首页 > 基础资料 博客日记
完美解决html2canvas + jsPDF导出pdf分页内容截断问题
2024-10-11 05:00:06基础资料围观821次
代码地址:https://github.com/HFQ12333/export-pdf.git
html2canvas + jspdf方案是前端实现页面打印的一种常用方案,但是在实践过程中,遇到的最大问题就是分页截断的问题:当页面元素超过一页A4纸的时候,连续的页面就会因为分页而导致内容被截断,进而影响了pdf的可读性。
由于网上关于分页截断的解决思路比较少,所以特意将此次的解决方案记录下来。
使用 JSPDF 和 html2canvas 创建简单的 PDF文件
首先,我们开始使用 JSPDF 和 html2canvas 生成一个简单的 PDF文件。
创建一个 JSPDF 实例
创建一个 JSPDF 实例,设置页面的大小、方向和其他参数。参考官网可以写一个很简单的实例
var doc = new jsPDF({
orientation: 'landscape',
unit: 'in',
format: [4, 2]
}
doc.text('Hello world!', 1, 1)
doc.save('two-by-four.pdf')生成一个pdf文件,并且在文件中写入一定内容,其实JSPDF这个库就能做到。
但是很多业务场景下,我们的目标内容会更复杂,而且还要考虑样式,所以最好的方式是引入html2canvas这个库,将页面元素转换成base64数据,然后贴在pdf中(使用addImage方法),这样就能保证页面的内容。
引入了html2canvas库后,我们更多关注是利用现成组件库、框架或者原生html和css实现更复杂的页面内容。
引入 html2canvas
使用 html2canvas 捕捉 HTML 内容或特定的 HTML 元素,并将其转换为 Canvas。其中,html2canvas 函数的主要用法是:
html2canvas(element, options);element: 要渲染为 canvas 的 HTML 元素。这可以是一个 DOM 元素,也可以是一个选择器字符串,表示需要渲染的元素。options(可选): 一个包含配置选项的对象,用于定制html2canvas的行为。
