首页 > 基础资料 博客日记
JVM系列——垃圾收集(1)
2025-11-13 16:00:02基础资料围观590次
https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html
https://www.bilibili.com/video/BV1US4y1m7if/?spm_id_from=333.337.search-card.all.click&vd_source=99ec55b57f4eeedd9ed62c43e87cb6ff

什么是虚拟机
java分配了内存之后,自己是不要进行回收的。c和c++要手动回收,会出现重复回收或忘记回收。
虚拟机层面做了一个自动化回收,有10种。java1.8默认的是PS和PO。1.9之后默认G1。
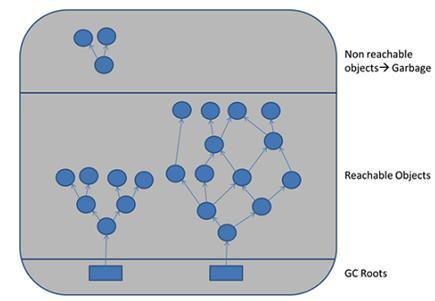
java中定位内存里什么是垃圾用的方法是Root Searching根可达,只要顺着“小线团“能找到的都不是垃圾。
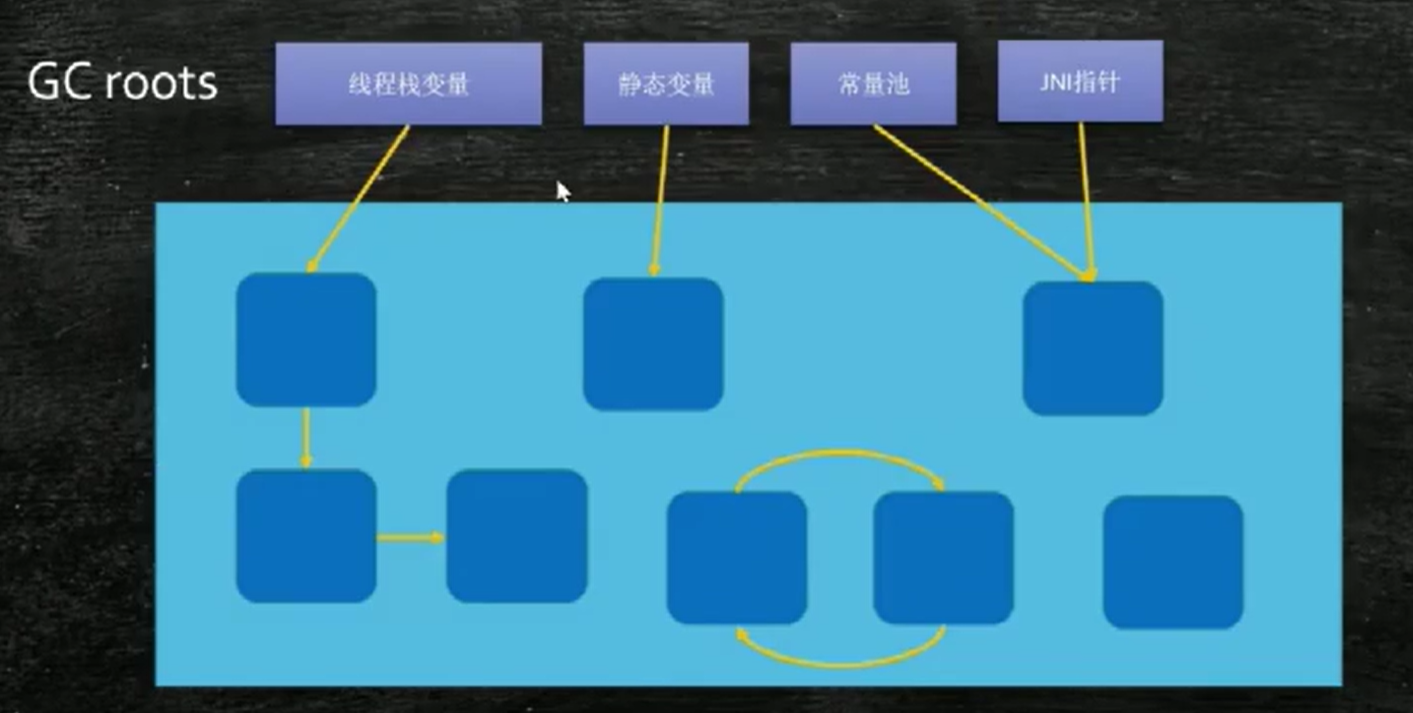
什么是GC Roots?main里面的用到的一定有用。
一个对象怎么才能知道它是一个垃圾?在一个对象顶上写一个reference count引用计数,如果有其他人引用他则肯定不是垃圾,当一个引用消失,数量就-1。但这种方式有bug,循环引用。在java中我们用了另一种方法定位Root Searching根可达算法,一个方法是从main方法开始运行,在main里面,new出来的对象(如list,list里面又可以装很多对象),顺着这个根对象往下找,若有些没找到的就是垃圾。
垃圾回收算法:标记清除(碎片化)、拷贝(内存浪费)、标记压缩。
- 标记清除:找出来哪些是垃圾,直接清除,变为可用。简单,但会有内存碎片。
- 拷贝算法:不管内存多大,把内存分成两半,每次只使用一半,从在使用的一半里面把活对象拷贝到另一半,然后把原本的区域全部清空。两边轮流使用。没有内存碎片,但浪费了很多空间。
