首页 > 基础资料 博客日记
SpringCloud笔记
2023-07-24 14:02:57基础资料围观603次
2023年最新笔记,全文约 3 万字,蕴含 Spring Cloud 常用组件 Nacos、OpenFeign、Seata、Sentinel 等
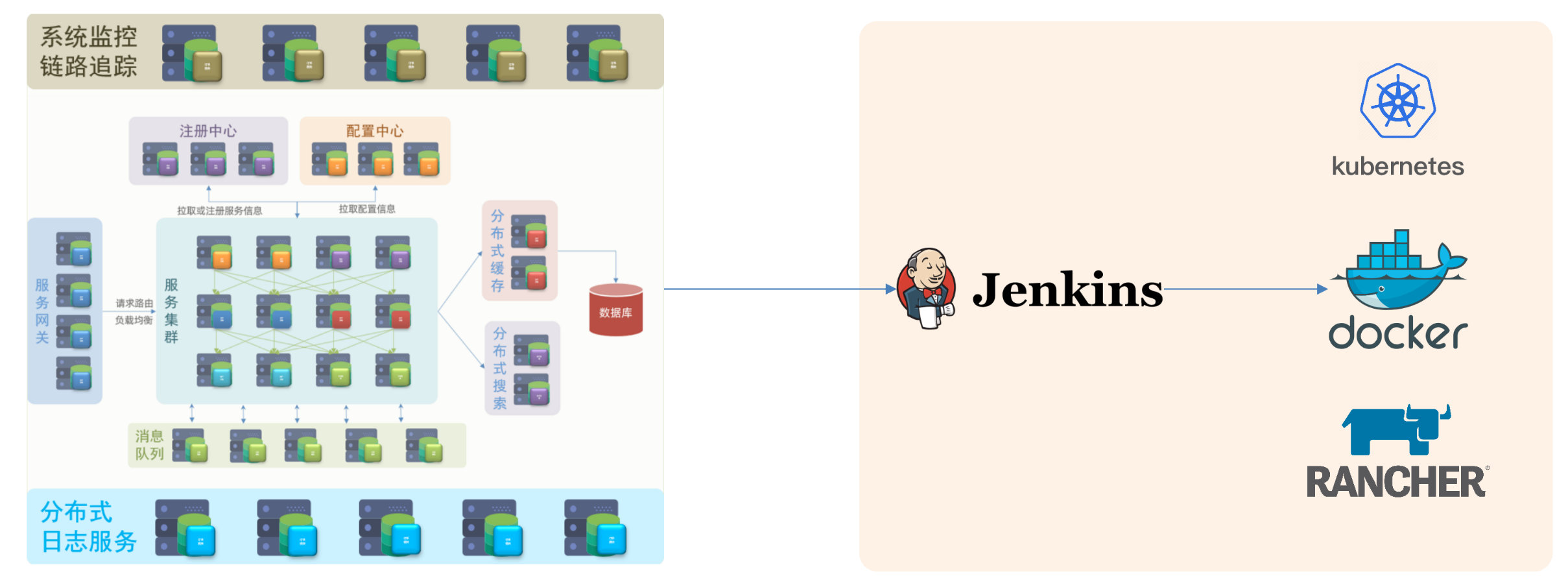
〇、简介
-
什么是Spring Cloud?
Spring Cloud是一系列框架的有序集合,是一种基于微服务的分布式架构技术。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署,从而提供了良好的开箱即用体验。
-
主流的架构方式:
- 单体架构:架构简单、部署成本低,耦合度高。
- 分布式架构:架构复杂、部署成本高,耦合度低。
-
微服务架构特征:
总体方向:高内聚、低耦合
- 单一职责:微服务拆分粒度小,每个服务对应单一业务功能。
- 面向服务:对外暴露业务接口。
- 自治:团队独立、技术独立、数据独立、部署独立。
- 隔离性强:提升容错性、避免出现级联故障。
-
常见微服务技术对比:
- 阿里 Dubbo
- Spring Cloud(第一代)
- Spring Cloud Alibaba(第二代)


-
Spring Cloud 版本说明
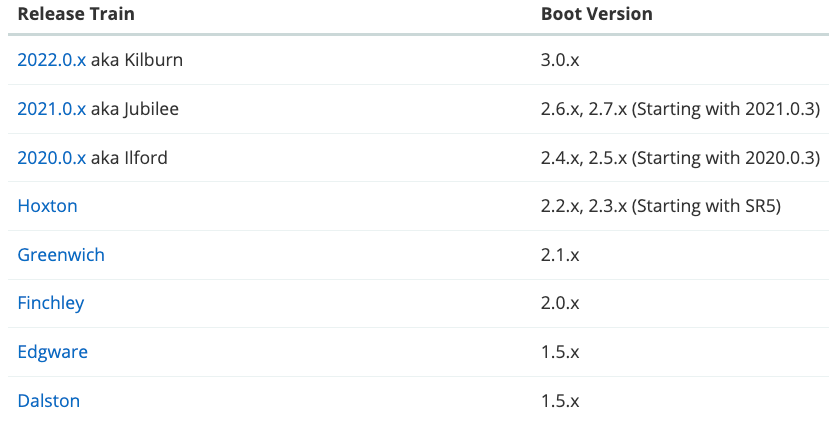
大版本说明:
- 2020 年之前:按照“伦敦地铁”命名,从 A 到 H。
- 2020 年之后:按年份命名。
小版本说明:

其余版本信息说明
- snapshot: 快照
- pre:预览版本
- alpha : 内测
- beta : 公测
- release : 稳定版本
- GA: General Availability,发行版,即最稳定的版本
- Final : 正式版
- Pro(professional) : 专业版
- Plus: 加强版
- Retail : 零售版
- DEMO : 演示版
- Build : 内部标号
- Corporation或Enterpraise 企业版
- M1 M2 M3 : M是milestone的简写 里程碑的意思
- RC 版本RC:(Release Candidate),几乎就不会加入新的功能了,而主要着重于除错
- SR : 修正版
- Trial : 试用版
- Shareware : 共享版
- Full : 完全版
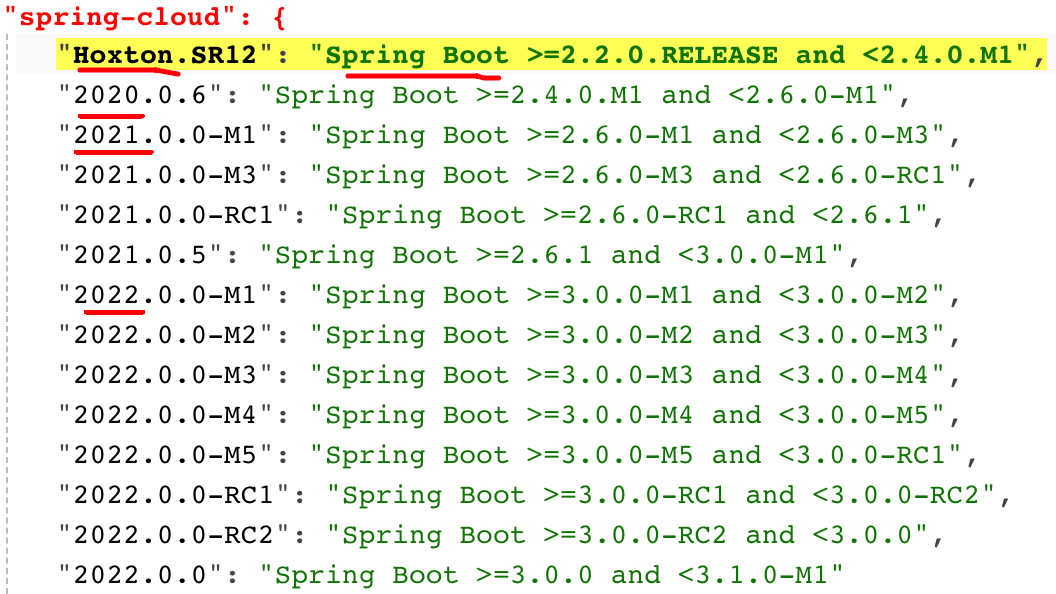
- Spring Cloud 与 Spring Boot 的选型必须严格按照官方给出的建议去对应,我们可以通过官网或者详情链接https://start.spring.io/actuator/info查看最新推荐的版本对应关系:
-
【其他注意点】:
- 微服务之间的联系通过暴露接口实现,比如HTTP协议或者Dubbo协议。
- 每个微服务都应该有专属的独立数据库,并且每个微服务只能访问自己的数据库,严禁访问别人的微服务数据库(避免重复开发原则)。
-
构建 Spring Cloud 父工程
创建 Maven 项目,选择一个较为简单的架构模式(方便后面删除)
将父工程中除了.pom文件的其余文件全部删除
在父工程的pom 文件中修改或新增<packaging>pom</packaging>,代表这是父工程,其他工程项目可继承于它。
<packaging>pom</packaging>
粘贴下列pom配置:
<dependencyManagement>:只声明依赖,不实现引入,子项目需要显示声明使用的依赖- 作用:子项目在声明时可以不用带上版本号,如果子版本中也配置了版本号,则以子版本标明的为主。
- 注意 Spring Boot 与 Spring Cloud 之间的版本对应关系
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/>
</parent>
<!-- 广泛使用的 lombok -->
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<!-- 定义版本号 -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR8</spring-cloud.version>
<mysql.version>5.1.47</mysql.version>
<mybatis.version>2.1.1</mybatis.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- springCloud -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--nacos的管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
-
构建 Spring Cloud 子工程
- 方式一:构建初始 Maven 项目(module),后面内容缓慢补充(改 pom、写 yml、编写主启动类、编写业务类)
- 方式二:构建 Spring Initializr 项目(module),后面改写 pom 文件使形成 Maven 继承关系即可。个人偏向于这种方式。
-
父类显式声明子类,子类标明继承自父类
<modules>
<module>子类1</module>
<module>子类2</module>
</modules>
<!--标明继承自父类-->
<parent>
<artifactId>springcloud_test</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
-
【强制性】凡是微服务,一般都需要有端口号与名称(程序名称将作为
服务Id,用于与其他服务分辨)server: port: 8001 spring: application: name: payment8001 -
返回结果定义(通常结构)
- 数值类型code码,表示状态
- 消息类型message:例如 success,error 等
- 消息实体 data,即数据
@Data @AllArgsConstructor @NoArgsConstructor public class CommonResult<T> { private Integer code; private String message; private T data; } -
RestTemplate类简介:RestTemplate 是 Spring 提供的用于访问 Restful 风格服务的客户端模版工具集,其提供了多种便捷访问远程 Http 服务的方法,作用类似 Java 原生的
HttpClient。 -
Spring Cloud 初体验:
服务之间通过暴露接口、HTTP 请求实现沟通。
自行配置Spring对象
RestTemplate并注入,发送 GET 与 POST 请求使用.getForObject()、.postForObject()@Configuration public class CommonConfig { @Bean RestTemplate getRsetTemplate(){ return new RestTemplate(); } }
一、Eureka
NetFlix Eureka,注册中心
-
简介:
- Spring Cloud 使用 Eureka 来充当第一代注册中心,其类似于【发布者】-【订阅者】模型。
-
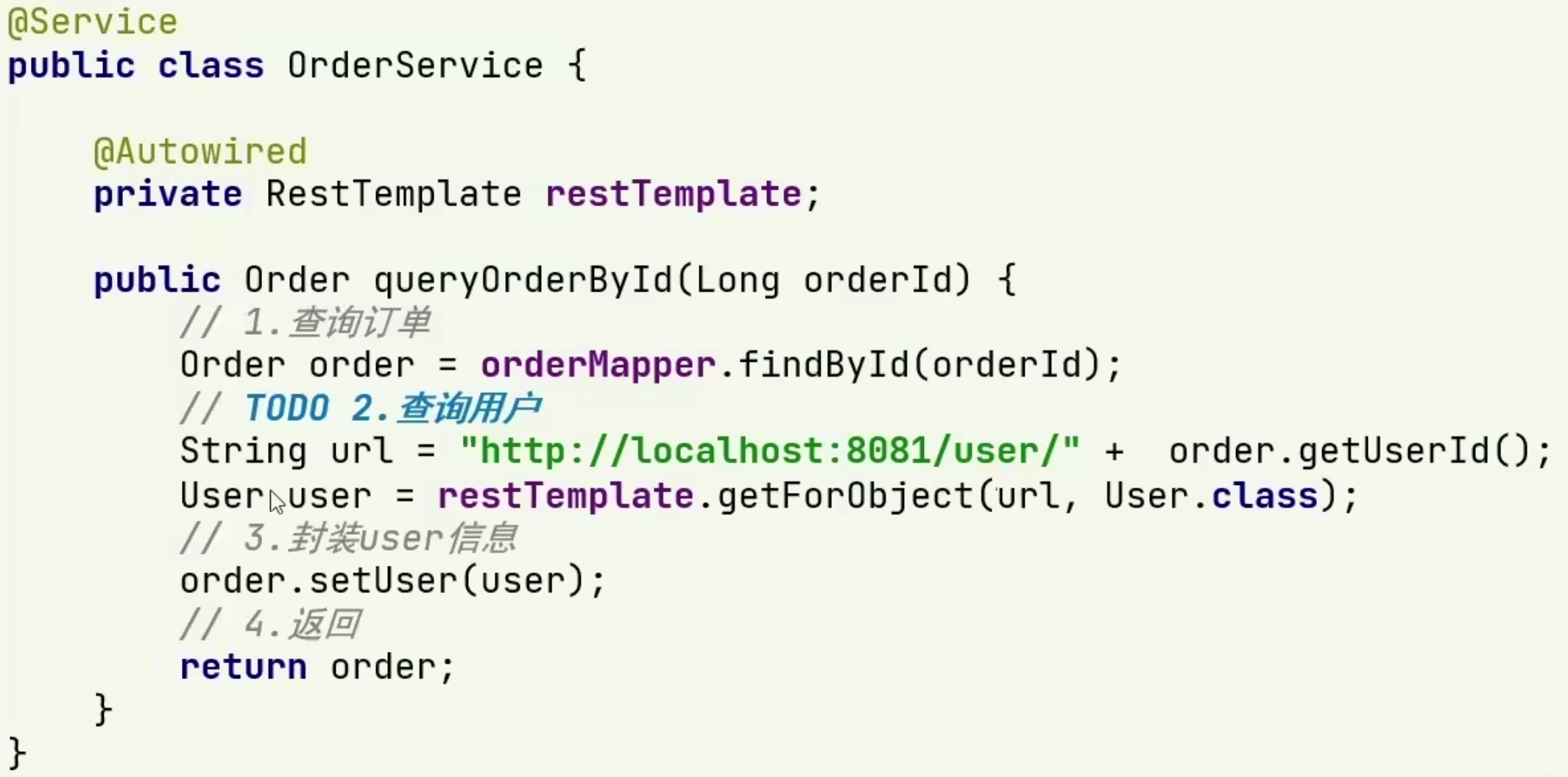
Eureka 拥有 3 个角色
- Eureka Server:服务端。注册中心,提供记录服务信息(业务功能、健康状况等)、心跳监控等。
- Eureka Client:客户端。用于简化与 Eureka Server 的交互
- Provider:服务提供者,会将自己的信息注册到 Eureka Server 并每隔 30s 发送一次心跳包。
