,添加了一对指针,指向前一个和后一个数据,对于频繁的遍历操作
-
-
--HashTable--:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
-
Properties:常用来处理配置文件。key和value都是String类型
-
-
--TreeMap--:保证按照添加的key-value对进行排序,实现排序遍历,此时考虑key的自然排序,底层红黑树 HashMap的底层:数组+链表(jdk1.7以及以前) 数组+链表+红黑树(jdk8)
-
1.1.1 Set add元素的过程
-
首先调用a所在类的hashCode()方法,计算元素a的哈希值
-
此哈希值接着通过某种算法计算出在HashSet底层数组中的存在位置(即:索引位置)
-
判断数组此位置上是否已经有元素:
-
如果此位置上没有其他元素,则元素a添加成功。---情况1
-
如果哈希值不相同,则元素a添加成功,使用链表的方式添加 ---情况2
-
如果有哈希值相同,需要调用元素a所在类的equals()方法:
(1)equals()返回true:元素a添加失败
(2)equals()返回false:元素添加成功---情况3
-
-
对于添加成功的情况2和情况3而言:元素a与已经指定索引位置上数据以链表的方式存储 Jdk7:元素放到数组中,指向原来的元素,认为新添加的元素大概率会被再访问 Jdk8:原来的元素在数组中,指向元素a 总结为:“七上八下” HashSet底层:--数据+链表--
1.1.2 重写hashCode和equals方法?
Object类中的hashCode()是随机生成一个哈希值,所以需要重写 向Set中添加的数据,其所在的类一定要重写hashCode()和equals() 重写的hashCode()和equals()尽可能保持一致性,相等的对象必须具有相等的散列码,如果两个对象属性都一样,要保证哈希值一样
1.1.3 HashMap VS HashTable
| HashMap | HashTable | |
|---|---|---|
| 实现Map接口 | ✓ | ✓ |
| 允许key-value为null | ✓ | ✓ |
| 线程安全 | ✕ | ✕ |
| 效率高 | ✓ | ✕ |
| API | containsValue和containsKey | contains |
| 同步 | ConcurrentHashMap | Synchronize修饰 |
| Hash算法 | hash/rehash算法大致一样 | hash/rehash算法大致一样 |
1.1.4 HashMap扩容
默认容量16
扩容2倍
加载因子0.75
--jdk1.7 数组+链表 头插法--
扩容都是针对的数组,先将数组复制一份,数组的容量是原来的两倍,然后将数组中的数据全部转移到新数组中,但是因为jdk1.8中有红黑数的原因,新的数对应位置可能和原始数组中的不一样,因为数的位置是根据数组的大小决定的。大于8是红黑树,小于8是链表
1.先生成新数组
2.遍历老数组中的每个位置上的链表或者红黑树
3.如果是链表,则直接将链表中的每个元素重新计算下标,并添加到新数组中去
4.如果是红黑树,则先遍历红黑树,先计算出红黑树中每个元素对应的新数组的下标位置: (1)统计每个下标位置的元素个数
(2)如果该位置下的元素个数超过了8,那么生成一个新的红黑树,并将根节点添加到新数组的对应位置
(3)如果该位置下的元素个数没有超过8,那么生成一个链表,并将链表的头结点添加到新书的对应位置
5.所有元素转移完成之后,将新数组赋值为HashMap对象的table属性
--为什么从头插法到尾插法?