- 标记压缩:既不产生碎片,又不浪费空间。先标记,然后把活的整理到最前面,然后把后面的都清除。但是效率很低,挪来挪去。
GC的演化是随着内存的变大而改变。
- 几兆-几十兆:serial单线程STW垃圾回收,年轻代、老年代
- 几十兆-上百兆1G:parallel并行多线程
- 几十G:concurrent GC
一个垃圾回收器的设计是综合这三种垃圾回收算法。
1.8里面用的最多的是分代管理方法,STW是毫秒级。
堆内存逻辑分区分为新生代和老年代(大约为1:2的比例,默认),当一个对象诞生的时候,优先在新生代做分配,每个对象会经历很多次的垃圾回收。那些经历了很多次垃圾回收都回收不掉的就移到老年代去。等老年代装满了就会有针对老年代具体的垃圾回收方法。
JVM调优调的是用各种参数指定这两个区域的比例。越新的垃圾回收器调优越简单,但理论就会复杂些。
那年轻代到多少年龄之后就会挪到老年代呢?这个跟使用的垃圾回收算法相关,默认是PS+PO,年龄是15,如果有改动为CMS,年龄为6,G1没有年龄这个概念因为不分代了。-XX:MaxTenuringThreshold配置
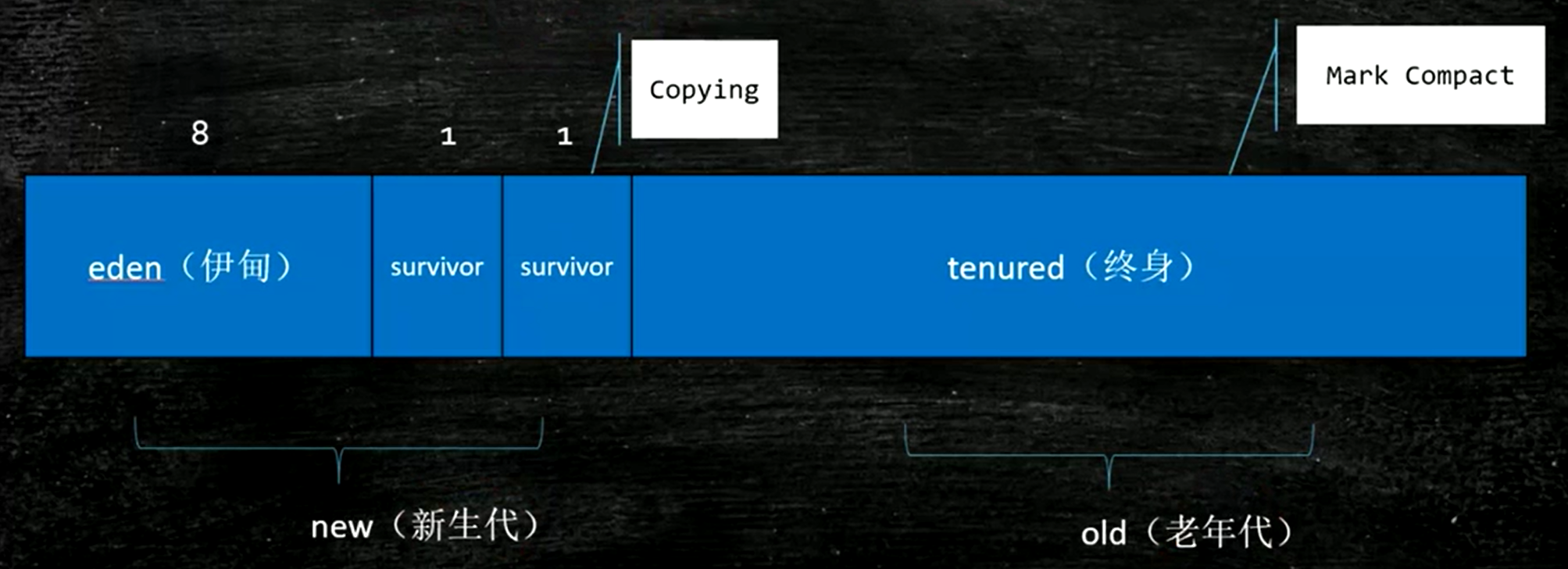
伊甸园区:新创建的对象都放在这。假如现在在伊甸园区有10个对象,经过一次垃圾回收YGC之后干掉了9个,那么仅剩的那一个怎么处理?这个对象会被复制到一个survivor,这样伊甸园区可以整体清除(效率高)。然后下一次在伊甸园区又产生了一些垃圾,然后跟前面类似的做法进行一次YGC,将伊甸园区活着的对象和survivor1中活着的对象移到survivor2中,然后将eden和survivor1全部清除。不能移动而是复制。下一次就将活的复制到survivor1中。这两片幸存者空间肯定有一块是空的。
YGC(发生在年轻代的GC)+LGC(发生在老年代的GC)=FullGC。
那如果survivor不够大了怎么办?默认的eden和survivor的比例是8:1:1。YGC的要求就是效率高。用复制算法(在新生代区):统计学结果发现YGC一般能回收掉90%的对象。原本的复制算法是预留一半的内存,但这样会浪费,新的方法就不预留那么多的空间。