- consumer:服务消费者,根据所需从 Eureka Server 中拉取服务列表,并根据负载均衡策略对其中一个微服务发起远程调用。
-
Eureka 实现原理
- 微服务启动时,会通过 Eureka Client 向 Eureka Server 进行注册自己的信息,而 Eureka Server 会存储该服务的信息。
- 微服务启动后,会周期性地向 Eureka Server 发送心跳(即自身信息,默认周期为30秒),如果Eureka Server在一定时间内没有接收到某个微服务节点的心跳,则会注销该微服务节点(默认90秒)。
- 每个 Eureka Server 同时也是 Eureka Client ,多个Eureka Server之间通过复制的方式完成服务注册表的同步。
- Eureka Client 会缓存 Eureka Server 中的信息。即使所有的 Eureka Server 节点宕机,服务消费者依然可以使用缓存中的信息找到服务提供者。

-
简单实现(单机版)
- pom 导包(分为 server 与 client 包,部分Spring版本 parent 中无 Eureka 信息,需手动指定版本)
- 服务端主配置上开启
@EnableEurekaServer。 - yaml 配置 Eureka 信息(注意也要配置 Spring 程序名称)
【服务端】:服务端一般不需要将自己注册成微服务
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency>@EnableEurekaServerserver: port: 10086 spring: application: name: MyServer eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka # 不向 eureka server 注册自己与获取服务列表 register-with-eureka: false fetch-registry: false【客户端】
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>spring: application: name: user_service eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka 利用
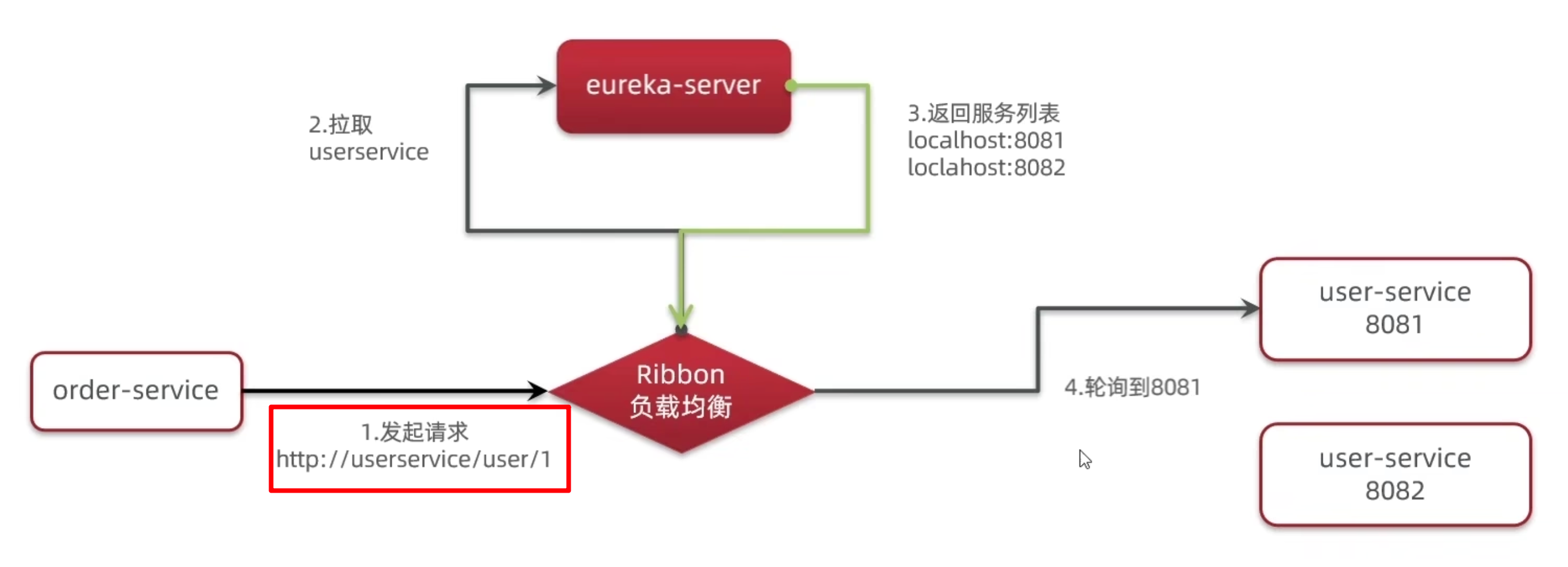
RestTemplate向其他微服务发送请求。在编写 URL 路径时,通过指定其他微服务的应用名即spring.application.name来调用其服务(如http://userservice/),注册中心将充当 DNS 为各微服务提供解析服务,从而使我们不用像之前一样编写 IP 或域名硬编码的形式(如http://127.0.0.1:8080/)。// 子微服务使用其他微服务,并实现负载均衡 @Bean @LoadBalanced public RestTemplate rest() { return new RestTemplate(); }String url="http://userservice/user/"+order.getUserId();
二、Ribbon
NetFlix Ribbon,负载均衡
-
简介:
- Ribbon 实现了客户端负载均衡,主要结合 Eureka 用于服务注册及发现。
- 传统的服务端负载均衡诸如 Nginx 需要单独部署额外的服务(成本增加),而 Ribbon 结合 Eureka 可以直接在客户端实现负载均衡。
- Ribbon拥有多种负载均衡模式,与 nginx 类似。
-
Ribbon 默认使用【轮询算法】
下面是 Ribbon 中实现的各种算法简介,
IRule是顶层接口,下面是具体的实现类。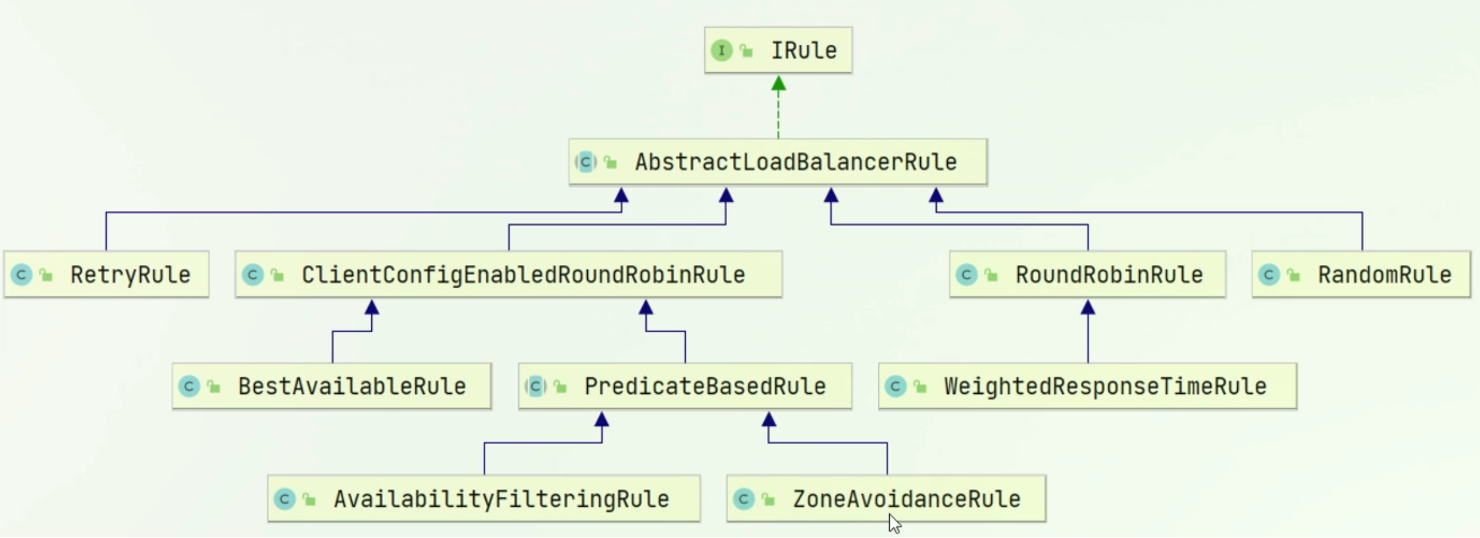

-
简单实现:
由于 Ribbon 与 Eureka 都是由 NetFlix 公司开发,且 Ribbon 常用于与 Eureka 组合实现负载均衡,所以当我们引入
spring-cloud-starter-eureka依赖时也会默认引入 Ribbon 依赖,无需重复引入。<!-- 下面是 spring-cloud-starter-eureka 的依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency>
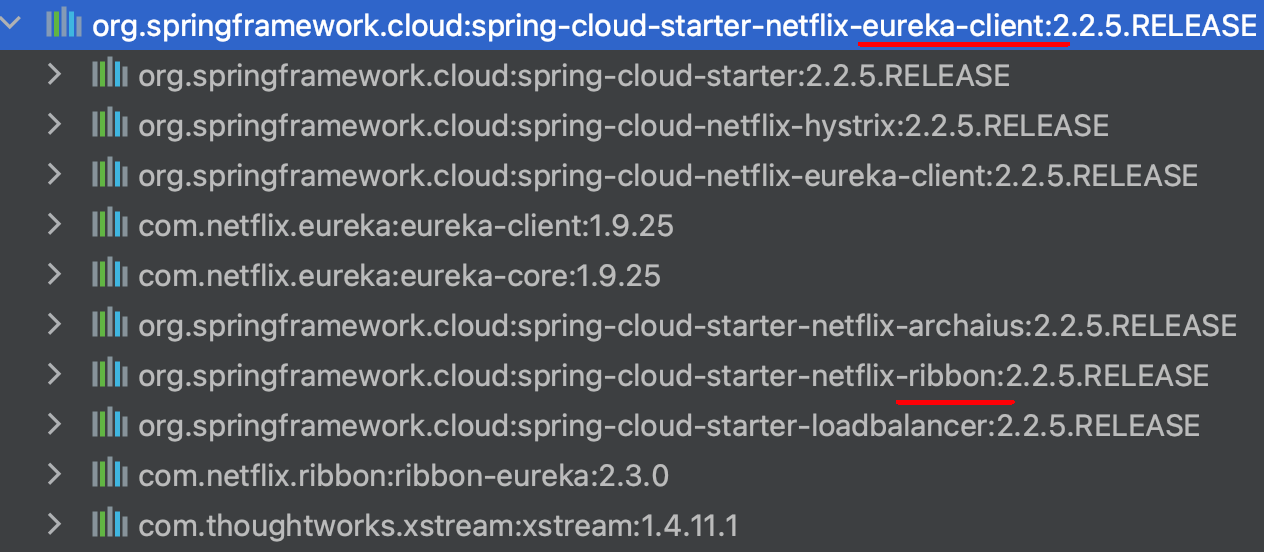
我们要做的只是通过简单配置更改 Ribbon 的【负载均衡】模式,有 2 种办法:
-
全局生效:因为 Ribbon 的所有模式都基于
IRule接口,所以可以通过改变其注入的 Bean 实现。@Bean public IRule randomRule(){ // 随机模式 return new RandomRule(); } -
局部生效:仅对所调用的某微服务生效
某微服务名称: ribbon: NFLoadBalancerRuLeClassName: com.netfLix.Loadbalancer.RandomRule微服务名称即:所要调用的微服务名称

另外,由于 Ribbon 默认采用**【懒汉模式】,即第一次请求链接时才会获取“可用的微服务列表”,这将造成一定的体验损耗,我们可以将其更改成【饿汉模式】**。
ribbon:
eager-load:
enable: true
# 客户端在启动时,就会去请求这些名称的“微服务表”
clients:
- userservice
- vipservice
三、Nacos
阿里 Nacos,Eureka的替代品
注册中心(服务发现中心)、配置管理。
0、简介
-
Nacos /nɑ:kəʊs/ ,
Dynamic Naming and Configuration Service(动态域名命名和配置服务)首字母简称,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台,Nacos 致力于发现、配置和管理微服务。 -
Nacos 使用 Java 编写,如果本地 JDK 环境配置不对,会出现一系列不明所以的报错。
-
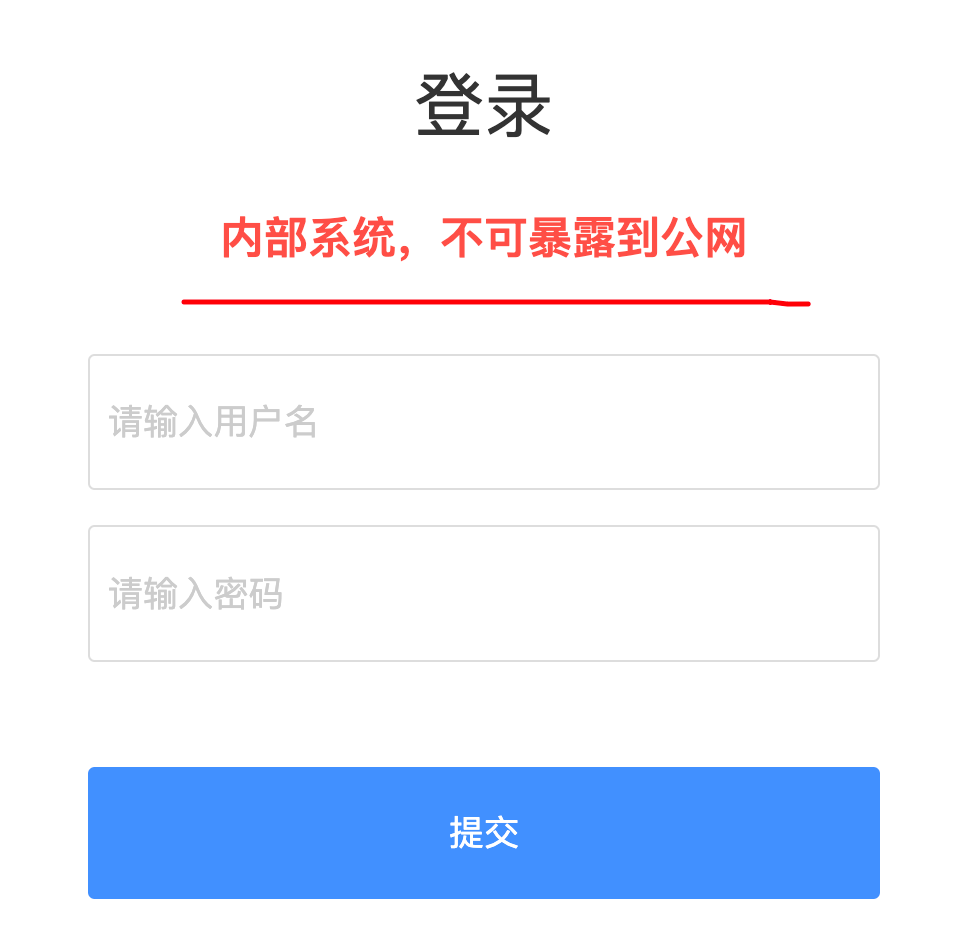
Nacos是一个内部微服务组件,需要在可信的内部网络中运行,并非面向公网环境的产品,不可暴露在公网环境,强烈不建议部署在公共网络环境。Nacos提供了简单的鉴权实现,是为防止业务错用的弱鉴权体系,而不是防止恶意攻击的强鉴权体系。
-
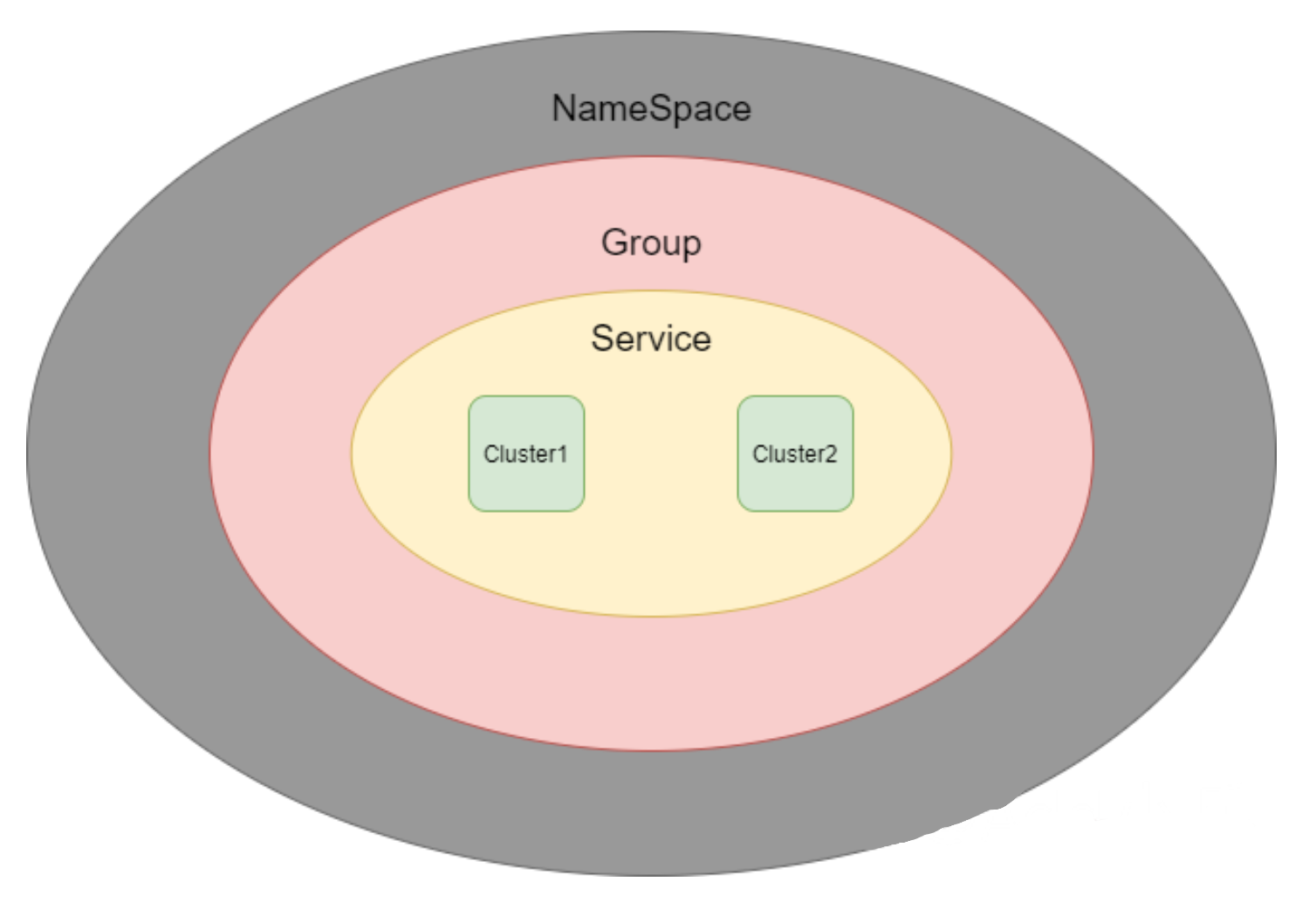
Nacos 架构
- Namespace:命名空间,默认
空串代表公共命名空间public。 - Group:分组,默认为
DEFAULT_GROUP,作项目区分,用来区分相同开发环境下的不同项目(如测试环境下的电商项目、测试环境下的培训机构项目) - Service:服务,提供具体服务(如登录服务、验证码服务等)。
- Cluster:集群,如上海集群,杭州集群。
例如在某命名空间下(如测试环境的命名空间),有众多分组(项目),每个项目又有一些服务(服务可以说是最小可用单位),服务又会归属于不同集群(提升可用性与性能)。
- Namespace:命名空间,默认
-
整合 Spring Cloud 配置说明:
discovery:服务发现中心config:配置中心
-
当 Nacos 没有整合 OpenFeign 时,默认使用的是 RestTemplate ,此时如果需要实现“负载均衡”策略,则:
@LoadBalanced @Bean public RestTemplate restTemplate() { return new RestTemplate(); }负载均衡方式默认为轮询
1、安装
-
简介:
- Nacos 已经被封装成 jar 包,我们配置好基本要求,直接运行 jar 包即可。
- 在程序运行之后,其余配置只能在网页端的控制面板修改,不能在代码中修改。