以下是一些常见的配置选项:
allowTaint(默认值:false): 是否允许加载跨域的图片,默认为false。如果设为true,html2canvas将尝试加载跨域的图片,但在某些情况下可能会受到浏览器的限制。backgroundColor(默认值:#ffffff): canvas 的背景颜色。useCORS(默认值:false): 是否使用 CORS(Cross-Origin Resource Sharing)来加载图片。如果设置为true,则html2canvas将尝试使用 CORS 来加载图片。logging(默认值:false): 是否输出日志信息到控制台。width和height: canvas 的宽度和高度。如果未指定,则默认为目标元素的宽度和高度。scale(默认值:window.devicePixelRatio): 缩放因子,决定 canvas 的分辨率。
下面是一个简单的demo,可以看到html2canvas能够将dom元素转化为一张base64图片,将鼠标选中元素,可以感受到图片和文字的不同。
<div id="capture" style="padding: 10px; background: #f5da55">
<h4 style="color: #000; ">Hello world!</h4>
</div>
html2canvas(document.querySelector("#capture")).then(canvas => {
document.body.appendChild(canvas)
});
将html2canvas转化的图片放到pdf中
这一步我们需要使用JSPDF 的addImage方法,其语法如下:
addImage(imageData, format, x, y, width, height, alias, compression)imageData- 要添加的图像数据。可以是图像的 URL、图像的 base64 编码字符串或图像的二进制数据format- 图像的格式。可以是 "JPEG"、"PNG" 或 "TIFF"。