在分代的基础上产生了6种垃圾回收器:Serial、ParNew、Parallel Scavenge(YGC)、CMS、Serial Old、Parallel Old(OGC)。
Serial:只有一个人来帮你回收垃圾。STW是不可避免的。
STW:业务线程不能动,等垃圾回收完了之后才可以继续主线程。
虚拟机追求:吞吐量、响应时间(我们要关注的)。
随着内存变大,serial就不太行了。Parallel Scavenge:多线程,但线程数不是越多越好,因为有线程切换过程。到一定的阈值的时候,诞生了一种并发垃圾回收CMS。
CMS(Concurrent Mark Sweep):由于响应时间越来越高。响应时间长的可能会到2天多。就是在运行业务线程的时候不用STW,与此同时会有垃圾回收器帮你回收垃圾。
怎么知道是在GC?传统的方式是日志,监控,JDK14(JFR java事件流)
CMS可以升级成G1(1.8以上)。
java中最复杂的垃圾回收器的算法:三色标记法。
- 黑色:自己和孩子都找到了
- 灰色:孩子没找全
- 白色:完全没找到
老年代不能在全部满了之后才启动垃圾回收,有参数可以设置达到多少比例就启动,以前有默认比例是90%,但是这时候已经晚了。当老年代空间满了之后会启动STW,用单线程去进行垃圾回收。
第一种情况:A-B引用消失
第二种情况:B-D消失 A-D增加。通过A找不到D,B又找不到D。所以D在垃圾回收器视角看起来就是垃圾(因为A是黑色),但这里如果垃圾回收器把这个D删除了,那会发生空指针异常。
CMS解决方案:如果发生了情况二,那就把黑色A标为灰色,这样垃圾回收器就会找A的孩子。但这个方案有个bug,就是xxx。CMS最后有一个阶段叫做remark。
CMS中有浮动垃圾,而且在remark阶段会有STW,在业务很复杂的时候时间可能很长。
G1:SATB,有一个灰的对象在运行过程中指向白的引用消失了,把这个引用记录在栈里面。当垃圾回收线程回来时,只要看在那个栈中有没有新记录诞生,然后就扫一下看有没有其他对象引用这个白的,如果没有的话就是垃圾。
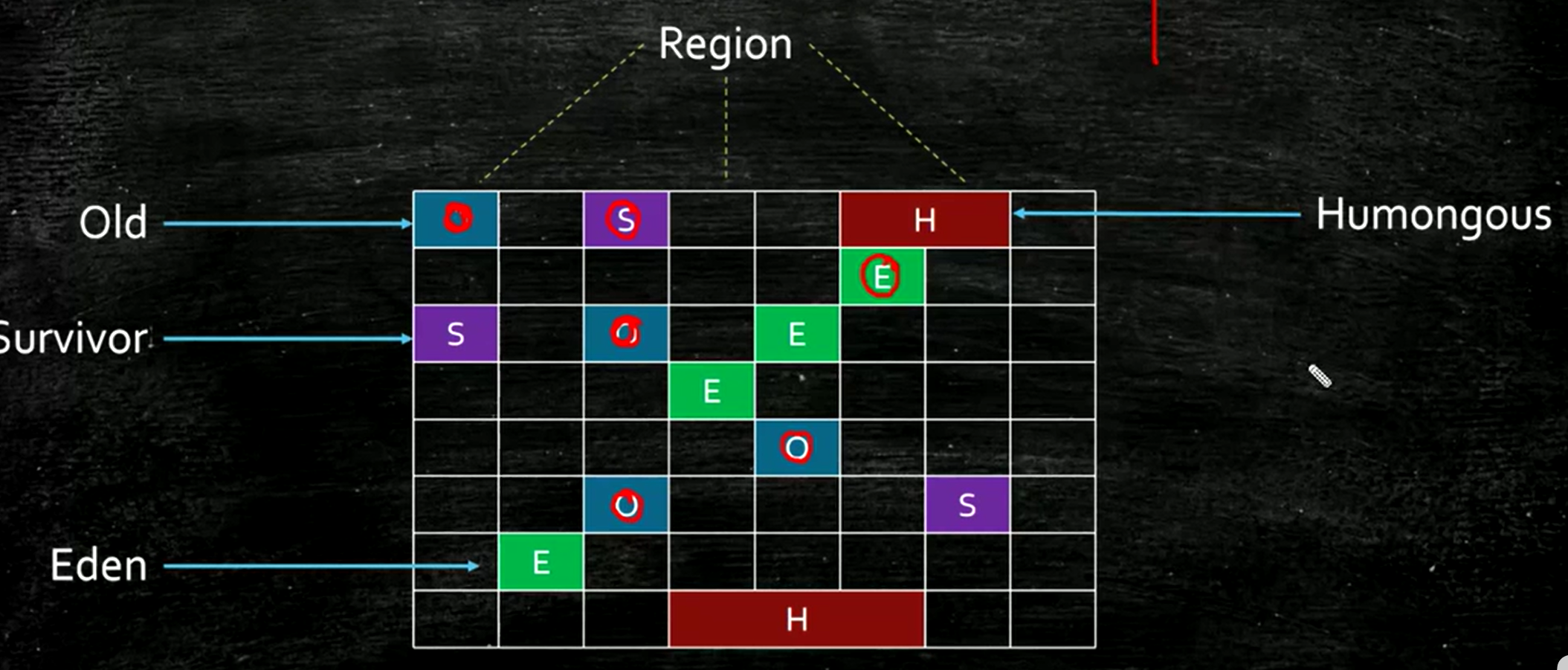