-
手动模式:
-
解压并启动(此处为单机模式)
-
单机模式
-
集群模式
-
# 单击模式启动 ./startup.sh -m standalone # 关闭 ./shutdown.sh -
Docker模式
未挂载配置目录与日志目录
docker run \ --name myNacos \ -e MODE=standalone \ --env NACOS_AUTH_ENABLE=true \ -p 8848:8848 \ -d \ nacos/nacos-server挂载已有的配置目录与日志目录:提前将 Nacos
/conf/目录文件拷贝至/tmp/nacos/conf/docker run \ --name myNacos \ -e MODE=standalone \ --env NACOS_AUTH_ENABLE=true \ -v /tmp/nacos/conf/:/home/nacos/conf/ \ -v /tmp/nacos/logs/:/home/nacos/logs/ \ -p 8848:8848 \ -d \ nacos/nacos-server挂载新的的配置目录与日志目录:
docker run \ --name myNacos \ -e MODE=standalone \ --env NACOS_AUTH_ENABLE=true \ -v nacosConf:/home/nacos/conf/ \ -v nacosLogs:/home/nacos/logs/ \ -p 8848:8848 \ -d \ nacos/nacos-serverdocker inspect mq | grep volume -
开启服务器鉴权
按照官方文档配置启动,默认是不需要登录的,这样会导致配置中心对外直接暴露。而启用鉴权之后,需要在使用用户名和密码登录之后,才能正常使用nacos。(所以 Nacos 才推荐不要把自身放在“外网”中)
配置
/conf/application.properties文件nacos.core.auth.enabled=true如此一来,Client 端便需要配置 nacos 的账号密码才能登录。
**注意:**鉴权开关是修改之后立马生效的,不需要重启服务端。
-
安装之后
- 可以通过查看
/logs/start.out日志来查看启动详情。 - 访问
http://127.0.0.1:8848/nacos登录 Nacos,默认账号密码均为 nacos。
- 可以通过查看
-
Spring项目引入 Nacos 依赖
父工程(这是必备的)
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.5.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency>子工程
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> -
配置 Nacos 地址
在未开启“鉴权模式”时,可以不配置
username与passwordspring: cloud: nacos: server-addr: localhost:8848 username: nacos password: nacos -
**注意:**Nacos 包不可与 Eureka 包同时导入同一工程,否则产生冲突
Bean multiple。
2、命名空间
命名空间使实例之间【相互隔离】,看不到彼此,这可以用作正式环境与测试环境的区分。当 Nacos 启动时会默认使用全局唯一命名空间public。
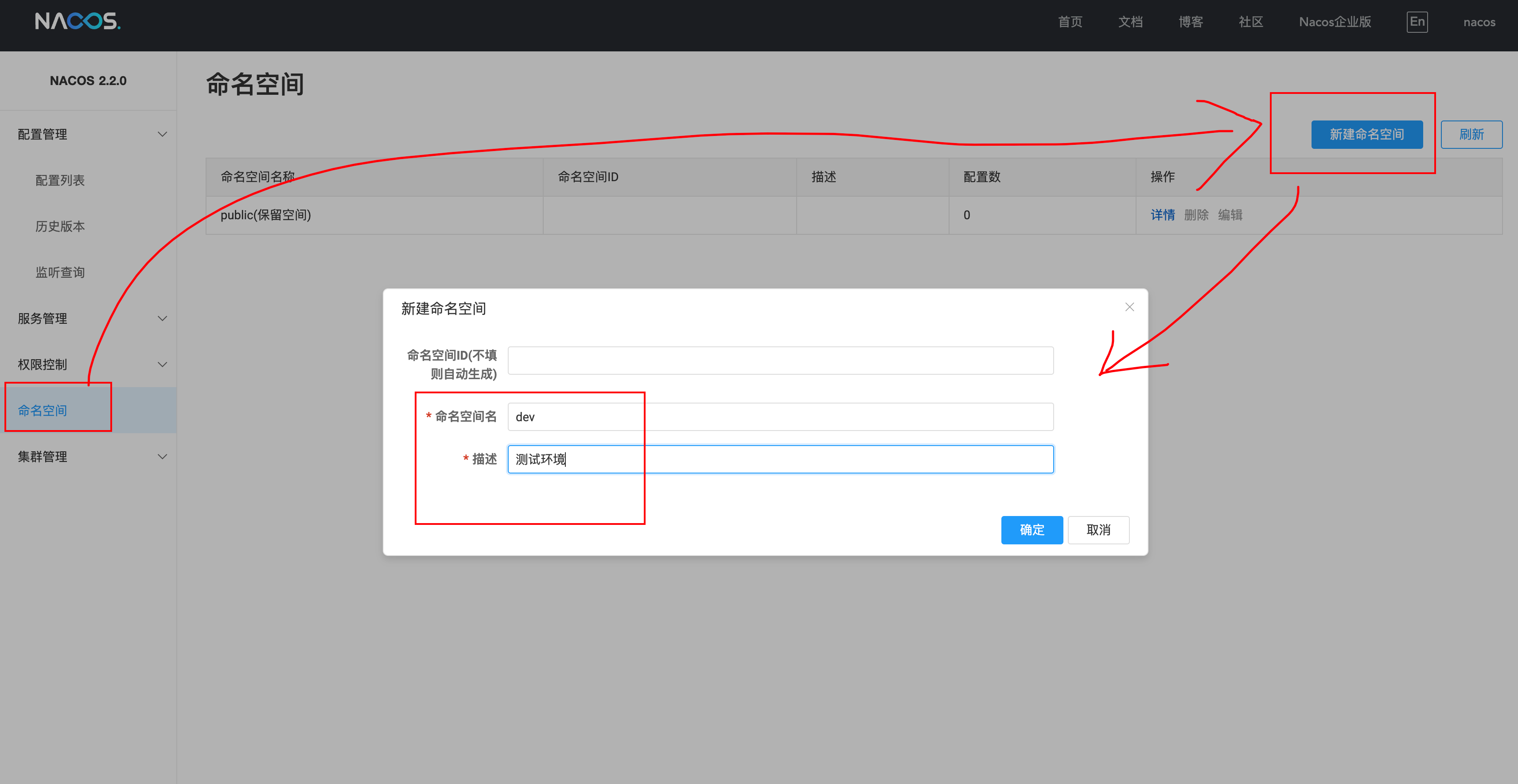
步骤:
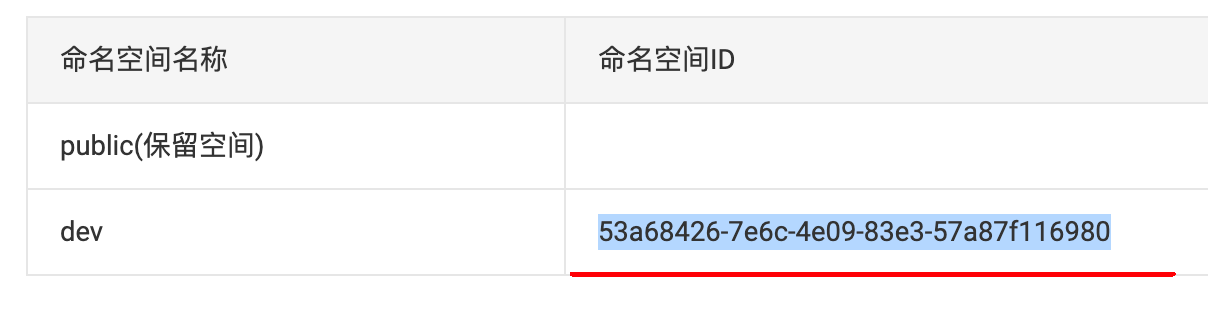
- 新建命名空间(此处自动使用 UUID 当作“主键id”)
- 实例 yml 文件配置命名空间(使用生成的主键 id )
spring:
cloud:
nacos:
server-addr: http://localhost:8848
discovery:
cluster-name: HZ
namespace: 53a68426-7e6c-4e09-83e3-57a87f116980 # 声明命名空间
3、服务分级模型
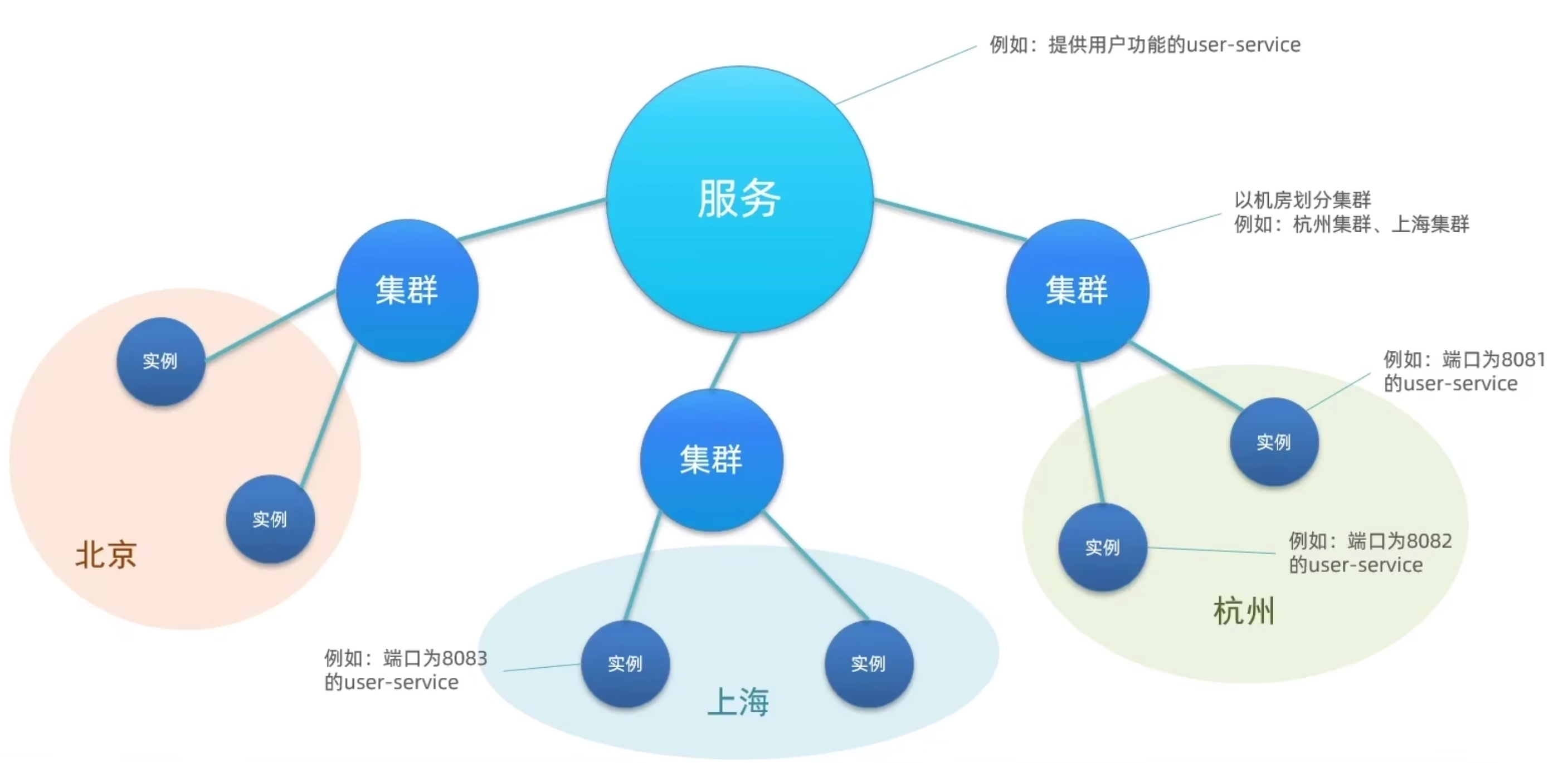
服务分级模型在相同“命名空间”的前提下,Nacos 利用服务分级存储模型来提高【容灾率】,例如:
- 总体服务
- 集群(如上海、杭州)
- 实例
- 集群(如上海、杭州)
集群默认为DEFAULT_GROUP,更改如下:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 例如:HZ代表杭州、SH表示上海
- 一个集群就相当于一个小型完善的“生态系统”。
- 在开启集群设置后,我们应该将**【负载均衡策略】修改为【优先使用本地集群】(如果本地集群全部失效,程序会自动转向其他集群发起请求),随后 Nacos 就会再在本地集群选择【随机选取】**的方式进行实例的选择(注意这里不是轮询)。
某微服务名称:
ribbon:
NFLoadBalancerRuLeClassName: com.alibaba.cloud.ribbon.NacosRule
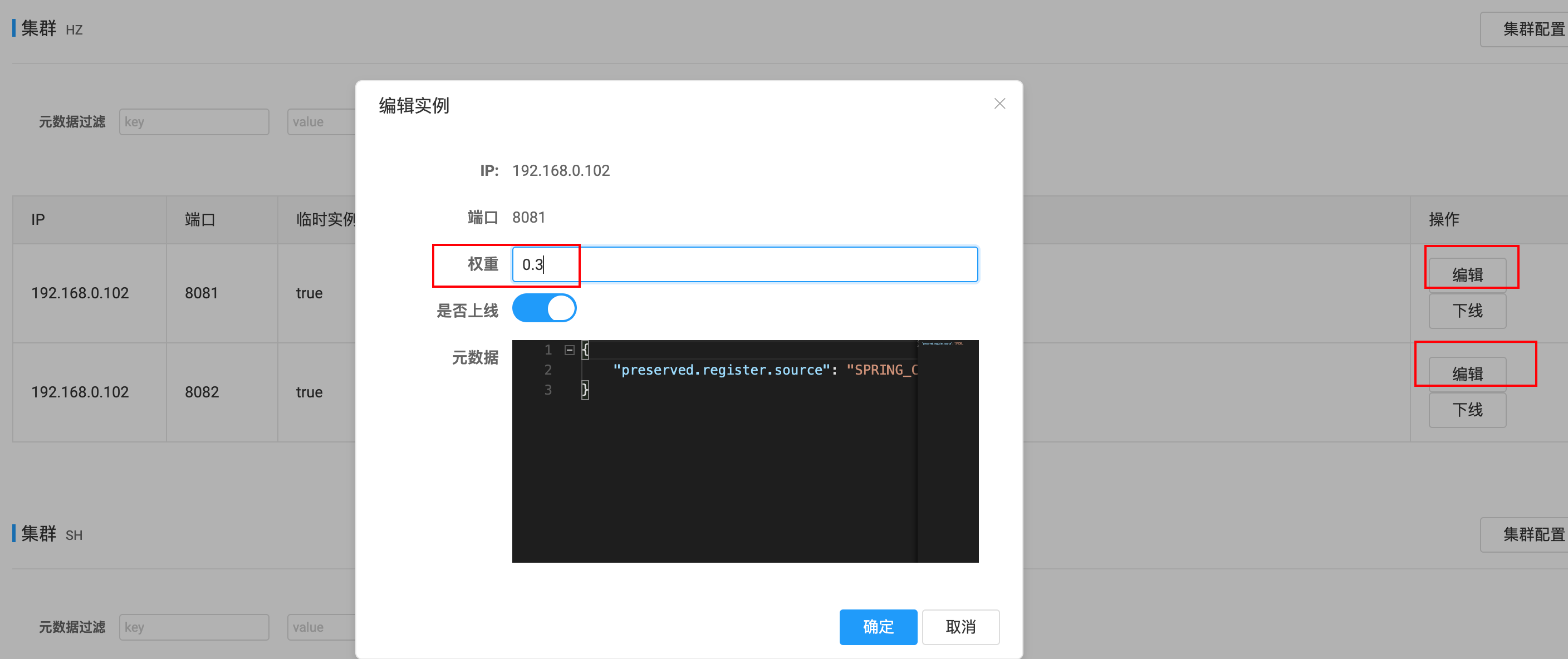
4、服务权重
Nacos可以通过【网页控制台】为实例设置权重,范围从0~1,值越大越容易被访问,设置为0则完全不会被访问,这可以用作“灰度升级”。
注意:必须是相同集群下拥有多个相同实例时,才可配置权重。
5、服务监测
监测实例的健康状态
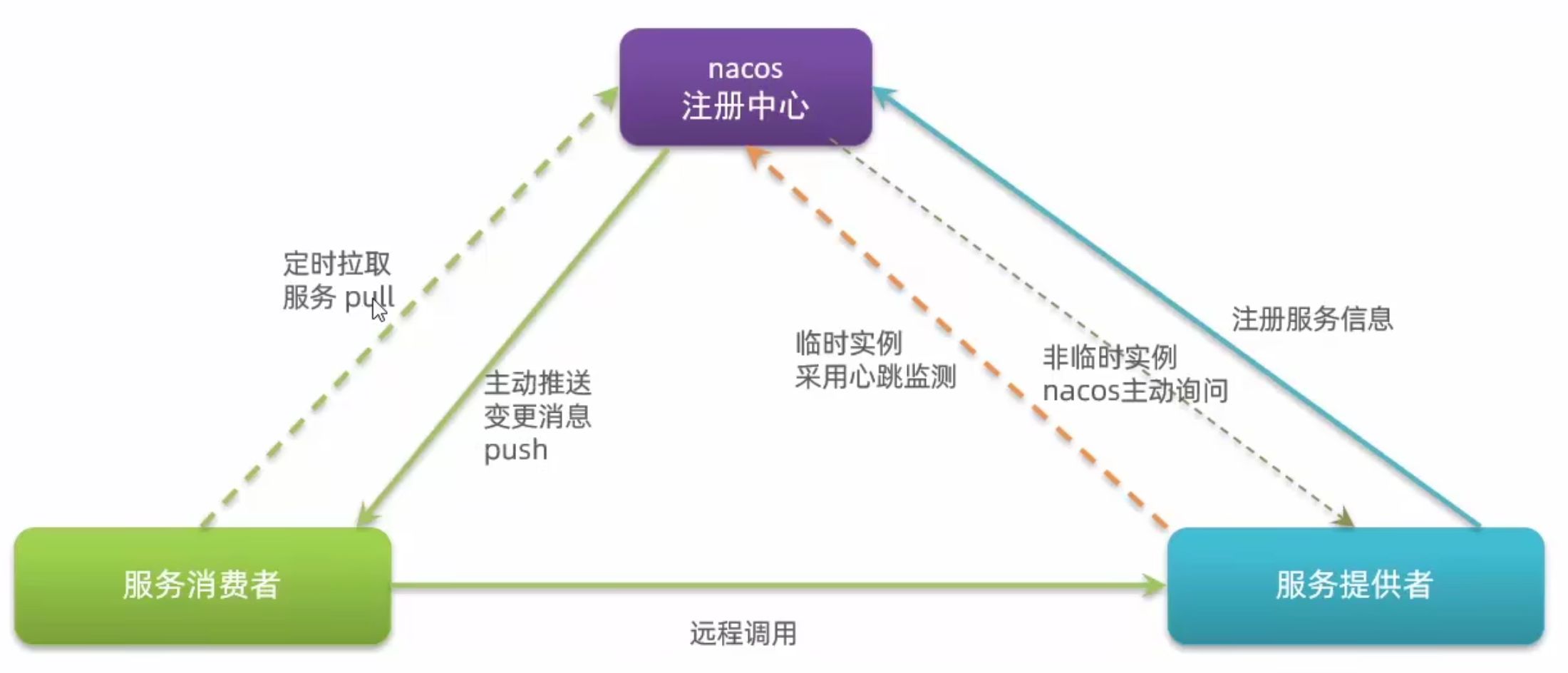
Nacos拥有临时监测(被动)、非临时监测(主动)
Eureka只有临时监测
-
临时监测(默认、被动检测):
- 发送心跳包。
- 客户端心跳上报Nacos实例健康状态,默认间隔5秒,Nacos在15秒内未收到该实例的心跳,则会设置为不健康状态,超过30秒则将实例移除。在被移除后如果又开始上报心跳,则会重新注册实例。
- 运维只能通过检查实例数量来监测实例状态,但临时实例的设置本就是应对“流量突增”情况的。
-
非临时监测(主动检测)
- Nacos会定期 主动 发起请求询问实例的健康状态(不发送心跳包)
- 在实例失效时也会主动 push 推送信息给服务消费者,及时更新数据。此时实例并不会被移除,依旧保留在服务列表,只是状态为
false。 - 主动询问的方式对服务器压力较大,它的好处是运维可以实时看到实例的健康状态,便于后续的警告、扩容等一些列措施。
-
配置非临时检测:
spriing: cloud: nacos: server-addr: http://localhost:8848 discovery: cluster-name: HZ namespace: 53a68426-7e6c-4e09-83e3-57a87f116980 # ephemeral,短暂的 ephemeral: fasle -
【非临时监测】的另外一个作用:设置保护阈值,防止产生服务雪崩效应
Nacos中可以针对具体的实例设置一个保护阈值,值为0-1之间的浮点类型。本质上,保护阈值是⼀个⽐例值(当前服务健康实例数/当前服务总实例数)。
⼀般情况下(临时监测),服务消费者要从Nacos获取可用实例有健康/不健康状态之分。Nacos在返回实例时,只会返回健康实例。
但在高并发、大流量场景会存在⼀定的问题。比如,服务A有100个实例,98个实例都处于不健康状态,如果Nacos只返回这两个健康实例的话,流量洪峰的到来可能会直接打垮这两个服务,进一步产生雪崩效应。保护阈值存在的意义在于当服务A健康实例数/总实例数 < 保护阈值时,说明健康的实例不多了,保护阈值会被触发(状态true)。
Nacos会把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费者可能访问到不健康的实例,请求失败,但这样也⽐造成雪崩要好。牺牲了⼀些请求(将请求分流到不健康的实例),保证了整个系统的可⽤。