x- 图像在 PDF 文档中的 x 坐标。y- 图像在 PDF 文档中的 y 坐标。width- 图像的宽度。height- 图像的高度。alias- 图像的别名。此别名可用于在 PDF 文档中引用图像。compression- 图像的压缩级别。可以是 "NONE"、"FAST" 或 "SLOW"。
下面是一串示例代码:
import jsPDF from 'jspdf';
export default function addImageUsage() {
const doc = new jsPDF();
const imageData = 【替换成base64数据流】;
doc.addImage(imageData, 'png', 0, 0, 10, 10);
doc.addImage(imageData, 'png', 100, 100, 10, 10);
doc.addImage(imageData, 'png', 200, 200, 10, 10);
drawNet(doc);
doc.save('test.pdf');
}
const drawNet = (doc) => {
const gap = 10;
const start = [0, 0];
const end = [595.28, 841.89];
// 所有横线
for (let i = start[0]; i < end[0]; i = i + gap) {
doc.line(i, 0, i, end[0]);
}
// 所有纵线
for (let j = start[1]; j < end[1]; j = j + gap) {
doc.line(0, j, end[1], j);
}
};此示例将在 PDF 文档(默认是A4纸大小,宽高为[595.28, 841.89]像素)的 (10, 10) 、(100, 100) 、(200, 200) 坐标处,添加一张png 图像。图像的宽度和高度将分别为 10 和 10 像素,为了了解pdf中的坐标系统,此示例还在pdf文档中生成了间距为10px的网格系统。

JSPDF 和 html2canvas结合起来用
