首页 > 基础资料 博客日记
【学习OR面试】HashMap
2025-06-26 14:00:02基础资料围观426次
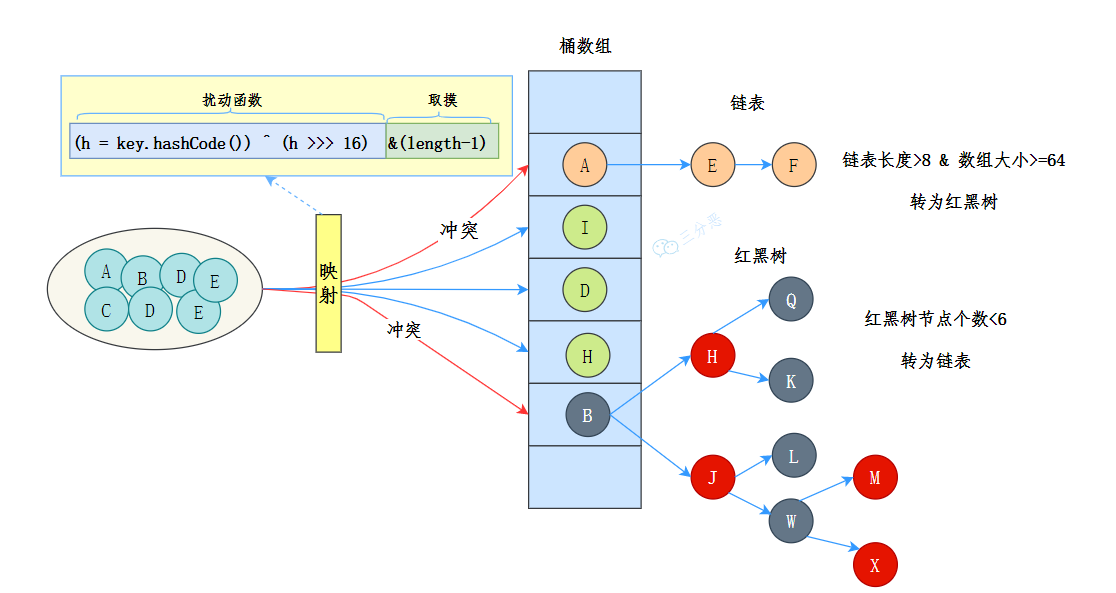
1.HashMap的结构特点
- 结构:桶数组 + 链表 / 红黑树
- 转换时机:(3点)
- 当链表的长度超过8 时且桶数组的长度大于等于 64,链表就会转换为红黑树。
- 当链表长度超过8,但是桶数组长度没有到达64,优先扩容,提升桶数组长度。
- 当红黑树节点 ≤ 6 时,红黑树退化为链表。
- 链表的查找时间复杂度是
O(n),当链表长度较长时,查找性能会下降。红黑树是一种折中的方案,查找、插入、删除的时间复杂度都是O(log n)。
2.红黑树的简单介绍
一种自平衡二叉查找树,但是条件没平衡二叉树那么严格。
5点
-
每个节点要么是红色,要么是黑色;
-
根节点永远是黑色;所有的叶子节点都是是黑色的(NULL 节点);
-
红色节点的子节点一定是黑色的;
-
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。( 不走回头路)
-
任意一条路径不会超过另一条路径的两倍长度。
对比平衡二叉树:
- AVL树查,插,删也是
O(log n)。但是查找更快,树高度更矮;插入删除更慢,需要处理更多的旋转(红黑树需要的做法是旋转与染色)。
3.HashMap的扩容【重点】
- 首先, HashMap 的容量是 2 的幂次方,目的:将取模运算
hash % table.length优化为位运算hash & (length - 1)。 - 扩容是看总表的所有节点数,不是单看链表或者桶数组;时间复杂度为
O(n)。 - 扩容一般是扩容为原来的2倍,不需要重新 hash ,只需要判断
hash & oldCap == 0就可以知道键在新数组中的位置。这里的Cap是桶数组大小。
扩容的三种情况:
-
单个节点:
indexNew = hash & (newCap - 1),相当于取模运算。 -
链表:遍历链表,将链表拆分为两个链表
- 低位链表(Lo) :
hash & oldCap == 0→ 保留在原位置。 - 高位链表(Hi) :
hash & oldCap != 0→ 移动到原位置 + oldCap的位置。
- 低位链表(Lo) :
-
红黑树结构
- 如果当前桶是一个红黑树(TreeNode),HashMap 会调用
split()方法进行分裂。 - 分裂后的红黑树如果节点数 ≤ UNTREEIFY_THRESHOLD(默认 6),会退化为链表。
- 如果当前桶是一个红黑树(TreeNode),HashMap 会调用
-
举例:
8的二进制为1000,扩容后16的二进制为10000,那么newCap-1的二进制为1111。
indexNew = hash & (newCap - 1):相当于保留二进制的低四位,也就是0-15,相当于取模。hash & oldCap:hash&1000,相当于把桶数组分为了两半,0-7旧的部分 | 8-15 新的部分。当低四位中的第四位不是1,那么就在旧的部分也就不需要迁移,需要迁移的情况就是
原位置 + oldCap。
扩容后顺序是否变化?比如链表a->b->c拆分为(ac|b)后出现c->a