6、配置管理
实现“统一配置”与“热更新”
-
简介:
使用 Nacos 可以实现实例的统一配置与配置热更新(即当配置被修改时,主动推送并实现热更新、不重启)
应该将固定不变配置写入服务本身的
application.yml,易于变化的配置则写入 Nacos 配置文件。 -
应用 Nacos 统一配置流程图
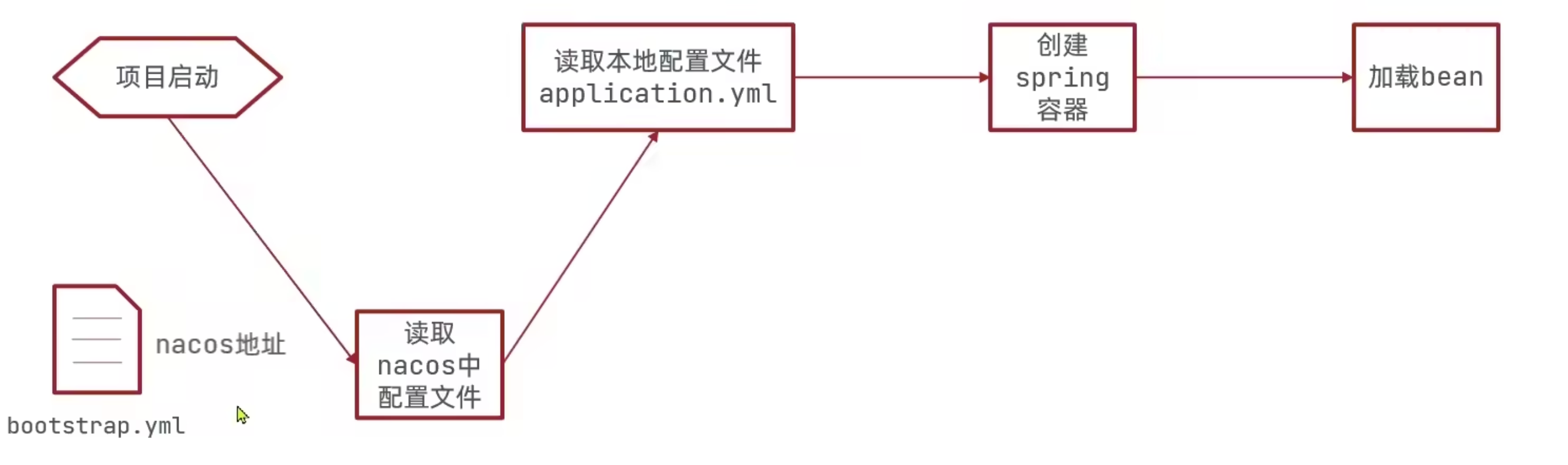
声明:一个服务如果以 nacos 作为配置中心,应该先拉取 nacos 中管理的配置,然后与本地的配置文件比如 application.yml 中的配置合并,最后作为项目的完整配置,启动项目。
实现原理:Spring 中
bootstrap.yml文件的启动优先级高于application.yml,我们可以将 Nacos 配置写入其中(注意单词有两个t)。 -
【共同配置】
在Nacos情境下,微服务在启动时会从 Nacos 读取2个配置文件,按优先级为:
配置名称-环境.yaml:userservice-dev.yaml配置环境.yaml:userservice.yaml
而且无论如何都会读取到第二个配置环境,所以我们可以将微服务相同的配置再放入第二种配置环境中。
-
【统一配置】:
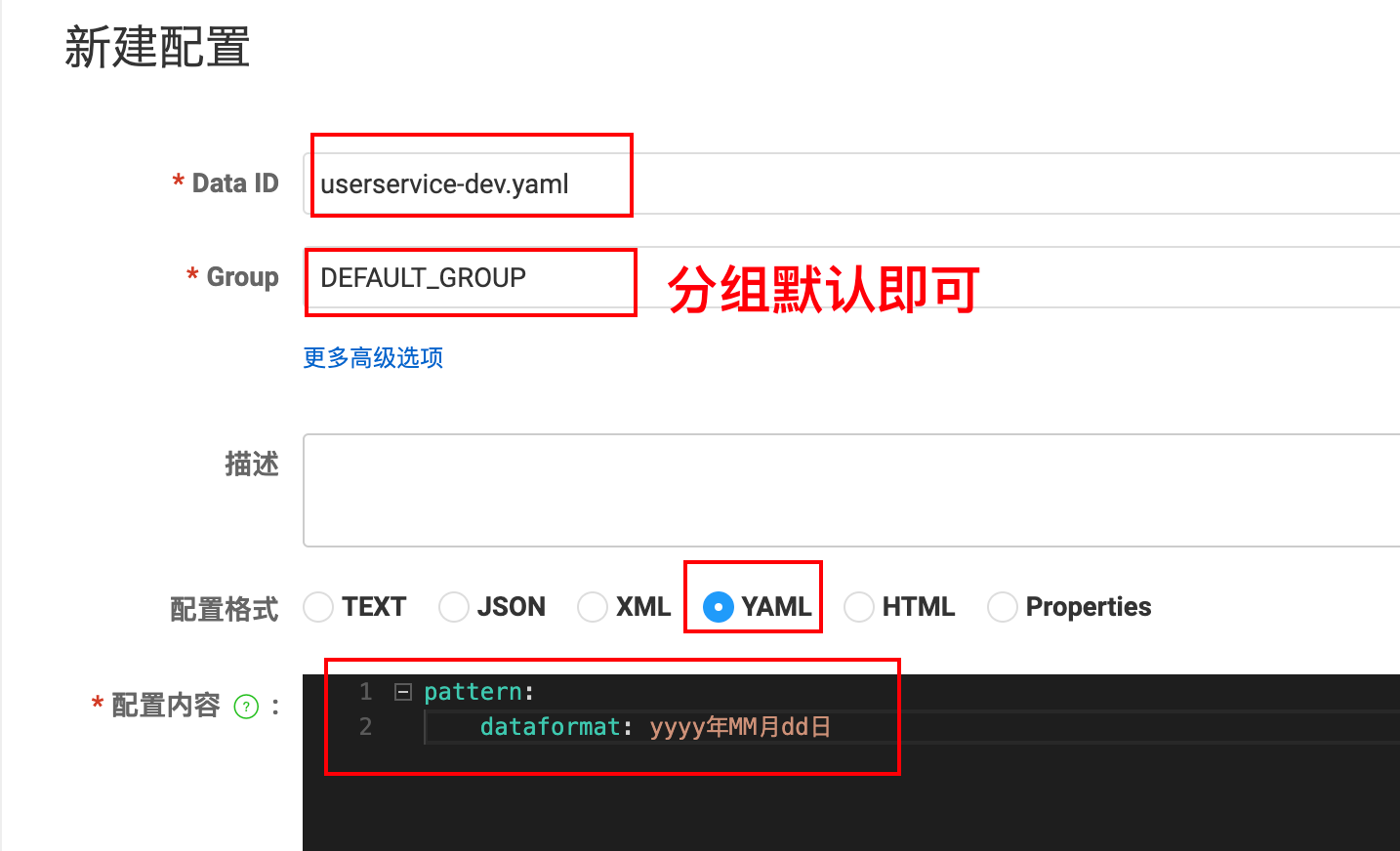
- Nacos 中新建配置文件,命名规则:
服务名称-环境.yaml,在其中编写易于变化的配置。 - 微服务程序中引入
nacos-config依赖。 - 编写
bootstrap.yml文件,这些配置决定了微程序会去读取哪一个Nacos配置文件。- Nacos地址
- 服务名称
- 当前环境
- 文件后缀名
- Nacos 中新建配置文件,命名规则:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
spring:
application:
name: userservice
profiles:
active: dev # 环境
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
username: nacos
password: nacos
discovery:
ephemeral: false
-
**【热更新】**实现:
在【统一配置】的基础上,代码中有两种方式可以实现热更新:
- 方式一:
@RefreshScope+@Value (${属性key})注解 - 方式二:
@ConfigurationProperties
两种方式不存在优劣,只是在形式作用上有些许差别,如果只想绑定少量属性方式一、否则方式二。
@RestController @RequestMapping("users") // 热更新 @RefreshScope public class TestController { @Value("${pattern.dataformat}") String dataformat; @GetMapping("/a") String get(){ return dataformat; } }@Data @Component @ConfigurationProperties(prefix = "pattern") public class CommonConfig { String dataformat; } // 后面使用 @Autowired 注入使用 - 方式一:
7、数据持久化
在这一步,小坑特别多
将官方内嵌的小型数据库
Derby替换为MySQL
-
Nacos 默认将数据存储在内嵌数据库
Derby中,该数据库不属于生产可用的数据库,官方推荐的最佳实践是使用带有主从的高可用数据库集群,例如MySQL(而且目前只支持 MySQL )。 -
简单实现(单机版,下节集群部署):
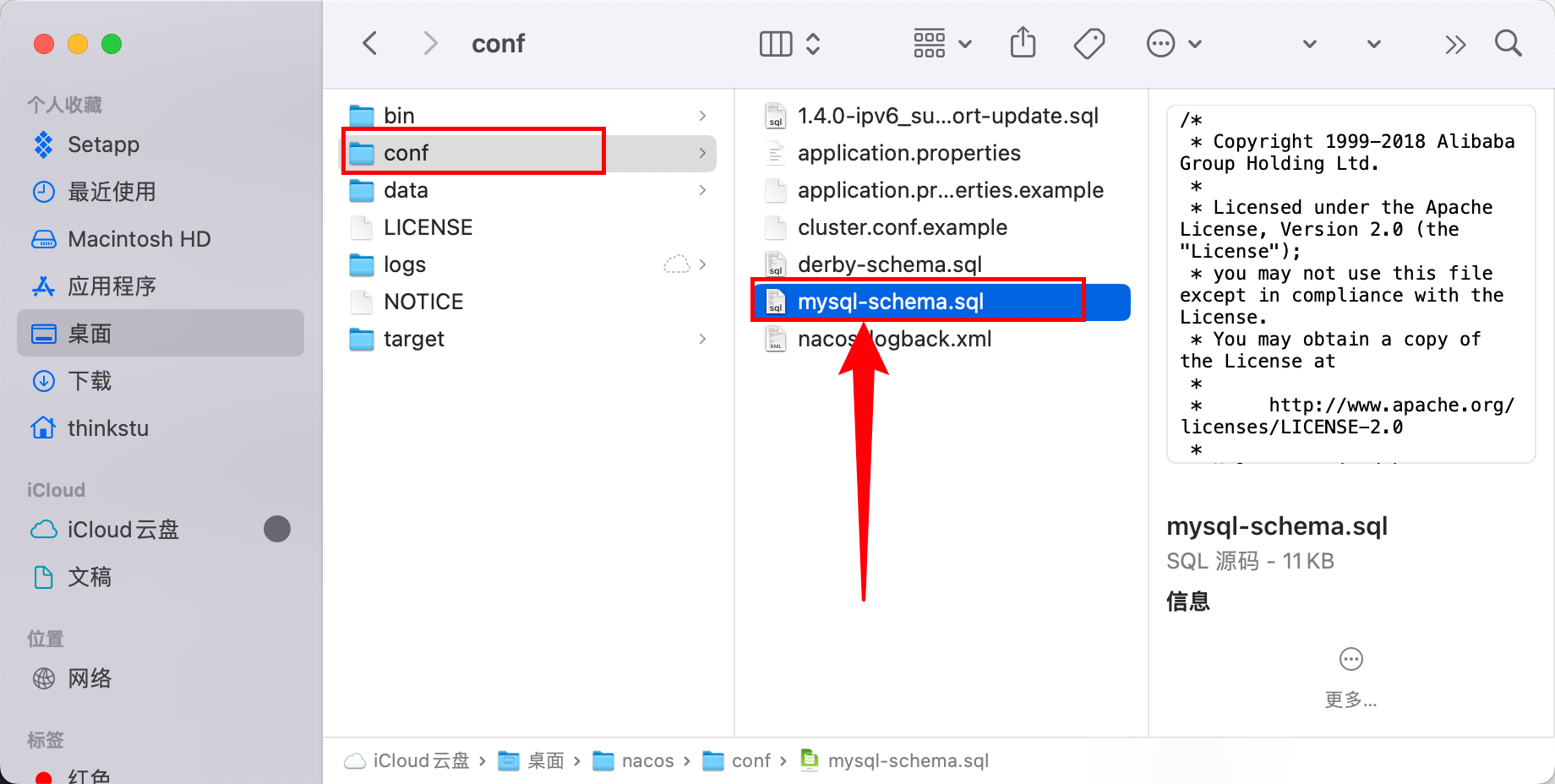
- 创建新的数据库,命名为:
nacos(其实命名什么也无所谓,后面要用到) - 打开 Nacos 目录,在数据库
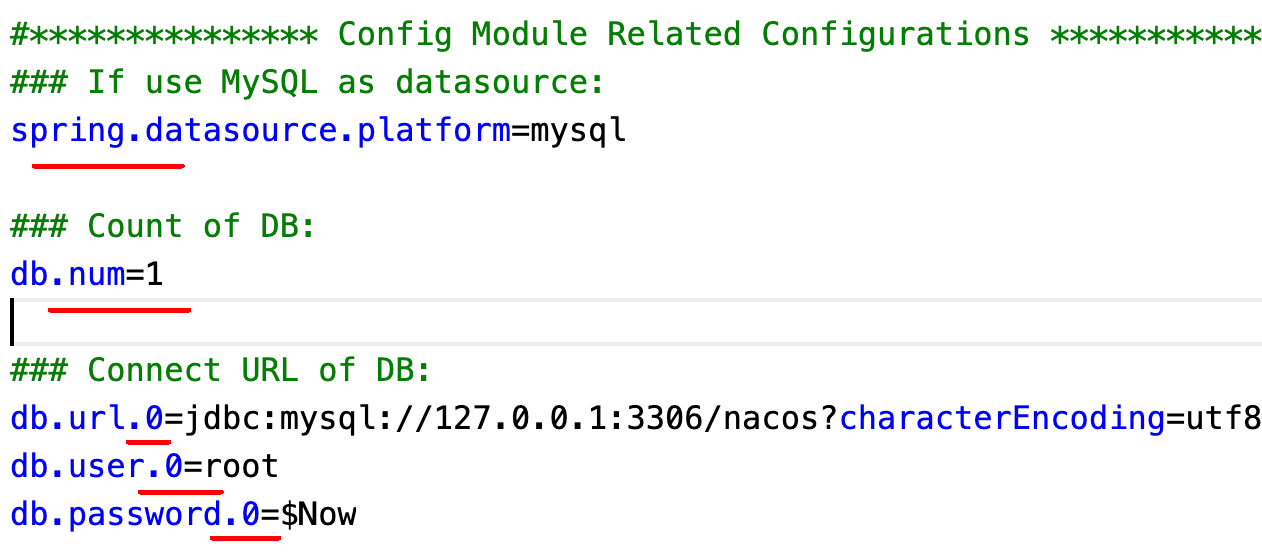
nacos中运行数据库文件/conf/mysql-schema.sql建表。 - 配置
application.properties:打开配置文件,将注释解除、然后添加数据库信息。 - 重启 Nacos:注意,在这一步时,我尝试数次都未能成功将 Nacos 重启,控制台各种报错信息,例如:
namespaceControllerV2,然而真正的报错信息却隐藏在控制台末尾的一小行文字,最终发现是之前后台的 Nacos 进程未完全关闭(残留),完全关闭之后再次尝试重启,成功。
- 创建新的数据库,命名为:
ps -ef |grep nacos
# 单机重启
./startup.sh -m standalone
-
其余注意点:
- 记得加数据库编号(从 0 开始),因为 Nacos 可集群部署。
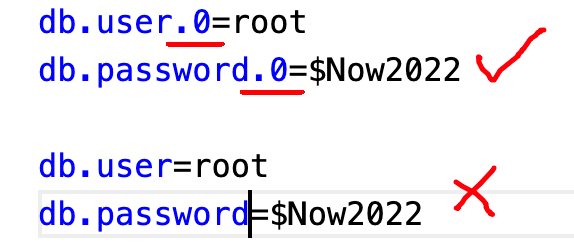
- 配置信息不添加双引号!勿随意添加,都则报错“找不到数据源”
No DataSource set。

8、集群配置
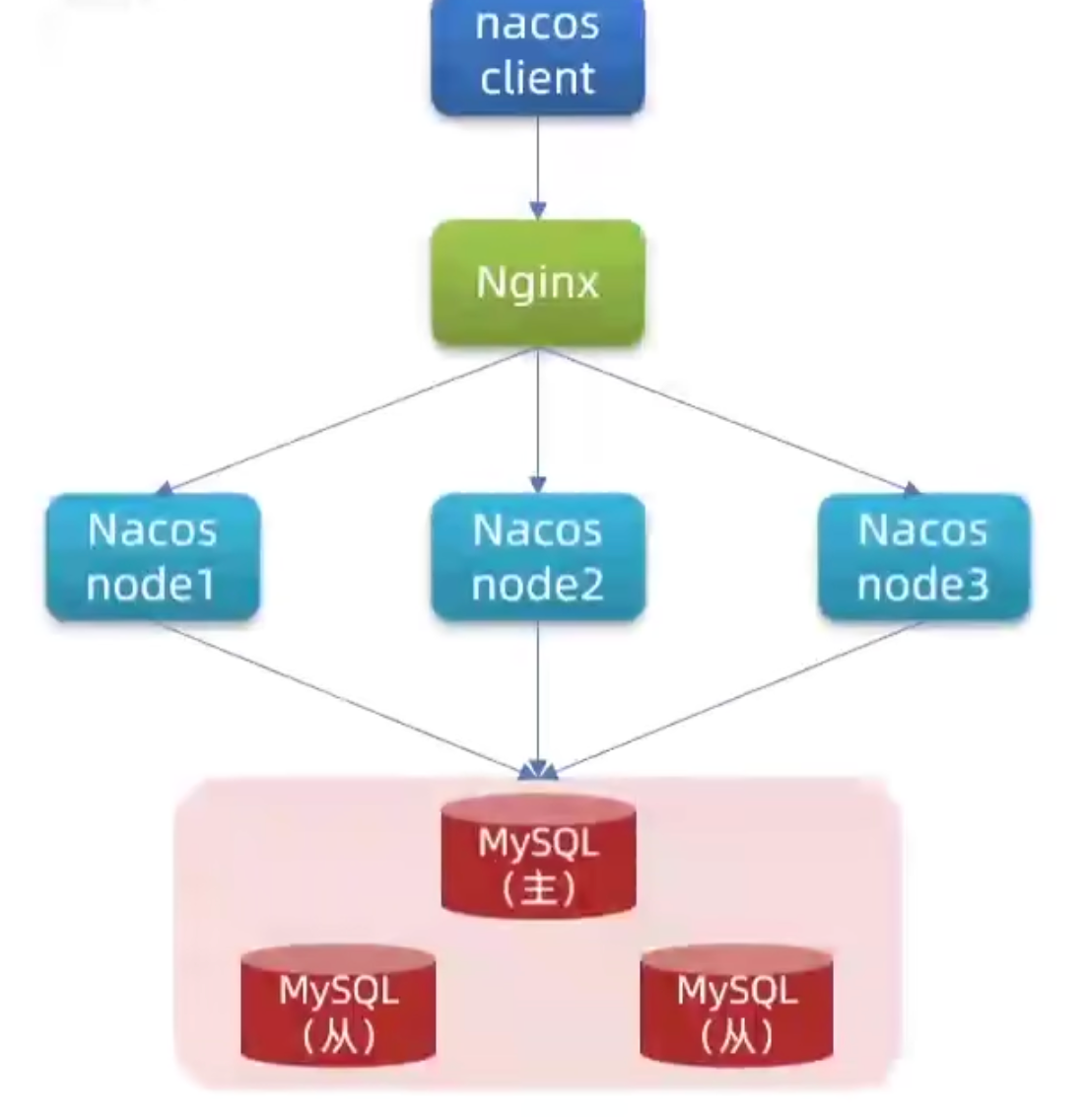
利用上节的数据持久化知识( MySQL 数据库),将3 台 Nacos 绑定同步相同的数据源,便可以做到同时更新。
- 架构图:部署 3 台 Nacos Server。
-
实现步骤:
- 新建数据库
nacos,导入/conf/mysql-schema.sql。 - 修改本地
/conf/application.properties配置文件,添加数据库 MySQL 配置。 - 将本地文件
cluster.conf.example重命名为cluster.conf,添加集群机器信息。 - 将本地
/conf/目录上传至服务器,复制 3 份/tmp/nacos/conf1、/tmp/nacos/conf2、/tmp/nacos/conf3。 - 修改 3 份配置文件端口,分别为:8845、8846、8847。
- 启动,可以成功看到 3 个 Nacos 之间的数据互相同步。
# 清理时用 docker rm -f $(docker ps -a) - 新建数据库
175.178.20.191:8845
175.178.20.191:8846
175.178.20.191:8847
cp -r /conf/ /tmp/nacos/conf1 /tmp/nacos/conf2 /tmp/nacos/conf3
docker run -d \
--env NACOS_AUTH_ENABLE=true \
-v /tmp/nacos/conf1/:/home/nacos/conf/ \
-v /tmp/nacos/logs1/:/home/nacos/logs/ \
-p 8845:8848 \
--name nacos1 \
nacos/nacos-server
docker run -d \
--env NACOS_AUTH_ENABLE=true \
-v /tmp/nacos/conf2/:/home/nacos/conf/ \
-v /tmp/nacos/logs2/:/home/nacos/logs/ \
-p 8846:8848 \
--name nacos2 \
nacos/nacos-server
docker run -d \
--env NACOS_AUTH_ENABLE=true \
-v /tmp/nacos/conf3/:/home/nacos/conf/ \
-v /tmp/nacos/logs3/:/home/nacos/logs/ \
-p 8847:8848 \
--name nacos3 \
nacos/nacos-server
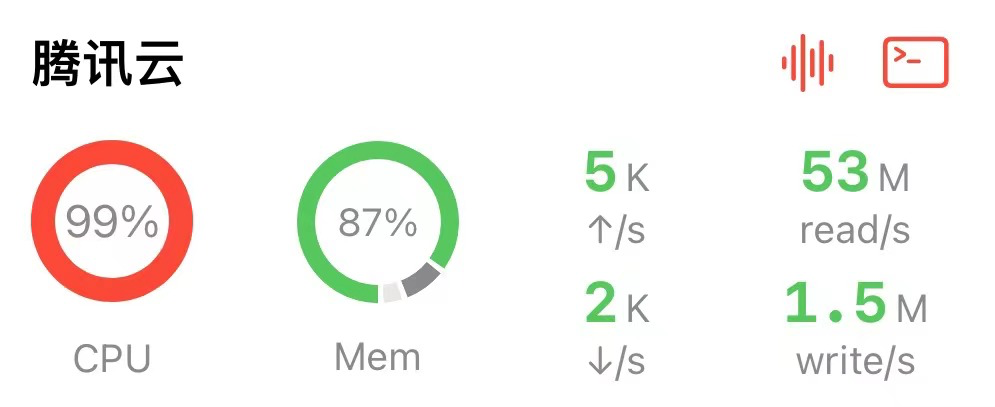