了解了上面的三个关键点,接下来我们将这三个步骤串联起来,实现一个基本的html→pdf的方案。大致步骤如下:
- 写一个基本
html页面 - 创建
jspdf实例 - 获取页面的dom节点,使用
html2canvas将其转化为base64数据流 - 将
base64数据流装载到jspdf提供的addImage方法中 - 保存
pdf
基于这5个步骤,可以实现基本的页面打印。
import html2canvas from 'html2canvas';
import jsPDF, { RGBAData } from 'jspdf';
// 将元素转化为canvas元素
// 通过 放大 提高清晰度
// width为内容宽度
async function toCanvas(element: HTMLElement) {
if (!element) return { width: 0, height: 0 };
// canvas元素
const canvas = await html2canvas(element, {
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true // 允许跨域
});
// 获取canvas转化后的宽高
const { width: canvasWidth, height: canvasHeight } = canvas;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
return { width: canvasWidth, height: canvasHeight, data: canvasData };
}
/**
* 生成pdf(A4多页pdf截断问题, 包括页眉、页脚 和 上下左右留空的护理)
*/
export async function generatePDF({
/** pdf内容的dom元素 */
element,
/** pdf文件名 */
filename
}) {
if (!(element instanceof HTMLElement)) {
return;
}
const pdf = new jsPDF();
// 一页的高度, 转换宽度为一页元素的宽度