G1:在物理上分区,在逻辑上分代。ZGC:纯分区,不分代。在某个区域不够用的时候,可以把它动态置为其他的区域,比如新生代产生很快的话可以把清空了的区域指定为伊甸园区。
G1追求吞吐量和响应时间(XX:MaxGCPauseMillis 200),对STW进行控制。灵活,分region回收,优先回收花费时间少、垃圾比例高的Region。
G1一般不用手动指定新老年代比例,如果你精确地掌握程序就可以修改,否则不建议修改。G1预测停顿时间的基准。我们只需指定需要将STW控制在多少,而不需要管里面具体的细节。
工作之后用的JVM版本大多是1.8,默认的垃圾回收器是并行垃圾回收器。目前垃圾回收器可以分为两大类,一类是分代模型,两个垃圾回收器混合使用;二类是分区模型。
java -XX:+PrintCommandLineFlags -version 会显示默认垃圾回收器。
jvm调优:在启动了java虚拟机之后,进行一系列参数的指定,让jvm运行在最佳状态。作为java虚拟机,有多少参数可以调节呢?标准参数10-20个,非标参数有几十个。常用的有-xmx,-xms。还有不稳定参数,每个垃圾回收器是不同的参数来控制,-XX:PrintFlagsFinal | more,参数非常多,728行。
Serial和SerialOld成对使用,Serial在年轻代使用(复制算法)、SerialOld在老年代使用(标记清除或标记整理),但现在已经不用了,特点是简单,但问题是效率很低,随着内存变大,STW时间很长。
Parallel Scavenge和 Parallel Old成对使用,解决小内存的问题。但线程不能太多,线程切换有很大开销。
JVM调优实战
涉及到三个层面,根据需求进行JVM规划和预调优(多大的并发量、峰值到多少,使用什么垃圾回收器,多大内存等);第二个是优化运行JVM运行环境(慢卡顿,游戏服务器经常遇到);第三个是解决JVM运行过程中出现的各种问题(OOM)
举个例子:金融领域风险控制模型,使用了线程池进行风险控制模型的计算。