结果:腾讯云 2G2核 同时开启 3 个 Nacos,2 个成功,第 3 个失败(CPU飙满),总体算部署成功。
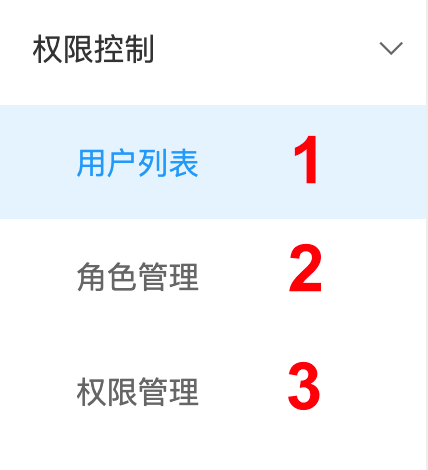
9、权限控制
右菜单栏,步骤:
- 用户管理:创建用户user
- 角色管理:创建角色role,并绑定用户
- 权限管理:赋于角色权限auth,包含对指定“命名空间”的可读写操作。
10、共享/扩展配置
共享配置 shared-configs
扩展配置 extension-config
-
简介:
日常开发中,多个模块可能会有很多共用的配置,比如数据库连接信息、Redis/RabbitMQ 连接信息、监控配置等等。那么此时我们就希望可以加载多个配置,或者多个项目共享同一个配置。
- 扩展配置:微服务所依赖的其他微服务所需要的配置文件(“依赖链条”)
- 共享配置:很多微服务共享的配置文件,例如日志打印、Swagger配置等。
两者除了优先级不同之外没有其他任何区别,都⽀持三个属性,:
data-idgroup:默认 DEFAULT_GROUP。refresh: 在配置变更时,应用内是否支持动态刷新。
-
简单范例:

spring:
application:
name: nacos-config-multi
main:
allow-bean-definition-overriding: true
cloud:
nacos:
username: ${nacos.username}
password: ${nacos.password}
config:
server-addr: ${nacos.server-addr}
namespace: ${nacos.namespace}
# 共享配置
shared-configs:
- data-id: swagger-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
- data-id: logging-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
# 扩展配置,优先级大于shared-configs (在之后加载)
extension-configs:
- data-id: content-service-${spring.profiles.active}.yaml
group: eat-plus-project
refresh: true
- data-id: dataId
group: eat-plus-project
refresh: true
11、配置文件优先级
-
基本思想:影响的范围越小,优先级越高。
-
远端 > 本地
-
带有profiles > 不带
-
配置中心(远端) > 命令行参数 > 本地application.yaml > 本地bootstrap.yaml
-
-
存在 3 种配置文件大类,优先级从上至下:
-
远端
服务名-环境.yaml服务名.yaml扩展配置.yaml共享配置.yaml
-
命令行参数
-
本地
application.propertiesapplication.yamlbootstrap.yaml
bootstrap.yaml优于application.yaml执行,application.yaml优于application.properties执行,但是后执行的会覆盖前执行的配置,所以在本地越先执行的优先级越低。
-
四、OpenFeign
声明式的 Web HTTP 服务客户端,替代原生 RestTemplate
与 Nacos 组合使用时,Nacos提供“域名”的解析服务
-
简介:
OpenFeign是一个声明式的Web服务客户端,使得编写Web服务客户端变得非常容易,只需要创建一个接口,然后在上面添加注解,便可以通过接口来调用服务端的服务。
OpenFeign 遵循 RPC 协议,即 Remote Procedure Call Protocol,远程调用协议。
历史上存在过
Feign(由 NetFlix 公司开发),SpringCloud组件中的一个轻量级RESTful的HTTP服务客户端,也是SpringCloud中的第一代负载均衡客户端。OpenFeign是SpringCloud自己研发的,在Feign的基础上支持了Spring MVC的注解,如@RequesMapping等,是SpringCloud中的第二代负载均衡客户端。 -
与 Ribbon 的关系:
OpenFeign默认将Ribbon作为负载均衡器,直接内置了 Ribbon。在导入OpenFeign 依赖后无需专门导入Ribbon 依赖。所以说,当我们需要更改 OpenFeign 的负载均衡策略时,其实就是需要修改 Ribbon 的策略,直接按照 Ribbon 的策略配置方式就行配置(即分为两种方式:全局与局部)。
-
步骤:
-
引入依赖
-
主类添加
@EnableFeignClients注解,声明使用 Feign。 -
使用注解
@FeignClient()编写具体的 FeignClient 接口。 -
@Autowired注入对应 FeignClient 并使用。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>@EnableFeignClients@FeignClient("userservice") public interface UserClient { // 此处是接口不是普通类 @GetMapping("/user/{id}") User findById(@PathVariable Long id); // 注意需标注成“路径参数” }@Autowired UserClient userClient; -
-
FeignClient接口定义说明(5大定义),以上面举例:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
-
其余配置
# 开启 Gzip 压缩 feign: compression: request: enabled: true min-request-size: 2048 mime-types: text/xml, application/xml, application/json response: enabled: true useGzipDecoder: true -
【自定义配置】
一般我们可能只需要配置“日志级别”就好了。

可以使用两种方式配置日志级别,一般使用
None(默认,不打印)或Basic,避免控制台打印过多信息。- yml配置文件(推荐)
- Java代码(麻烦,省略)
feign: client: config: default: # 全局生效 logger-level: fullfeign: client: config: userservice: # 局部(指定微服务)生效 logger-level: full# Basic 级别打印的日志 [UserClient#findById] ---> GET http://userservice/user/2 HTTP/1.1 [UserClient#findById] <--- HTTP/1.1 200 (537ms) -
优化Feign
Feign 底层的客户端实现有 3 种
- URLConnection(默认):JDK自带、不支持连接池
- Apache Httpclient:支持连接池
- OKHttp:支持连接池
使用连接池可以复用连接(避免在连接时多次产生3次握手4次挥手),更改为OKHttp使用步骤如下:
- 引入 Feign-okhttp 依赖
- yml配置开启
<dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-okhttp</artifactId> </dependency>feign: okhttp: enabled: true -
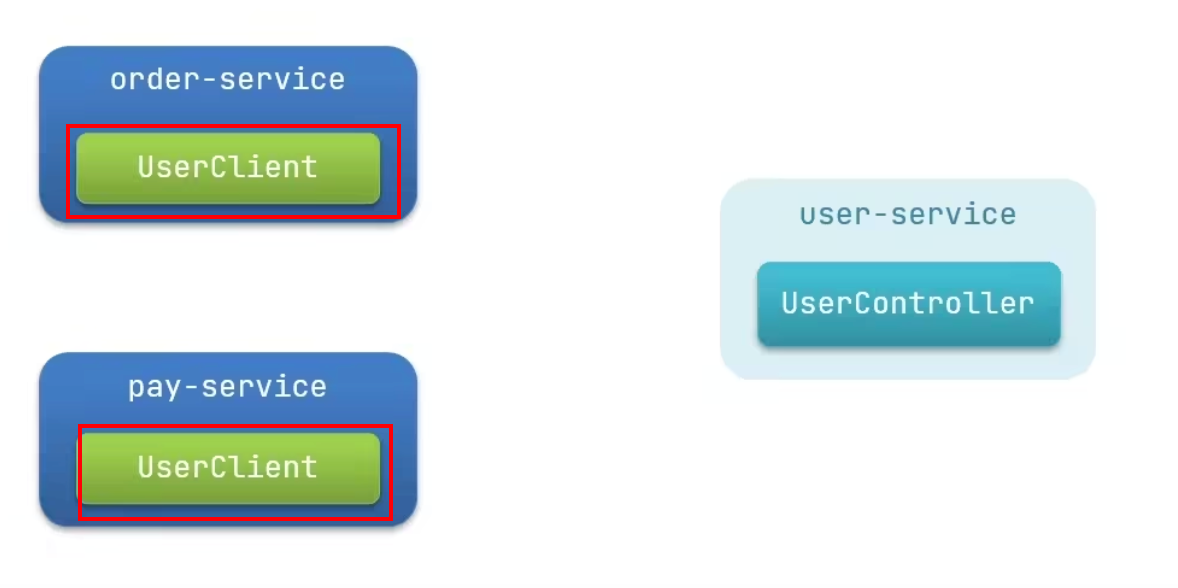
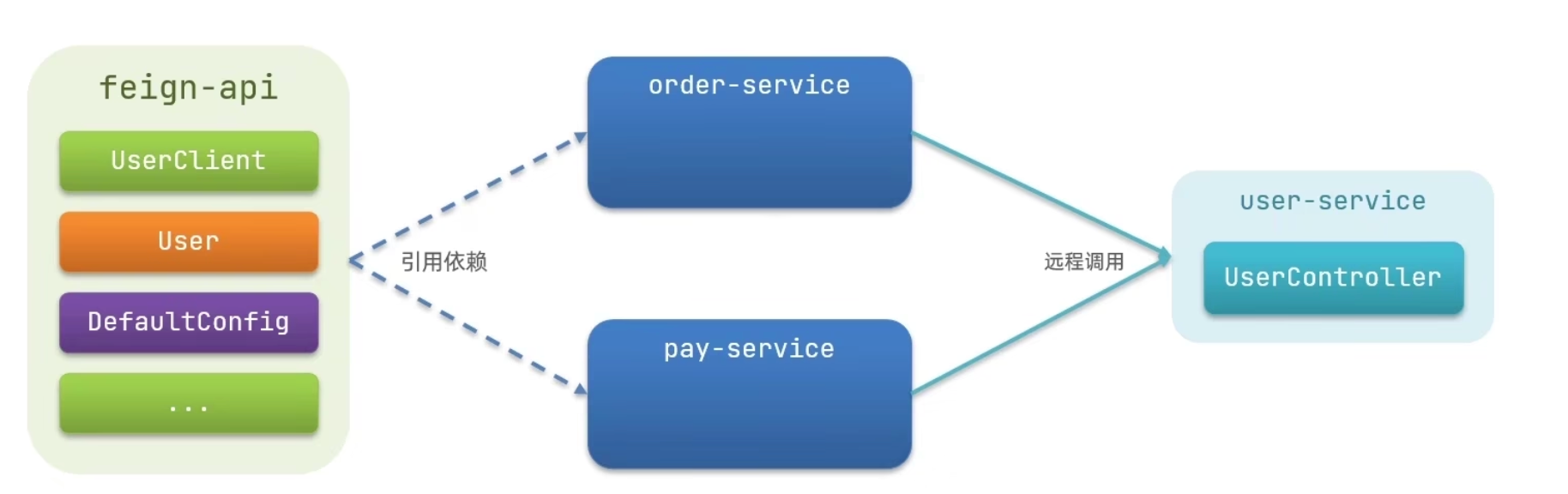