const {
width: imageWidth,
height: imageHeight,
data
} = await toCanvas(element);
// 添加图片
function addImage(
_x: number,
_y: number,
pdfInstance: jsPDF,
base_data:
| string
| HTMLImageElement
| HTMLCanvasElement
| Uint8Array
| RGBAData,
_width: number,
_height: number
) {
pdfInstance.addImage(base_data, 'JPEG', _x, _y, _width, _height);
}
addImage(0, 0, pdf, data!, imageWidth, imageHeight);
return pdf.save(filename);
}多页:比例缩放+循环移位
通常,在我们的实践中,会发现2个问题:
- 生成的pdf内容与实际的页面元素比例不一致
- 页面内容超出一页pdf的高度,但是生成的pdf只有一页,没有展示全部的页面信息
这两个问题的解决方案是等比例缩放+循环移位:
- 等比例缩放
通过比例缩放,实现页面内容等比例展示在pdf文档中
令页面元素的宽高为x, y(转化成canvas图片的宽高),pdf文档的宽高为w, h。因为高度可以通过加页延伸,所以可以按照宽度进行缩放,缩放后的图片高度可以通过下列公式计算
y_scaled=(w/x)\*yy\_{scaled} = (w / x) \* yy_scaled=(w/x)\*y
- 循环移位
如果页面的高度超出了pdf文档的高度,即y > h,使用addPage方法添加一页即可。但是在新的一页中,我们的图片内容的高度需要调整。
假设y = 2 * h,这意味我们需要两页才能完整得展示页面内容。在一页pdf中,图片在起始位置插入即可,即
PDF.addImage(pageData, 'JPEG', 0, 0, x, y)// 注意x,y 是缩放后的大小在第二页pdf中,图片的纵向位置需要调整一页pdf的高度,即