(GC的日志)java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problen01, 最大内存200M,最小内存200M,为什么设置为一样的?因为这样会使得这个空间弹性扩缩容,会消耗系统的时间。
常用工具:1)linux自带的命令和JDK自带的命令 2)使用专业的工具阿尔萨斯(阿里) 3)图形界面远程连接 JProfile、Jconsole,离线MAT
jps:看看有哪些进程,会列出线程号和线程名。
top -Hp 1574:把1574进程里所有线程列出来,线程占的cpu和内存。
jstack 1574:把程序中所有的线程列出来,如哪个线程产生了死锁,哪个线程在玩命地消耗cpu、哪个线程阻塞了(阻塞在某一把锁上面,状态是waiting)
阿尔萨斯:装在服务器上,这个工具一旦启动后就会找到系统中正在跑的java进程。
dashboard:看看有哪些进程,线程占的cpu和内存都列出来。
thread:把所有线程列出来,假如发现47号线程消耗cpu很多,Thread 47可以查看线程的调用栈。
定位上面那个例子产生的问题:用jdk自带的命令:jmap -histo 1574 | head -20,有哪些对象在占用内存列出来,这里会观察到有一个bigdecimal的对象在疯狂占用内存。再执行几次这个命令,这个对象占用内存会越来越多。

第一次清理了40M左右,后面之清理了15M,说明还有好多没有清理掉。然后等这个日志,发现越到后面清理的越来越少,因为对象往这里一直丢对象,已经清理不出空间了,后面会发生频繁Full GC,内存泄露,中间会出现out of memory error,这样阿尔萨斯就会断掉。剩下的就是读自己的业务逻辑,为什么这个类在不断产生。
Java 垃圾回收(Garbage Collection, GC)机制详解
一、什么是虚拟机与垃圾回收
Java 程序运行在 Java 虚拟机(JVM)上,JVM 提供了自动内存管理机制,也就是垃圾回收(GC)。相比 C/C++ 的手动内存管理,Java 免去了手动回收内存带来的烦恼,减少了重复回收或忘记释放等问题。
二、什么是垃圾?如何识别垃圾?