Feign最佳实践:
- 解决多份配置文件的尴尬,当然也存在弊端
- 将共用的代码抽取成
jar包,使用依赖的方式进行导入。
(之前)
(现在)
五、Geteway
Spring Gateway
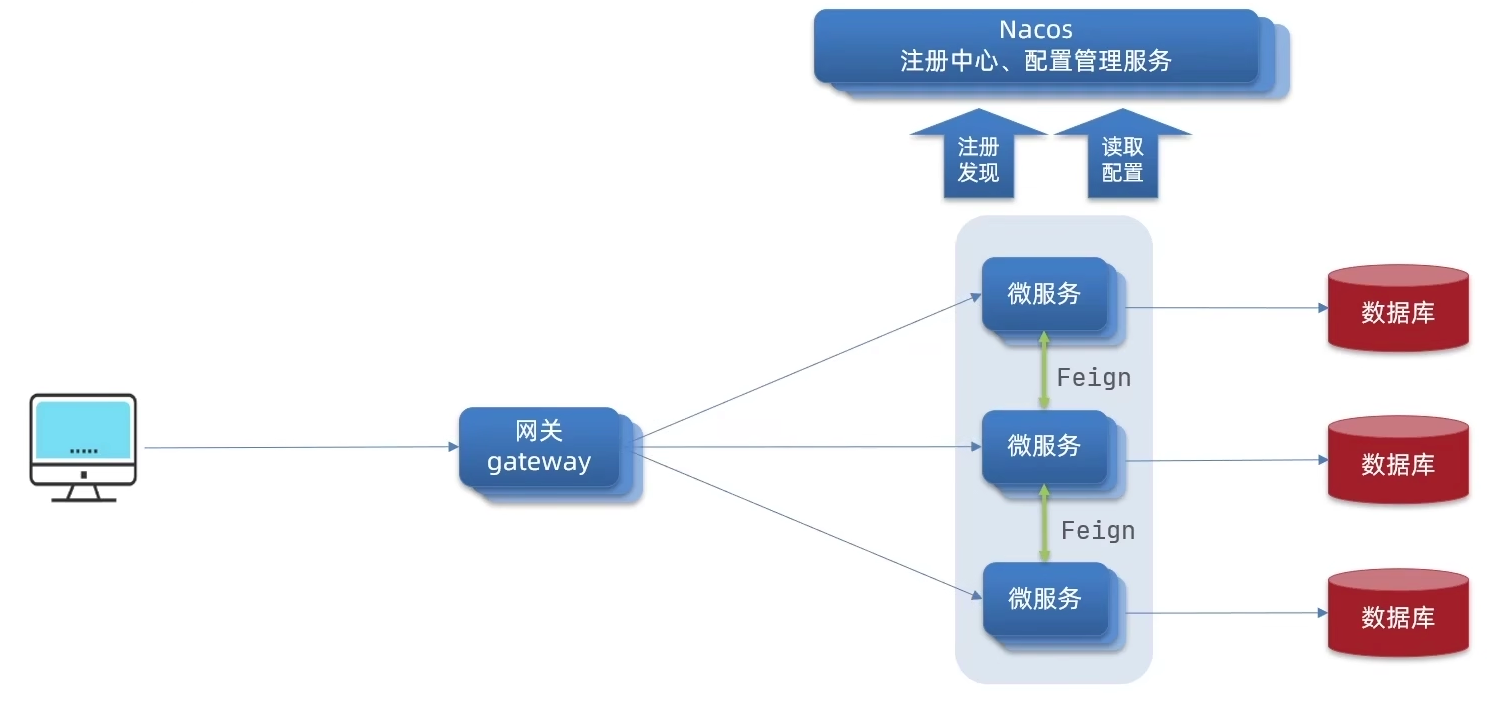
-
简介
- Gateway与 Nginx 在操作的思想上是一样的,但是具体实现不同
- Gateway:业务网关。针对每一个微服务的网关,更接近具体业务。
- Nginx:流量网关。用户访问的总入口,也就是前端页面的容器。
-
网关的作用:
- 身份认证、权限校验
- 服务路由、负载均衡
- 请求限流
-
Spring Cloud网关类型
- Gateway(新):Spring5 中提供的 WebFlux,响应式编程,性能更好。
- zuul(旧):基于 Servlet 实现,阻塞式编程。
-
实现:
本质:创建单一Spring程序用于 Gateway 实现路由转发,单一 jar 包。
- 引入依赖
- yml配置
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>下面定义了 2 个路由规则
server: port: 10080 spring: application: name: gateway cloud: nacos: server-addr: http://localhost:8848 discovery: cluster-name: HZ gateway: routes: - id: user-service # 路由标识,全局唯一 uri: lb://userservice # 路由的地址,lb:load balanced 负载均衡 predicates: - Path=/user/** # 路由断言,如果路径以 /user/ 开头则符合 default-filters: - AddRequestHeader=Content-type,text/html # 添加请求头 - id: order-service uri: lb://orderservice predicates: - Path=/order/** default-filters: - AddRequestHeader=Content-type,text/html -
网关路由的【配置项】包括:
- 路由id:路由唯一标识
- uri:路由目的地址,支持
http与lb两种类型。 - predicates:路由断言,判断是否符合要求
- filters:路由过滤器,清理请求或响应。
-
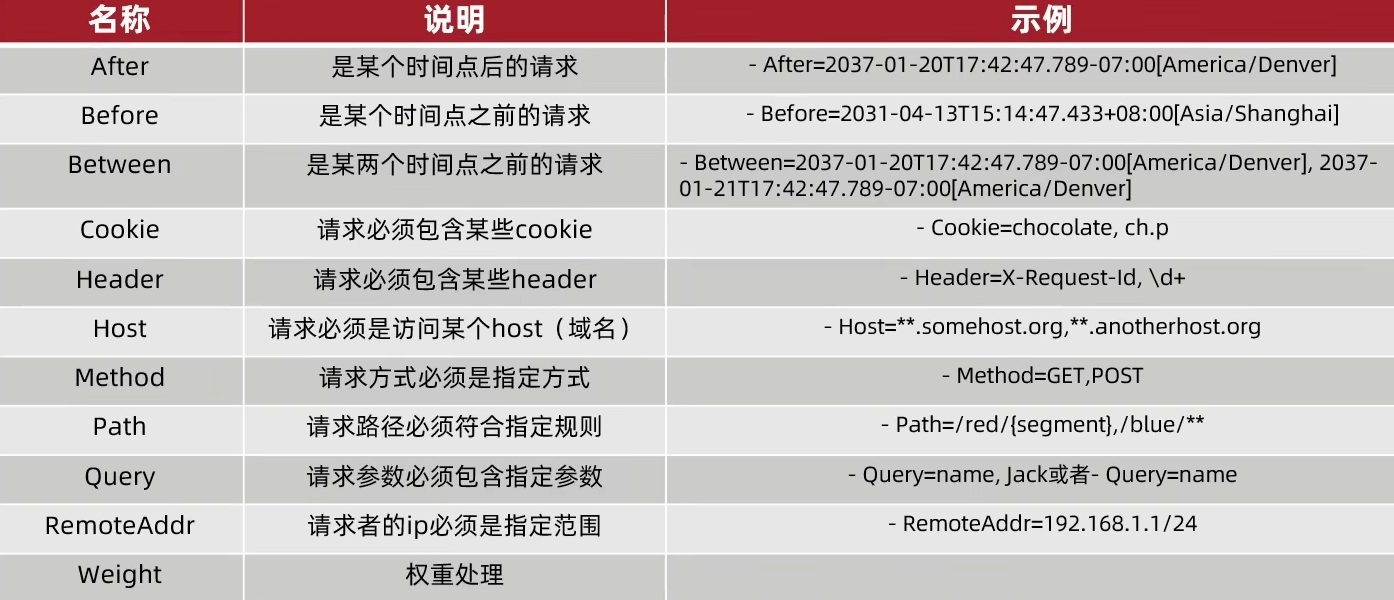
11种基本的 Predicate 类型(上面范例使用了 Path )
-
3种过滤器
- 默认过滤 defaultFilter
- 局部过滤
- 全局过滤
-
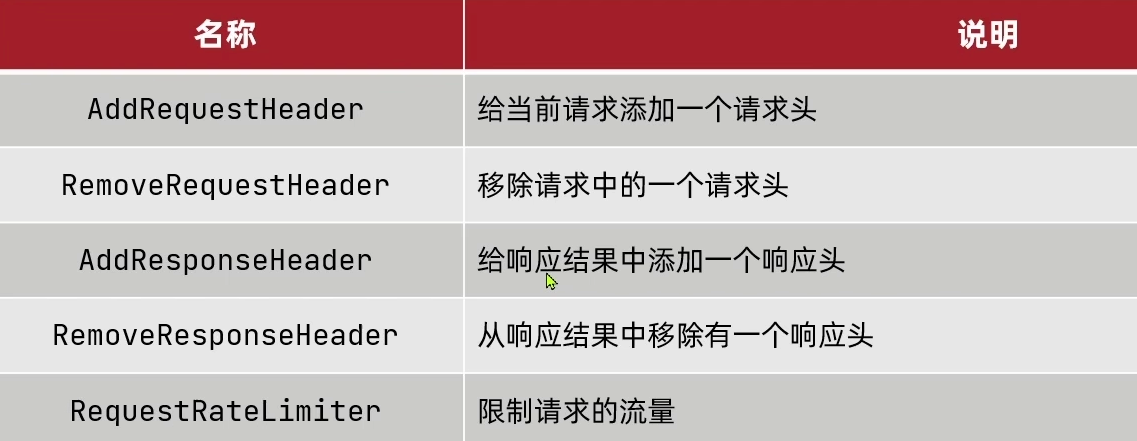
过滤器的31种细分类
种类过多,需要时查看官方文档即可(只要查看名字就能得知该过滤器的作用 )
-
过滤器的优先级说明:
这里稍有点乱
- 首先按照所设置的 Order 顺序来。
- 当 Order 值一样时,执行顺序:默认过滤 → 局部过滤 → 全局过滤,即:
- 请求时,最后全局过滤生效
- 响应时,最后默认过滤生效
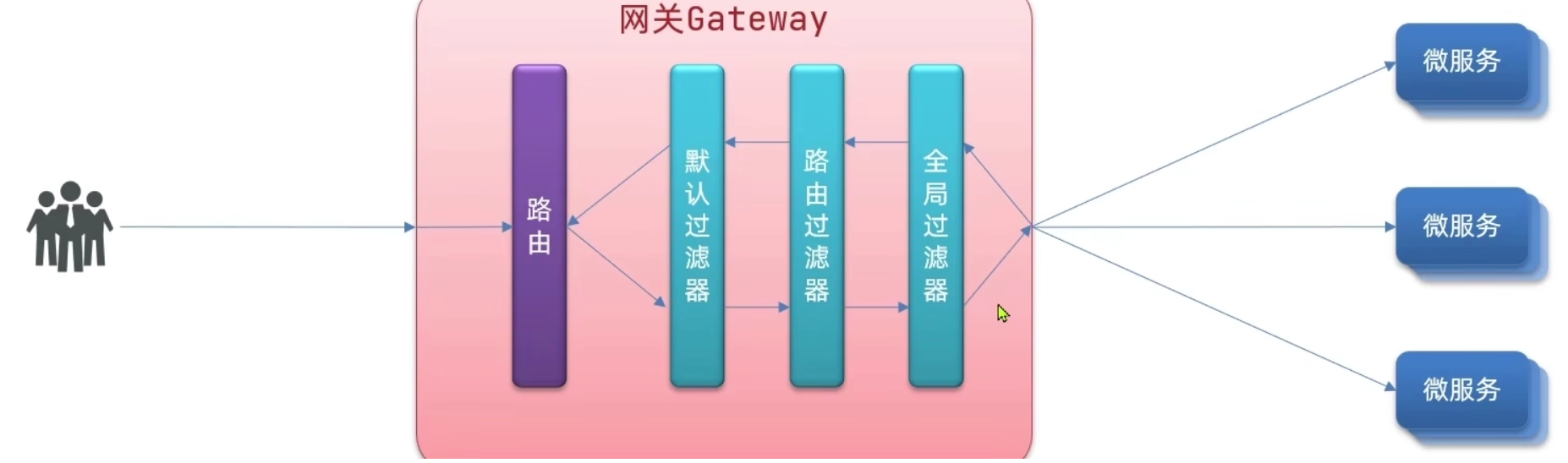
-
简单案例
- 默认过滤:yml配置、灵活度低,默认生效
# 默认过滤(也对全局生效,默认此) default-filters,对所有路由生效
spring:
cloud:
gateway:
routes:
- id: user-service # 路由标识,全局唯一
uri: lb://userservice # 路由的地址,lb:load balanced
predicates:
- Path=/user/** # 路由断言,如果路径以 /user/ 开头则符合
default-filters:
- AddRequestHeader=Content-type,text/html # 添加请求头
- 局部过滤:yml配置、灵活度低,对指定路由生效
spring:
cloud:
gateway:
routes:
- id: user-service # 路由标识,全局唯一
uri: lb://userservice # 路由的地址,lb:load balanced
predicates:
- Path=/user/** # 路由断言,如果路径以 /user/ 开头则符合
filters:
- AddRequestHeader=Content-type,text/html # 添加请求头
- 全局过滤:代码配置、灵活度高。创建 Bean,继承
GlobalFilter接口并重写 filter() 方法,此处注意:@Order(-1)表示优先级,值越低优先级越高,允许负值。exchange参数属于 Spring WebFlux 组件中的知识,它用来获取请求与响应两者,但是例如获取出来的请求request不是 servlet 的静态技术,而是属于 WebFlux 的动态技术,即ServerHttpRequest(注意是以 Server 开头而不是 Servlet )。chain参数用来生成成功时的返回值Mono<Void>- 当校验失败时,使用
exchange设置失败的响应码,如401 Forbidden 并返回给客户端。 Mono<Void>是什么暂时不用管

-
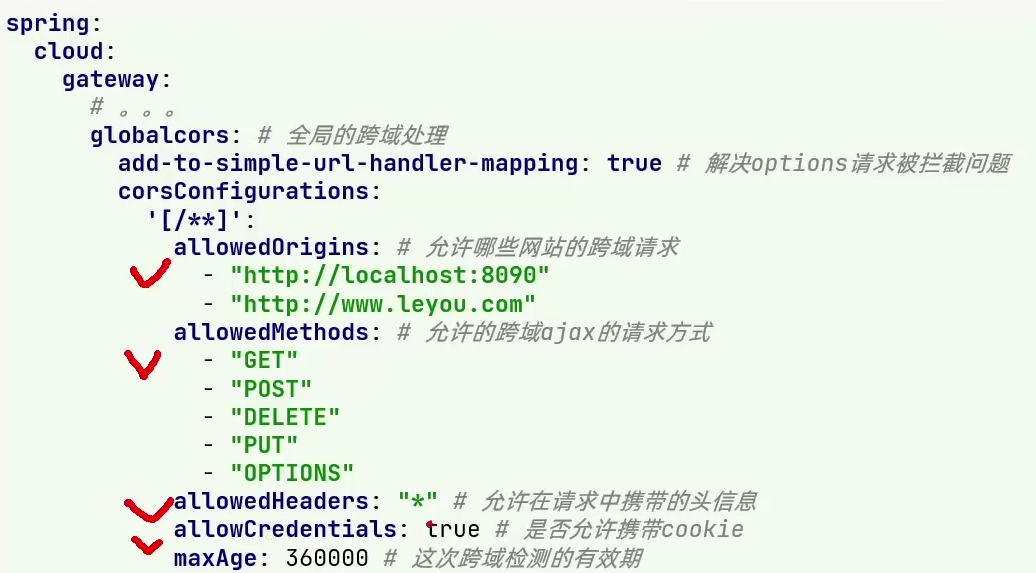
CORS跨域处理
Spring Boot 也可以实现跨域处理,并不一定要依赖于 Spring Gateway
禁止跨域是浏览器的策略,后端之间互相调用接口不存在跨域。
允许浏览器跨域一般需要配置的 5 大选项,并在 yml 文件中配置,如下:
- 允许的域名
- 允许的端口
- 允许的方式
- 是否允许使用Cookie
- 有效期是多少(浏览器在第一次跨域时会发送
Options请求,得到确认后在指定的有效期内不会重发Options请求,节约资源)
六、Docker
这章暂时跳过,具体内容查看:Docker笔记
- 将程序以及依赖、运行环境打包成镜像。
- Spring Cloud + docker compose案例:链接
七、RabbitMQ
MQ:Message Queue 消息队列
我们在大多数情况下使用【同步通信】,因为对时效性的要求较强
1、简介
-
【同步通信】:
-
优点:时效性强、可以立即得到结果
-
缺点:业务之间耦合度高、性能和吞吐能力低、存在额外的资源消耗与级联失败的情况。
-
-
【异步通信】:
-
优点:耦合度高、吞吐量能力强、故障隔离、流量削峰
-
缺点:对消息中间件的可靠性、安全性、吞吐能力有严重的依赖,业务架构复杂,没有明显的流程线、难以追踪管理
-
-
4 种不同形式的 MQ 产品:

2、RabbitMQ
消息一旦消费完就会被删除,RabbitMQ 没有消息回溯功能
-
docker 版本安装:
docker pull rabbitmqdocker run -it \ -e RABBITMQ_DEFAULT_USER=user \ -e RABBITMQ_DEFAULT_PASS=123 \ -v mq-plugins:/plugins \ --name=mq \ -hostname=mq \ -p 15672:15672 \ -p 5672:5672 \ rabbitmq下面代码全部在容器内操作:
rabbitmq-plugins enable rabbitmq_managementcd /etc/rabbitmq/conf.d/ echo management_agent.disable_metrics_collector = false > management_agent.disable_metrics_collector.conf # 退出并重启容器 exit docker restart mq15672: web 界面访问端口,需要进入容器内手动开启5672:具体的通信端口- 账号为