PDF.addImage(pageData, 'JPEG', 0, -h, x, y)// 注意x,y 是缩放后的大小通过循环计算剩余高度,然后不停调整纵向位置移动base64的图片位置,可以解决多页的问题。
分页截断的挑战
尽管 JSPDF 和 html2canvas 是功能强大的工具,但是他们也有很多槽点,比如得手动分页,手动处理分页截断的问题。等你实践到这一步,就开始面临分页截断的问题,类似的问题也有网友在Github上提出,但是底下依然没有很好的解决思路。
处理分页截断的原理就是在使用addImage之前,将html进行分页,通过维护一个高度位置数据,来记录每次循环迭代addImage的位置。
从高到低遍历维护一个分页数组pages,该数组记录每一页的起始位置,如:pages[0] 对应 第一页起始位置,pages[1] 对应第二页起始位置
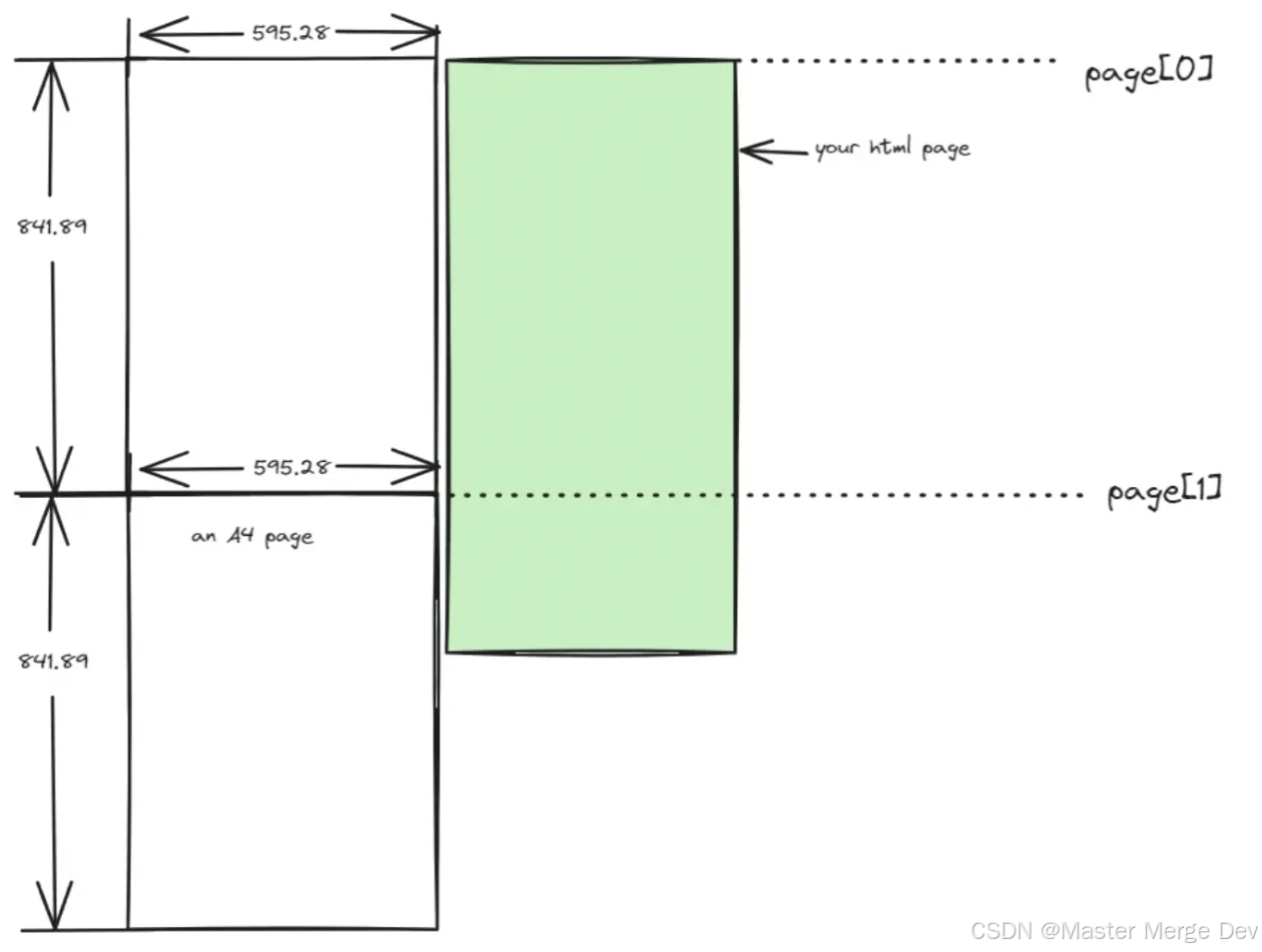
接下来我们重点讨论如何将页面进行切割,然后生成pages这个数组。
假设页面的高度是1500,pdf宽高是[500, 900],如果不用处理分页截断的问题,我们可以想到第一页(0-900)是用来承载页面从高度为0到900的信息;
第二页(900-1800)是用来承载页面从高度900到1500的,所以pages数组为[0, 900]。
如果要处理分页截断呢,这时候就需要计算页面元素的距离pdf文档起始位置的高度h1,以及该元素的内部高度h2,通过这两个高度来判断这个元素要不要放在下一页,防止截断,示意图如下:
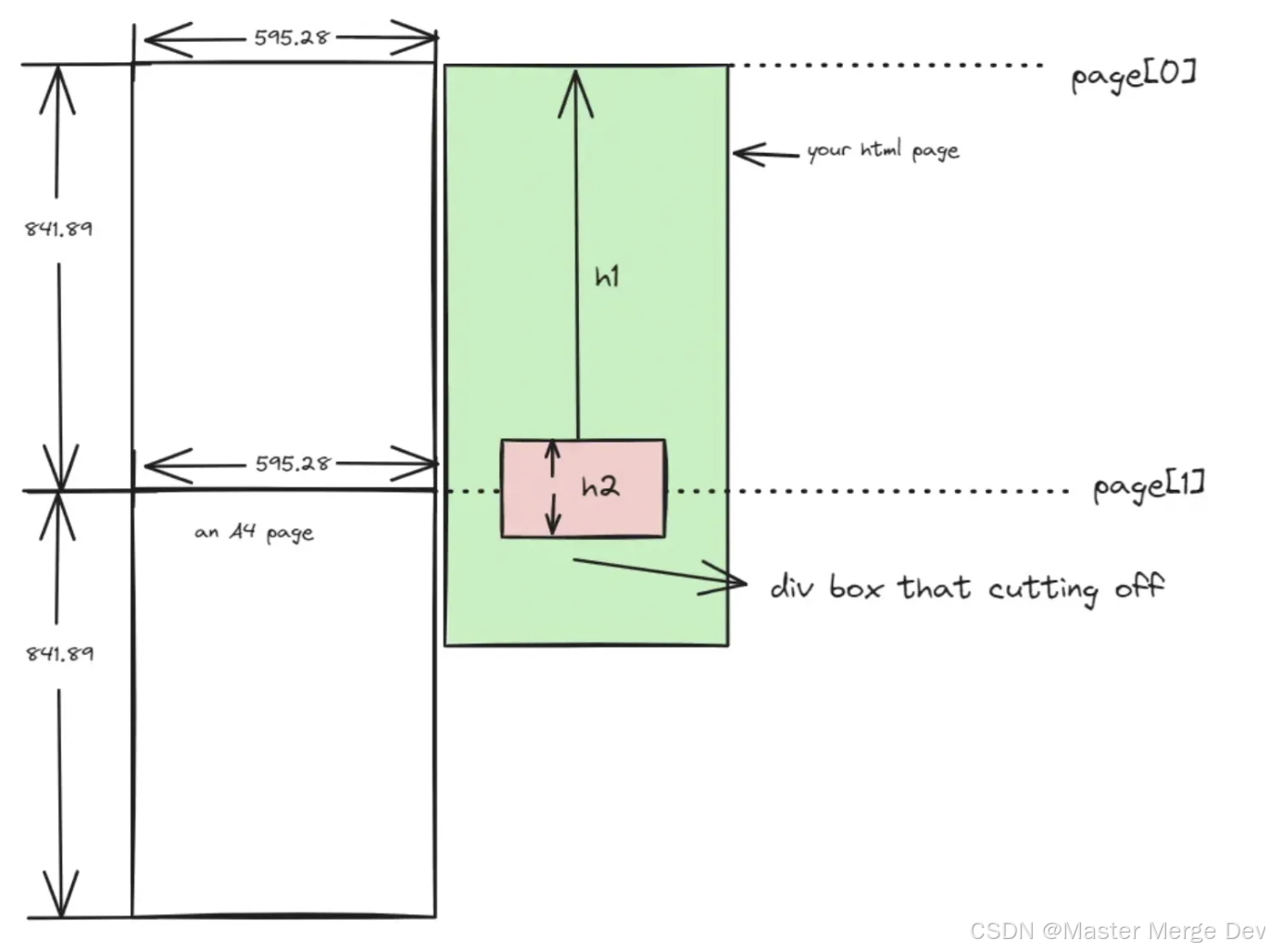
如果h1 + h2 > 页面高度, 这时候说明这个元素不处理的就会被分页截断,所以应该要把这个元素放到第二页去渲染,这就意味着pages记录的数据要变化,示意图如下,可以看到pages[1]我们往上调整了,比第二页pdf的起始位置更高。
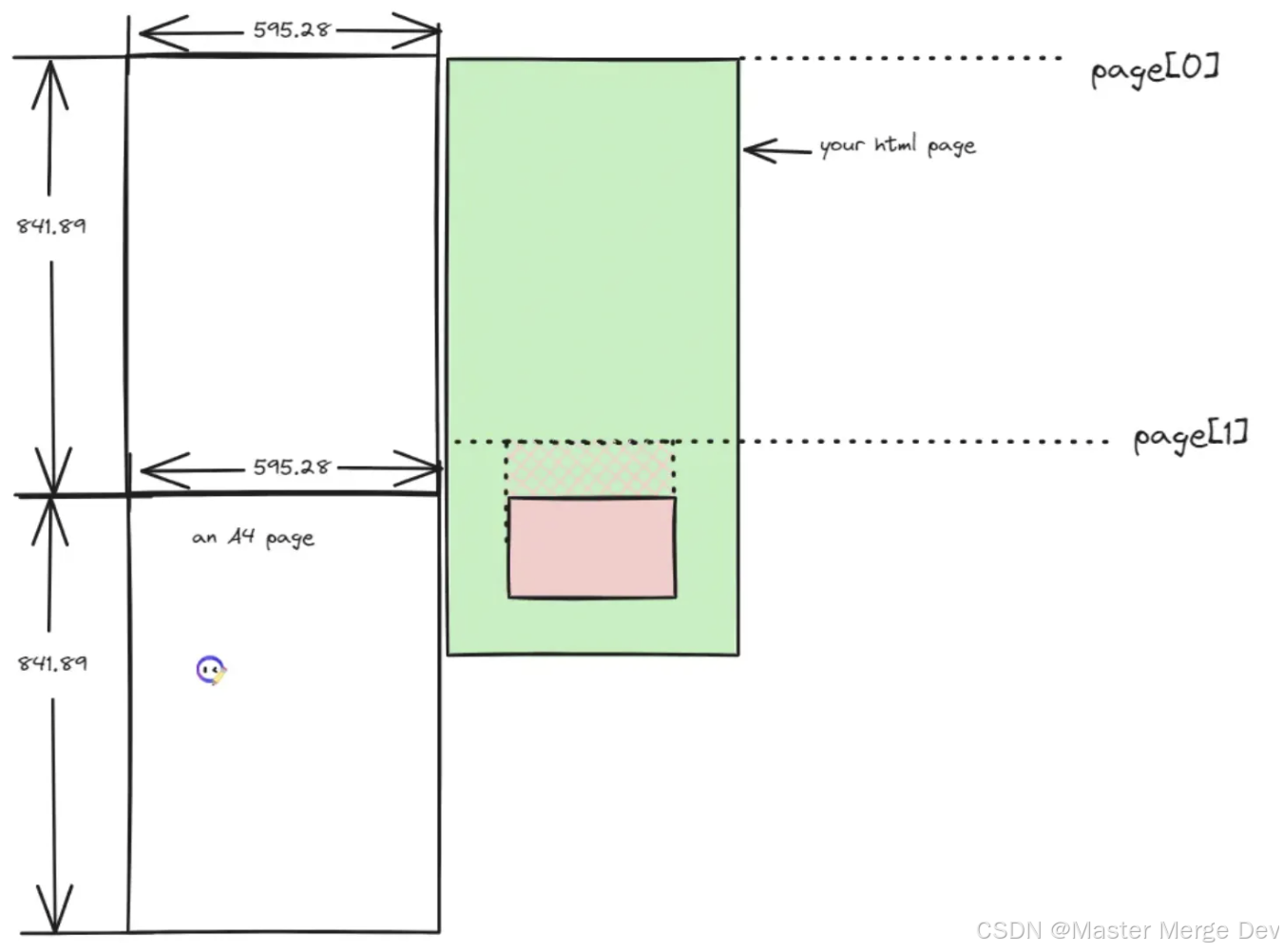