在 Java 中,判断一个对象是否是“垃圾”,核心机制是:GC Roots 可达性分析(Root Searching)。
1. GC Roots 是什么?
GC Roots 是一组特殊的对象引用集合,是垃圾回收的“起点”。如下内容属于 GC Roots:
-
栈帧中的局部变量(如 main 方法中的对象)
-
静态变量
-
常量池中的引用
-
Native 方法中的引用
-
正在运行的线程对象
2. 判断垃圾的方法
-
引用计数法(Reference Counting)
为对象维护一个引用计数,有引用+1,引用消失-1,为0即为垃圾。
缺点:无法处理循环引用,因此 Java 不采用此方法。
-
可达性分析法(Reachability Analysis)
从 GC Roots 出发,向下递归查找能访问到的对象链,如果某个对象无法从任何 GC Roots 到达,就认为是垃圾。
三、常见垃圾回收算法
1. 标记-清除算法(Mark-Sweep)
-
标记:标记出所有可达对象
-
清除:清除未被标记的对象
-
优点:实现简单
-
缺点:会产生内存碎片
2. 复制算法(Copying)
-
把内存分为两块,一次只用一半,把活的对象复制到另一块
-
优点:无碎片,效率高
-
缺点:浪费内存(只有一半能用)
3. 标记-整理算法(Mark-Compact)
-
标记活对象 → 把它们压缩到堆的一端 → 清除其他对象
-
优点:无碎片
-
缺点:效率低,挪动对象开销大
四、JVM 内存分区与分代回收
1. 堆内存逻辑划分
-
新生代(Young Generation):Eden + Survivor (S0/S1),使用复制算法
-
老年代(Old Generation):使用标记-整理或标记-清除算法
2. 新生代工作机制(YGC)
-
新生代空间比例约为 Eden:Survivor1:Survivor2 = 8:1:1
-
Eden 中创建新对象 → YGC 后将存活对象复制到 S1
-
下一次 GC 将 Eden + S1 存活对象复制到 S2
-
交替使用,始终有一个 Survivor 是空的
3. 老年代回收(OGC)
-
对象在 Survivor 中达到一定年龄(默认 15,CMS 是 6),会被晋升到老年代
-
老年代空间不足时触发 Full GC
4. Full GC = YGC + OGC
Full GC(完全垃圾回收)是指:对整个堆空间(包括新生代和老年代)进行的一次全面清理操作。相比 YGC(仅回收新生代),Full GC 代价更高,会触发 Stop-The-World(STW)暂停整个应用线程,因此必须理解它的触发机制,避免频繁发生。
下面是 JVM 中最常见的几种 Full GC 触发条件:
| 触发条件 | 说明 |
|---|---|
| 1. 老年代空间不足 | 新生代晋升对象或直接分配到老年代,发现放不下时 |
2. 显式调用 System.gc() |
会尝试触发 Full GC(默认行为) |
| 3. CMS 回收失败 | Concurrent Mode Failure:CMS 并发回收没腾出足够空间 |
| 4. 元空间(Metaspace)不足 | JDK 8+ 元空间爆满,无法加载新类,触发 Full GC |
| 5. G1 回收预测失败 | G1 无法满足暂停时间预测,选择进行 Full GC |
| 6. 大对象直接进入老年代 | 导致老年代空间吃紧,触发 OGC,再带动 Full GC |
那怎么样实操触发Full GC?
方法1:设置内存限制+持续分配对象。
java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:gc.log GCFullExample
import java.util.ArrayList; public class GCFullExample { public static void main(String[] args) { ArrayList<byte[]> list = new ArrayList<>(); while (true) { list.add(new byte[1024 * 1024]); // 每次分配 1MB try { Thread.sleep(100); // 降低频率便于观察 } catch (InterruptedException e) { e.printStackTrace(); } } } }
-
初始创建对象在 Eden
-
多次 YGC 后,有部分对象晋升到老年代
-
老年代空间不够了 → 触发 Full GC
怎么在日志中看 Full GC?
[Full GC (Ergonomics) ...]
[Full GC (System.gc()) ...]
[Full GC (Allocation Failure) ...]
你可以使用 -Xloggc:gc.log 保存日志,再上传到 https://gceasy.io 分析图表。
五、常见 GC 回收器
1. Serial / Serial Old 收集器(单线程,Client 默认)
-
新生代使用复制算法,老年代使用标记整理算法
-
优点:实现简单,单线程高效
-
缺点:停顿时间长,STW 明显
-
参数:
-XX:+UseSerialGC
2. ParNew 收集器(新生代多线程)
-
ParNew 是 Serial 的并行版,仅适用于新生代
-
常与 CMS 搭配使用
-
参数:
-XX:+UseParNewGC
3. Parallel Scavenge / Parallel Old(吞吐量优先)
-
全部并行:新生代和老年代都多线程并行回收