user,密码为123 plugins:RabbitMQ插件目录,提供后续插件安装接口
-
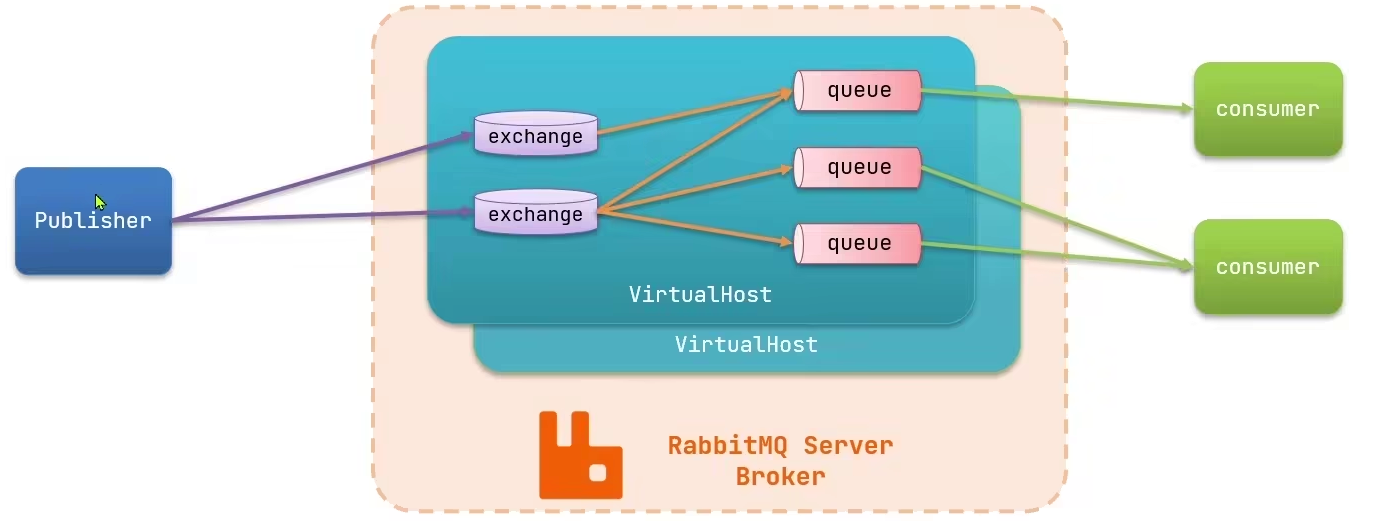
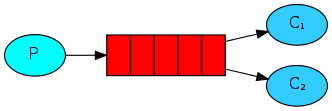
常见的5种消息模型
- BasicQueue:基本消息队列
- WorkQueue:工作消息队列
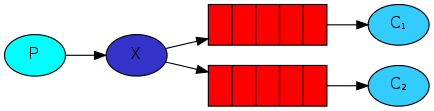
- 发布订阅模式:
- Publish/Subscribe:广播(Fanout)
- Routing:路由(Direct,常用)
- Topics:主题(Topic)

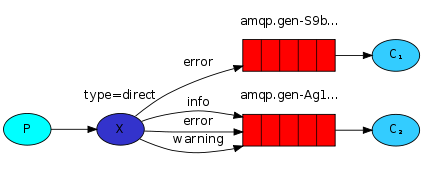
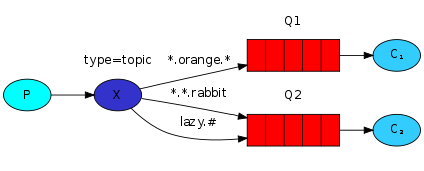
-
【注意】:
- BasicQueue 与 WorkQueue 中不存在 Exchange交换机,只存在 Queue队列。
- 而在“发布订阅模型”中,存在 Exchange交换机 + Queue队列。
- 交换机可以将消息转发给多个队列,队列中的消息只能被消费一次,用完即删除
- 交换机只负责消息路由,不负责存储消息,如果路由失败则丢失信息。
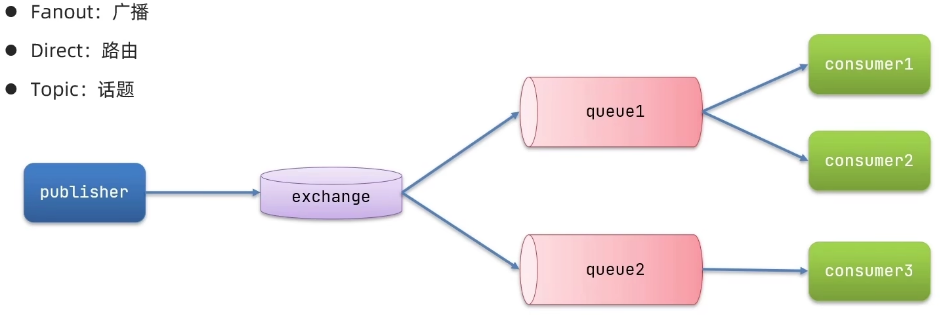
-
RabbitMQ实现流程:
- 配置连接参数
- 建立连接
- 创建通道
- 创建队列(赋予名称,指定要操作的队列)
- 发送消息(接收消息)
- 关闭通道和连接
3、SpringAMQP
Spring 简化原生代码
-
简介:
- AMQP:Advanced Message Queuing Protocol,高级消息队列协议,是一种用于在应用程序之间传递业务信息的开放标准。
- Spring AMQP:基于 AMQP 实现的一套标准API规范,提供模板实现消息的发送和接收。例如
Spring-amqp是接口,具体的实现有spring-rabbit(即RabbitMQ)等。
-
BasicQueue实现:
- 引入依赖
- yml 配置 MQ 地址、账号密码等信息
- 代码发送与接收信息
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>spring: rabbitmq: host: 10.211.55.4 port: 5672 virtual-host: / # 配置虚拟主机名(不同的虚拟主机之间存在分割,无法互相访问) username: user password: 123发送消息:使用
RabbitTemplate模板类@Autowired RabbitTemplate template; @Test public void sendMessage(){ String queueName="simple.queue"; Object message="你好MQ!"; template.convertAndSend(queueName,message); }接收消息:使用
@RabbitListener注解@Component public class SpringRabbitListener { @RabbitListener(queues = "simple.queue") public void listener(String msg){ System.out.println("【接收到消息】:"+msg); } } -
WorkQueue实现:
即多个接收队列,提高队列接收的速度。
注意这里存在:“贪心的消费者”(消息预取),即消费者会优先获取消息,(不管当下能不能立即执行),此时需要设置消费预取上限,例如设为
1,即一次一次的取。spring: rabbitmq: host: 10.211.55.4 port: 5672 virtual-host: / # 配置虚拟主机名(不同的虚拟主机之间存在分割,无法互相访问) username: user password: 123 listener: direct: prefetch: 1 # 消息预取数量限制为 1 ,默认为无限、即不作限制 -
publish/subscribe实现:
广播Fanout,交换机将消息转发至所有队列
先将队列与 Exchange 交换机建立绑定关系,然后
publisher向交换机发送消息,交换机自动将消息转发至各队列,subscribe向队列请求消息。队列与交换机之间的绑定有两种形式:代码实现、注解实现,这里使用 代码实现 ,后续使用 注解实现 形成对比。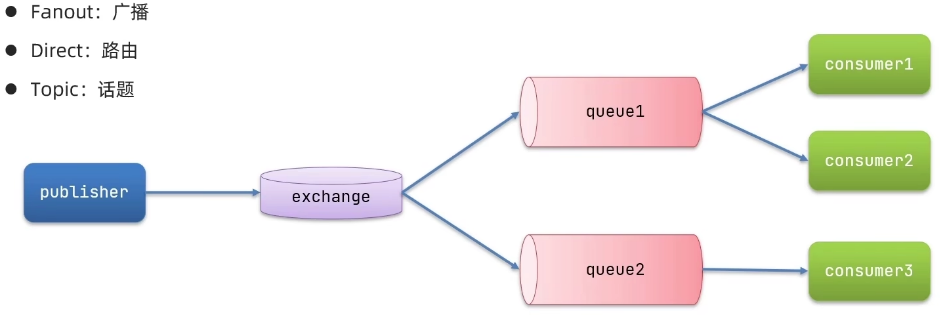
代码实现:建立交换机与队列之间的绑定关系
// 声明(创建)交换机 @Bean public FanoutExchange fanoutExchange(){ return new FanoutExchange("myExchange"); } // 声明(创建)队列 @Bean public Queue fanoutQueueOne(){ return new Queue("myQueue.one"); } // 绑定交换机与队列 @Bean public Binding binding(Queue fanoutQueueOne,FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueueOne).to(fanoutExchange); } // 以相同的方式声明第二个队列...接收消息(代码几乎不变)
@Component public class SpringRabbitListener { @RabbitListener(queues = "myQueue.one") public void listener1(String msg){ System.out.println("【 1 接收到消息】:"+msg); } @RabbitListener(queues = "myQueue.two") public void listener2(String msg){ System.out.println("【 2 接收到消息】:"+msg); } }发送消息
@Autowired RabbitTemplate template; @Test public void sendMessage(){ String exchangeName="myExchange"; Object message="你好MQ!"; template.convertAndSend(exchangeName,"",message); // 中间参数为routingkey,下节使用 } }

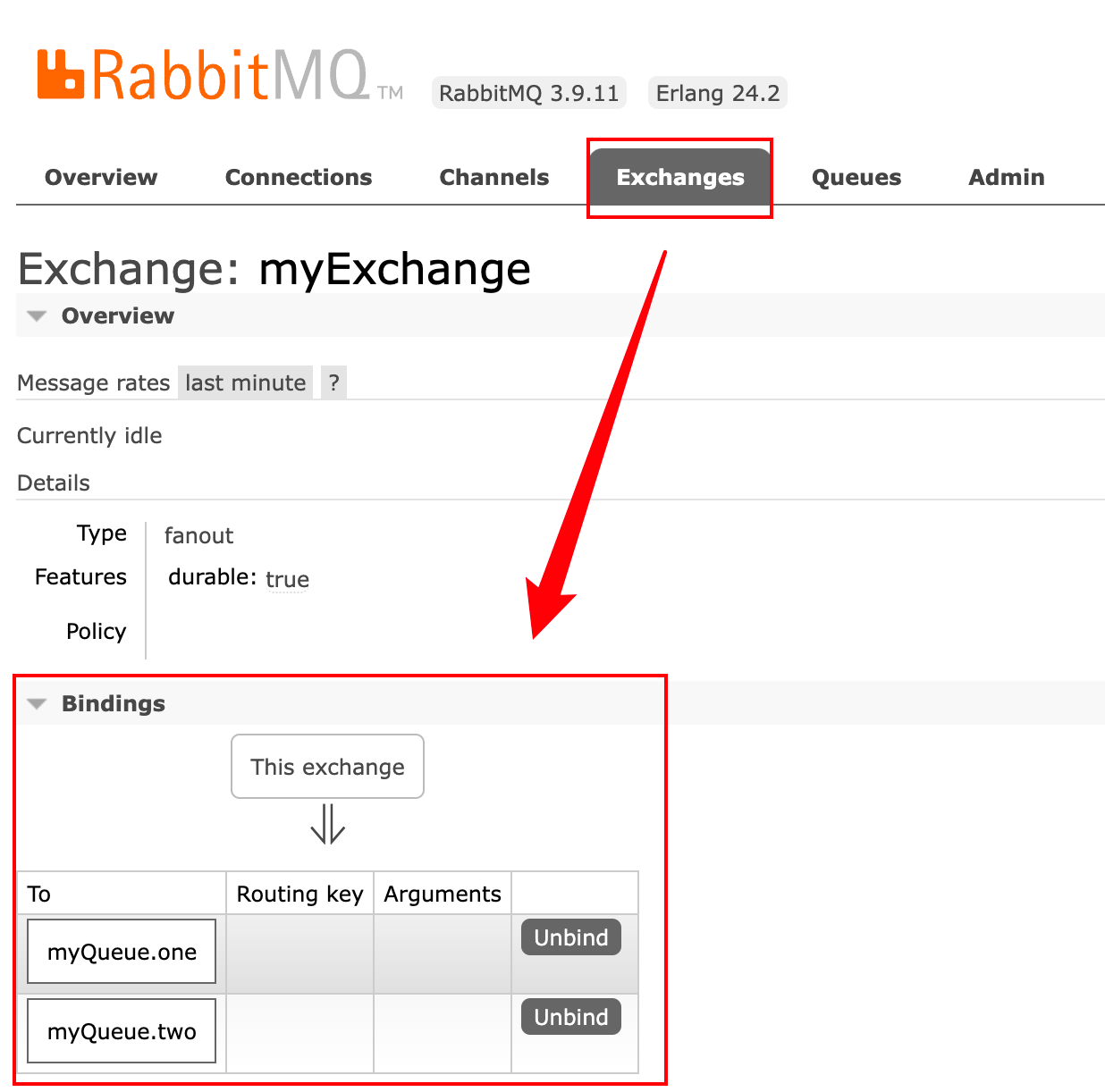
-
Routing实现:
交换机根据规则
routingkey将消息路由至指定队列(对暗号),消息发送者在发送消息时指定routingkey,队列在建立时绑定routingkey(可以绑定多个key) ,符合则接收。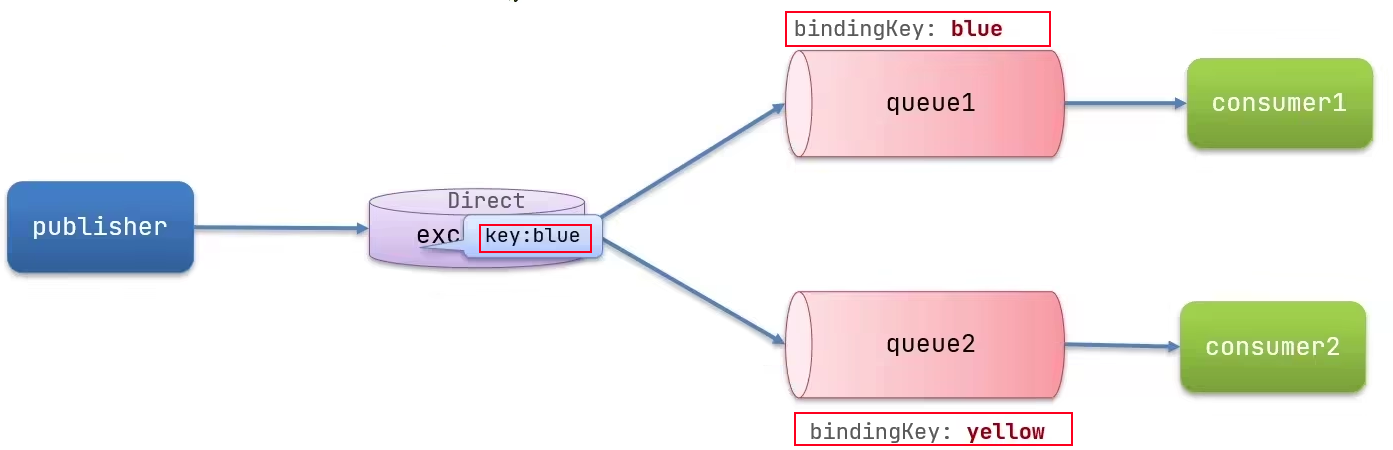
注解实现:在接收消息时,顺便建立交换机与队列之间的绑定关系(注解里面套注解,第一次见)
@Component
public class SpringRabbitListener {
// 第一个
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = “direct.queueOne”),
exchange = @Exchange(name = “myEx”,type = ExchangeTypes.DIRECT),
key = {“red”,“blue”}
))
public void listener1(String msg){
System.out.println(“【 1 接收到消息】:”+msg);
}
// 第二个
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queueTow"),