说明渲染第二页pdf的时候,要从h1开始渲染,pages数组为[0, h1],解释为第一页pdf渲染页面高度区域为0-900, 第二页pdf渲染html高度区域为h1-1500。注意到第一页渲染的时候到尾部的时候,**会有部分内容和第二页头部内容重合。**因为h1到900这部分的内容肯定会渲染,这部分内容一直都是页面元素,我们改变pages[1]的值的原因只是创建一个副本,让页面看起来内容没有被截断。
为了解决这个问题(为了美观),我们用填充一块白色区域遮掉它!此处使用jspdf的rect和setFillColor方法,把重合的区域遮白处理。
pdf.setFillColor(255, 255, 255);
pdf.rect(x, y, Math.ceil(_width), Math.ceil(_height), 'F');如何获得h1和h2
上面我们谈到了h1和h2,其中h1是元素盒子的上边距到打印区域的高度(比例缩放后的高度),h2是元素盒子的内部高度。
计算h1: getBoundingClientRect方法
const rect = contentElement.getBoundingClientRect() || {};
const topDistance = rect.top;
return topDistance;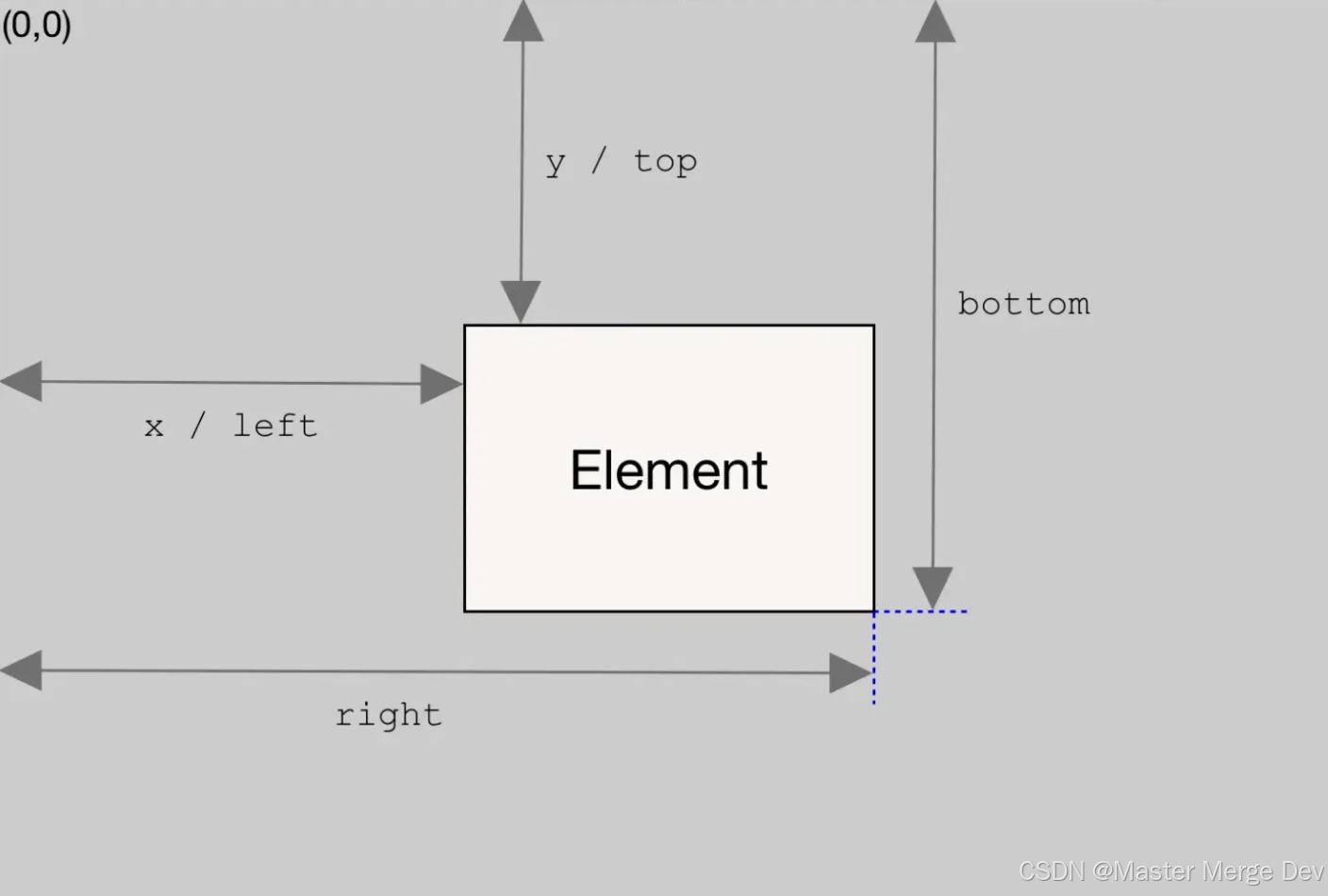
计算h2:
offsetHeight方法
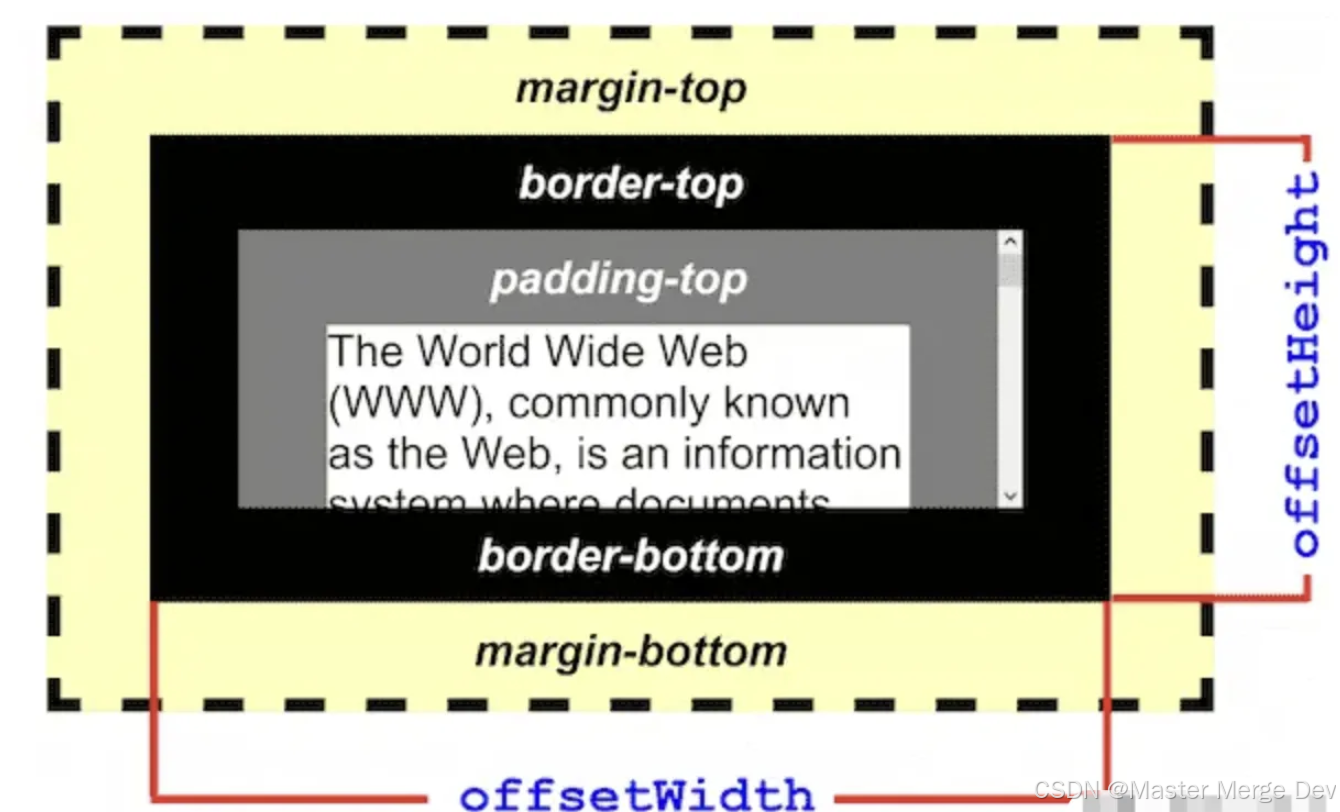
值得注意的是,因为打印区域的html元素不一定是从窗口顶部开始,所以为了计算实际的h1(元素到打印区域的顶部距离),可以采用这样的方法:
●用getBoundingClientRect方法计算元素到窗口顶部的距离
●循环打印之前将pages信息针对第一个元素进行一个高度校准。
/ 对pages进行一个值的修正,因为pages生成是根据根元素来的,根元素并不是我们实际要打印的元素,而是element,
// 所以要把它修正,让其值是以真实的打印元素顶部节点为准
const newPages = pages.map((item) => item - pages[0]);本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