-
为了安全,防止环化
-
因为需要算一下链表的长度,所以会顺带在尾部插入
注意:
-
jdk1.7中Hash算法比较复杂,想得到位置分布更加均匀一点
-
jdk1.8进行了优化,因为新增了红黑树,提高了插入和查询效率,复杂的hash算法会消耗部分时间
HashMap默认的初始长度==16==,为了可以实现均匀分布
1.1.5 ArrayList扩容
==JDK1.7==
底层创建了长度为10的Object[]数组 elementData
如果此次的添加导致底层elementData数组容量不够,则扩容
默认情况下扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中
(建议开发中使用带参的构造器,可以避免中间操作的扩容,提高效率)
==JDK1.8==
底层创建了Object[] 数组 elementData 初始化为{},并没有创建长度为10的数组
第一次调用add()时,底层才创建了长度为10的数组,并将第一个数据添加到elementData[0]中,后续的添加和扩容操作和jdk7相同
1.1.6 TreeMap的底层数据结构
-
红黑树
-
红黑树的Node排序是根据key进行比较
-
每次新增删除节点,都可能导致红黑树的重排
-
红黑树中不支持两个or两个以上的Node节点对应红黑值相等
-
查询的时间复杂度O(logn)
1.1.7 HashMap遍历方式
通过ForEach循环进行遍历
// Iterating entries using a For Each loop
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
ForEach迭代键值对方式
// 迭代键
for (Integer key : map.keySet()) {
System.out.println("Key = " + key);
}
// 迭代值
for (Integer value : map.values()) {
System.out.println("Value = " + value);
}
使用带泛型的迭代器进行遍历
Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<Integer, Integer> entry = entries.next();
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
使用不带泛型的迭代器进行遍历
Iterator<Map.Entry> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry entry = (Map.Entry) entries.next();
Integer key = (Integer) entry.getKey();
Integer value = (Integer) entry.getValue();
System.out.println("Key = " + key + ", Value = " + value);
}
通过Java8 Lambda表达式遍历
map.forEach((k, v) -> System.out.println("key: " + k + " value:" + v));
1.1.8 ArrayList VS LinkedList
--LinkedList--
-
底层:链表,可以在分散的内存
-
不适合查询
-
适合增删
--ArrayList--
-
底层:动态数组,连续内存存储
-
适合下标访问(随机访问)
-
添加慢(因为扩容的时候需要新建一个双倍大小的数组,把旧元素放入到新数组中)
1.LinkedList和ArrayList的底层数据结构不同,ArrayList底层是基于动态数组实现的,LinkedList底层是基于链表实现的
2.因为两者的底层数据结构不同,适用场地也不同,ArrayList更适合随机查找,LinkedList更适合删除和添加
3.ArrayList和LinkedList都实现了List接口,但是LinkedList还额外实现了Deque接口,所以LinkedList还可以当作队列来使用
1.1.9 CopyOnWriterArrayList
ArrayList是线程不安全的:并发add的时候,同时进入add,但是后线程覆盖了前线程添加的数据
1.首先CopyOnWriterArrayList的内部也是用数组来实现的,在向CopyOnWriterArrayList添加元素的时候,会复制一个数组
2.写操作会加锁,防止出现并发写入丢失数据的问题
3.写操作结束之后会把原数组指向新数组
4.CopyOnWriterArrayList允许在写操作时来读取数据,大大提高了读的性能,因此适用读多写少的应用场景,但是CopyOnWriterArrayList会比较占用内存,同时可能读到的数据不是实时最新的数据,所以不适合实时性要求很高的场景
1.1.10 ConcurrentHashMap扩容
远景智能
ConcurrentHashMap一个并发容器,在多线程开发中经常会使用到这个类,它与HashMap的区别时HashMap是线程不安全的,在高并发的情况下,使用HashMap进行大量变更操作容易出现问题,但是ConcurrentHashMap是线程安全的
由很多个Segment对象组成ConcurrentHashMap,扩容是针对每个Segment内部而言的
-
1.7版本的ConcurrentHashMap是基于Segment分段实现的
-
每个Segment相对于一个小型的HashMap
-
每个Segment内部会进行扩容,和HashMap的扩容逻辑类似
-
先生成新的数组,然后转移元素到新数组中
-
扩容的判断也是每个Segment内部单独判断的,判断时否超过阈值
JDK1.8
-
1.8版本的ConcurrenthashMap不再基于Segment实现
-
当某个线程进行put时,发现ConcurrentHashMap正在进行扩容那么该线程一起进行扩容
-
当某个线程进行put时,发现没有正在进行扩容,则将key-value添加到ConcurrentHashMap中,然后判断是否超过了阈值,超过阈值则进行扩容
-
ConcurrentHashMap支持多线程扩容
-
扩容之前也先 生成一个新的数组
-
在转移元素之前,先将原数组分组,将每组分给不同的线程进行元素的转移,每个线程负责一组或者多组的元素转移工作。每个线程之间互相不干扰
==ConcurrentHashMap原理==
HashTable是使用synchrozied锁整个Map
JDK1.7
-
数据结构:ReenTranLock分段锁+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表的结构
-
元素查询:二次hash,第一个Hash定位到Segment,第二次Hash定位到元素所在的链表的头部
-
锁:Segment分段锁 Segment继承了ReentranLock,锁定操作的Segment,其他的Segment不受影响,并发度为segment个数,可以通过构造函数指定,数组扩容不会影响其他的Segment
-
get方法无需加锁,volatile保证
JDK1.8
-
数据结构:synchronized+CAS+Node+红黑树,Node的val和next都用volatile修饰,保证可见性
-
查找、替换、赋值操作都使用CAS
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