-
特点:关注高吞吐量,适合后台任务
-
参数:
-XX:+UseParallelGC、-XX:+UseParallelOldGC
4. CMS(Concurrent Mark Sweep)
-
CMS(Concurrent Mark Sweep)回收器采用 标记-清除算法,它的核心目标是 减少停顿时间,尤其适合对响应时间敏感的大型服务端应用。CMS 老年代的回收过程分为以下四个阶段:
- 初始标记:STW阶段,只标记GC Roots可达的第一层对象。标记工作量小,因此暂停时间短。
- 并发标记:与应用线程并发执行,从初始标记的对象继续向下扫描对象图,找出可达对象。这个过程时间较长,但不影响用户线程运行。
- 重新标记(remark):CMS中最重要的STW阶段之一!修正并发标记阶段遗漏的标记变更,因为在并发标记过程中,用户线程可能新增了对象引用,这可能会导致某些对象在并发标记中被误判为垃圾。为确保准确性,CMS需要在这一步对所有”发生引用变动“的对象进行再次扫描。技术上使用”增量更新:写屏障机制来记录这些变动。
-
这一阶段如果对象图很复杂(引用关系多、写入频繁),remark 停顿时间可能较长,甚至几百毫秒以上
-
是 CMS 最大的短板
-
- 并发清除:与并发线程并发执行,清除所有在标记阶段未被标记的对象(垃圾),不做对象移动,因此可能会产生内存碎片。
-
缺点:容易产生碎片,有失败回退(触发 Serial Old)
-
参数:
-XX:+UseConcMarkSweepGC - 最后一个阶段是remark,
5. G1(Garbage First)
-
JDK 9+ 默认回收器,逻辑分代+物理分区
-
支持预测最大停顿时间(
-XX:MaxGCPauseMillis),我们只需告诉它我们的需求(比如100ms内完成垃圾回收),G1会自动去执行。 -
优先回收垃圾比例高、耗费时间短的 Region,效率高。
6. ZGC(Z Garbage Collector)
-
JDK 11+ 引入的超低延迟 GC,GC 停顿通常 <10ms
-
分区式、并发、压缩型 GC
-
适合大内存、高响应需求场景
-
参数:
-XX:+UseZGC
7. Shenandoah
-
RedHat 提供的并发低延迟 GC,JDK 12+ 开始支持
-
类似 ZGC,主打并发、低 STW 时间
-
参数:
-XX:+UseShenandoahGC
六、JVM 调优与工具
1. JVM 调优层面
-
根据系统并发量、响应时间,选择合适的 GC 回收器和参数
-
调整堆大小比例(-Xms,-Xmx,-XX:NewRatio,-XX:SurvivorRatio)
-
设置 Full GC 触发阈值(-XX:InitiatingHeapOccupancyPercent)
2. 常用调试命令
-
jps:查看所有 Java 进程 -
jstack pid:查看线程栈,定位死锁、阻塞 -
jmap -histo pid:查看对象占用内存情况 -
jmap -dump:file=heap.bin:生成堆快照 -
top -Hp pid:查看每个线程 CPU 占用
3. 可视化工具
-
VisualVM:查看 GC 活动、堆内存、线程等
-
JConsole / JFR:监控实时性能
-
MAT:分析堆转储文件(heap dump)
-
阿里 Arthas:排查运行中问题
七、GC 日志与诊断
常用参数
-Xms512M -Xmx512M -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
可上传 gc.log 到 gceasy.io 自动分析
八、三色标记法(Tri-Color Marking)
现代并发垃圾回收器(如 CMS、G1、ZGC)在可达性分析中广泛采用三色标记法,帮助在并发标记阶段准确判断哪些对象可达、哪些是垃圾。
三种颜色含义:
-
白色(White):初始状态,表示“可能是垃圾”
-
灰色(Gray):已被标记为可达,但它引用的对象还没扫描完
-
黑色(Black):已被标记为可达,且它引用的对象也都扫描完
标记流程:
-
所有对象初始为白色;
-
从 GC Roots 开始,把直接可达对象标记为灰色;
-
每处理一个灰色对象,就把它变成黑色,并将它引用的对象(若是白色)也变成灰色;
-
最终,未被染成黑或灰的白色对象就是不可达的垃圾。
写屏障与增量更新:
在并发标记过程中,用户线程可能会修改对象引用(比如把一个对象 A 指向了新对象 B)。此时垃圾回收线程可能还没扫描 A,从而“错过”了 B。
为解决这个问题,引入写屏障机制,主要有:
-
增量更新(Incremental Update):记录“黑对象引用了白对象”,重新标记
-
SATB(Snapshot-At-The-Beginning):记录“原始引用”,忽略新引用变化
G1 使用 SATB,CMS 使用增量更新。
总结
-
Java 使用 GC Roots 可达性分析来判断对象是否可以回收
-
主流算法包括:标记清除、复制、标记整理
-
分代策略下,采用不同算法适配不同生命周期的对象
-
常见回收器有 Serial、Parallel、CMS、G1、ZGC 等
-
可通过日志、工具、命令结合调优 GC 表现,排查内存问题
引用:
https://www.cnblogs.com/xdcat/p/13040725.html
马士兵
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
上一篇:Java算法题常用函数
下一篇:微服务/分布式 基础面试题
相关文章
最新发布
点击排行
本站推荐