- JDK 7 在扩容的时候使用头插法来重新插入链表节点,这样会导致链表无法保持原有的顺序。(头插法性能高,不用遍历)
- JDK 8 改用了尾插法,并且当
(e.hash & oldCap) == 0时,元素保留在原索引的位置;否则元素移动到原索引 + 旧数组大小的位置。
4.HashMap的put流程【重点】
哈希寻址(123) → 处理哈希冲突(链表还是红黑树)插入/覆盖节点(45)→ 判断是否需要扩容(67)
-
扰动哈希:先拿到 key 的哈希值,是一个 32 位的 int 类型数值,然后再让哈希值的高 16 位和低 16 位进行异或操作,这样能保证哈希分布均匀。
- (补充:哈希表的索引是通过
h & (n-1)计算的,相当于截取了最低的四位。只取 h 的低位很容易导致哈希冲突。通过异或操作将 h 的高位引入低位,可以增加哈希值的随机性,从而减少哈希冲突。)
- (补充:哈希表的索引是通过
-
判断table是否为null或空,是的话进行首次分配;并使用哈希值和数组长度进行取模运算,确定索引位置。
- 这里有一个懒加载,
HashMap在初始化时,并不会立即创建存储键值对的数组。 - 只有当第一次调用
put()、get()等方法时,才会触发数组的初始化。
- 这里有一个懒加载,
-
value相同则覆盖,不同则代表哈希冲突插入链表尾部,当条件达到后,链表转换为红黑树。
-
判断是否需要扩容:大于``capacity * loadFactor`,总容量*负载因子(默认为0.75)。
-
新建桶数组容量为原来的2倍,进行扩容。
HashMap.put(k, v)
1. 计算扰动 hash 值(h = hash(k) ^ (h >>> 16))
2. 判断 table 是否为空,若为空则初始化
3. 计算桶索引 index = (n - 1) & hash
4. 若无冲突:直接插入
5. 若冲突:
- 若 key 已存在:替换
- 否则插入链尾
- 若链表 > 8 且 table ≥ 64:转红黑树(插入链表后再转换为红黑树)
6. 插入完成后:size++
7. 判断是否 > threshold?若是:resize(扩容)
5.JDK 8 对 HashMap 做了哪些优化呢?
- 结构:由数组 + 链表改成了数组 + 链表或红黑树
- 插入方式:由头插法改为了尾插法。头插法在扩容后会改变原来链表的顺序。
- 扩容时机:扩容的时机由插入时判断改为插入后判断。
- 哈希扰动算法优化:JDK 7 是通过多次移位和异或运算来实现的。JDK 8 让 hash 值的高 16 位和低 16 位进行了异或运算。
4点
6.对比一下 LinkedHashMap、TreeMap
-
LinkedHashMap 在 HashMap 的基础上维护了一个双向链表,通过 before 和 after 标识前置节点和后置节点。
保持插入顺序。
-
TreeMap 通过 key 的比较器来决定元素的顺序,如果没有指定比较器,那么 key 必须实现 [Comparable 接口]。底层是红黑树,类比二叉排序树实现顺序访问。
-
TreeMap的key不允许出现NULL,因为NULL无法比较,其它两个可以。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