exchange = @Exchange(name = "myEx",type = ExchangeTypes.DIRECT),
key = {"red","yellow"}
))
public void listener2(String msg){
System.out.println("【 2 接收到消息】:"+msg);
}
}
发送消息
```java
@Autowired
RabbitTemplate template;
@Test
public void sendMessage(){
String exchangeName="myEx";
Object message="你好MQ!";
// 第二个参数 routingkey 指定发送的“规则”
template.convertAndSend(exchangeName,"yellow",message);
}
}
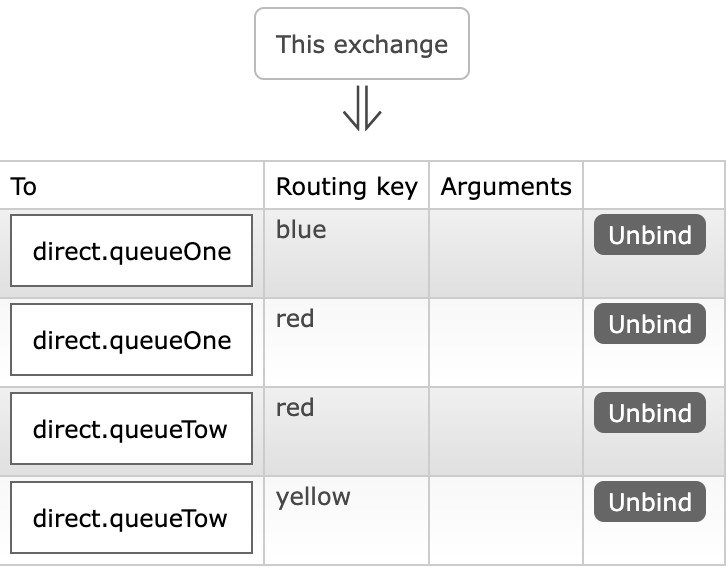
-
Topics实现:
Topic 与 Direct 类似,区别在于 routingKey 必须是多个单词的列表,以
.分割,并且支持通配符#与*。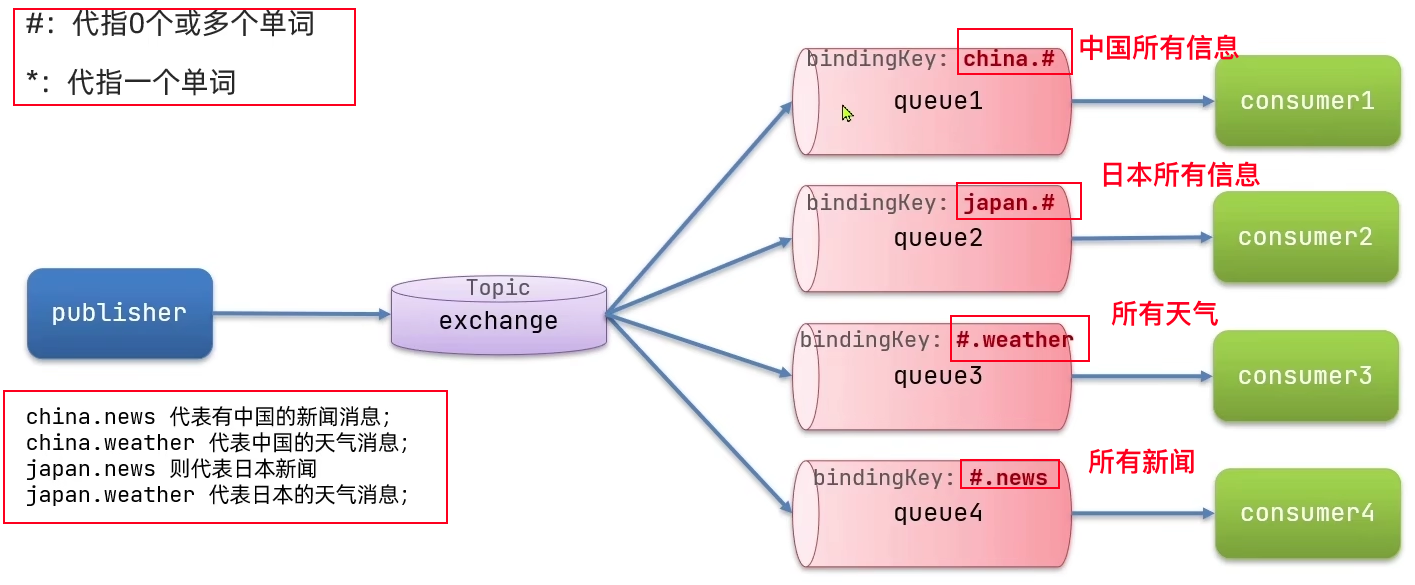
@Component public class SpringRabbitListener { // 注意要将交换机类型修改为Topic:type = ExchangeTypes.TOPIC @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topics.queueOne"), exchange = @Exchange(name = "myExchangeTwo",type = ExchangeTypes.TOPIC), key = {"China.#","#.news"} )) public void listener1(String msg){ System.out.println("【 1 接收到消息】:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topics.queueTow"), exchange = @Exchange(name = "myExchangeTwo",type = ExchangeTypes.TOPIC), key = {"America.#","#.news"} )) public void listener2(String msg){ System.out.println("【 2 接收到消息】:"+msg); } }@Autowired RabbitTemplate template; @Test public void sendMessage(){ String exchangeName="myExchangeTwo"; Object message="你好MQ!"; template.convertAndSend(exchangeName,"China.news",message); }
4、消息转换器
在这里我们将替换 Spring 默认提供的消息转换器,以提高性能。
为什么要替换呢?
因为Spring默认的消息处理接口是org.springframework.amqp.support.converter.MessageConverter,默认实现为:SimpleMessageConverter,且基于 JDK 的 ObjectOutputStream 实现序列化,这种序列化方式在处理对象的时候会将对象编码并且经过Base64编码,不仅会占用更多的内存空间,而且会导致性能下降。

解决方法即采用 JSON 格式,例如引入Jackson依赖并实现:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.14.1</version>
</dependency>
@Configuration
public class CommonConfig {
// 更换消息转换器
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
}
当然,以上配置在消息【发送者】与【接收者】之间都需要配置,后续发送什么类型的消息,就使用什么类型接收(这点需十分注意,我在第一次编写时就忘记了修改消息的接收类型导致 Converter error)。

八、ES初级
Elasticsearch,基于 Java 实现的分布式搜索:中文官网
1、简介
-
Elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量的数据中快速找到所需内容。
-
具体功能:内容搜索、日志统计与分析、系统监控等。
-
Elasticsearch对内存的消耗特别大,少于512MB直接启动失败。
-
注意以下安装的所有软件版本需与 Elasticsearch 保持一致
-
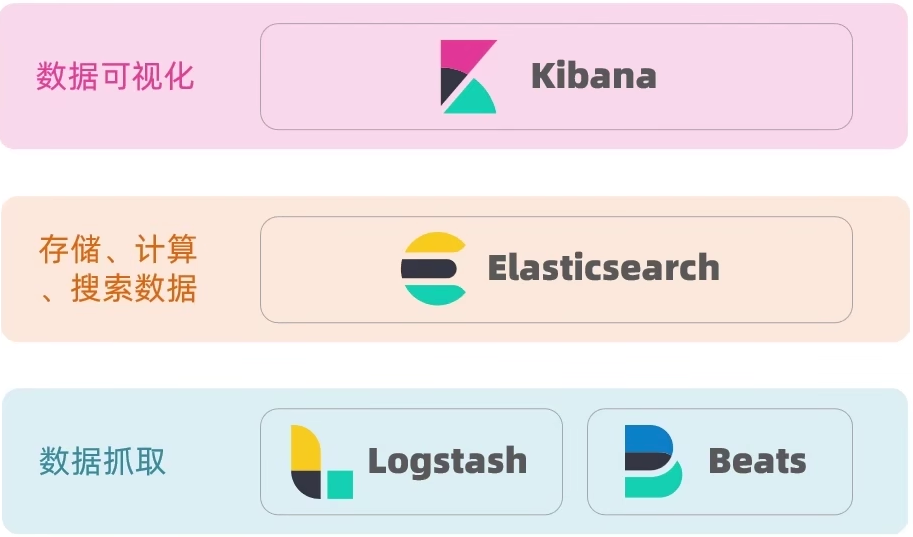
Elasticsearch结合 Kibana、Logstash、Beats,被称为「elastic stack」(也就是ELK),被广泛运用在日志数据分析、实时监控等领域。
-
Elasticsearch基于 Lucene,Lucene既是一个 Java 语言的搜索引擎类库,也是Apache公司的顶级项目之一。
-
Elasticsearch中,文档数据会以
JSON格式存储,即全部文本字段都需添加双引号。

2、传统数据库
以 MySQL 为例,与 Elasticsearch 作对比
两者优势互补,不能替代
- 传统的数据库 MYSQL 使用**【正向索引】,主要依靠主键**来实现对数据的获取。
-
Elasticsearch使用**【倒排索引】**(“优先耗费时间建立新表,后续以空间换时间实现搜索”)。
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语(分词)。
- Elasticsearch中的词条是唯一的,后续搜索时会根据搜索关键词分词后的哈希运算值或者B+树实现查找。

-
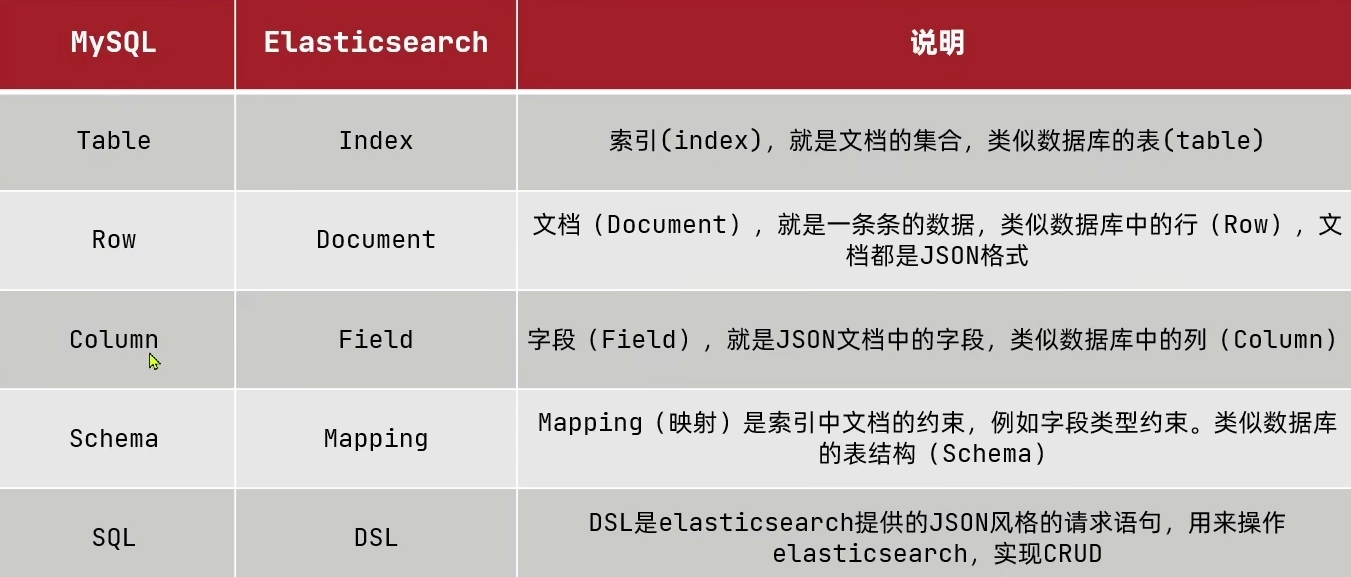
新老数据库概念对应关系
- 索引:即“表”,相同类型的文档集合
- 映射:即“约束”,索引中文档的字段约束信息,类似表的结构约束
- …

-
Elasticsearch查询语句为DSL语句(
JSON格式),使用HTTP发送请求。 -
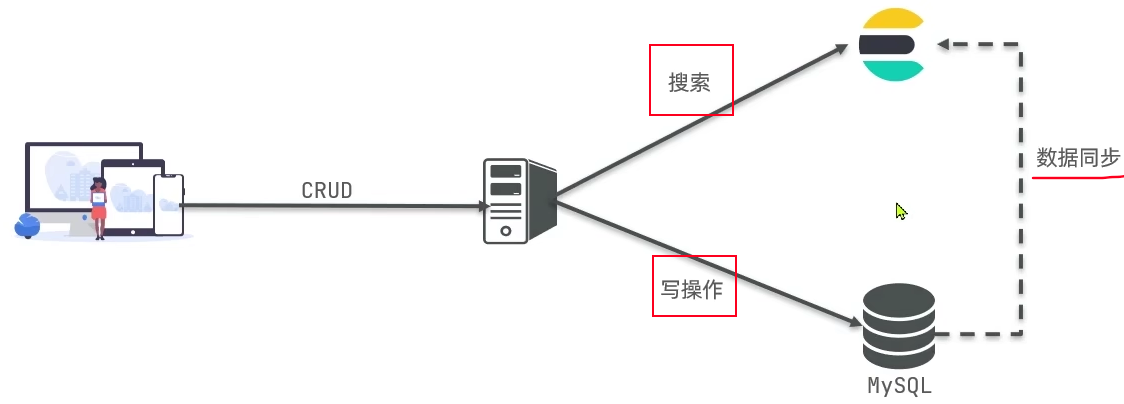
应用领域:
- MySQL(写):擅长事务性操作,可以确保数据达到安全和一致性。
- Elasticsearch(读):擅长海量数据的搜索、分析、计算。
3、安装
安装 Elasticsearch 与 Kibana(提供工具方便编写DSL语句)
两者安装包大小都在
1GB左右,且运行时所占内存也较大,推荐使用docker安装。
-
建立docker网络:Elasticsearch与Kibana必须处在同一个网络之中,并且此时两者可以通过docker服务名来建立连接。
docker network create es-net -
安装Elasticsearch
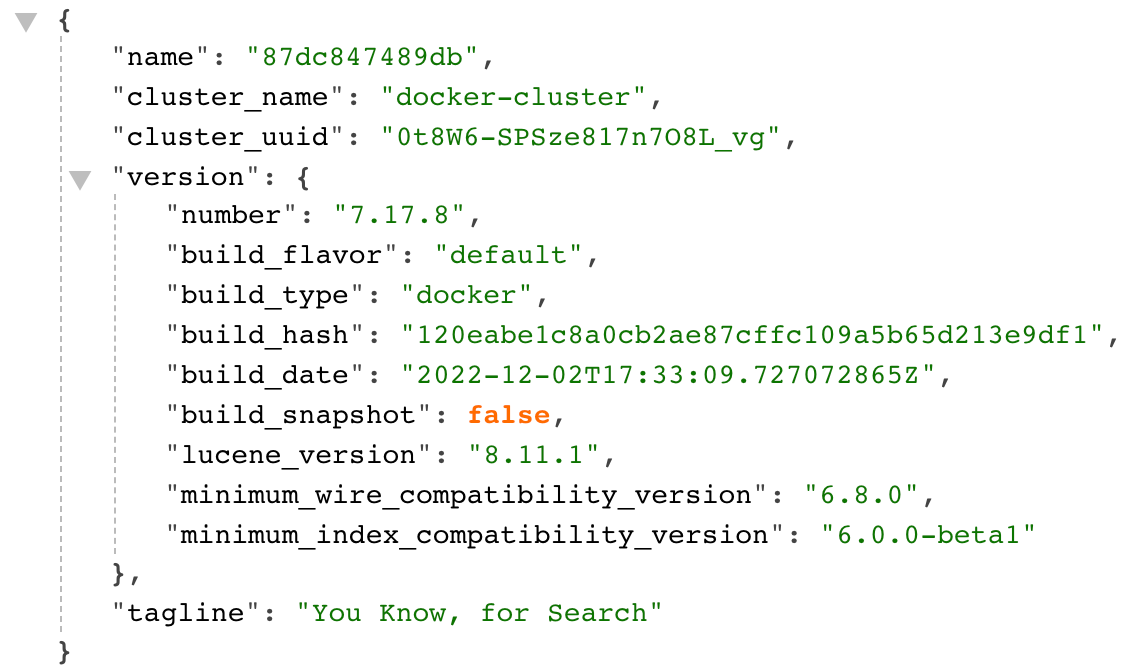
docker pull elasticsearch:7.17.7docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.17.7访问
http://ip:9200能看到下列信息说明部署成功。
当启动不成功时,查看日志排错
docker logs -f es
-
安装Kibana
docker pull kibana:7.17.7docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.17.7注意,Kibana启动较慢,可以使用
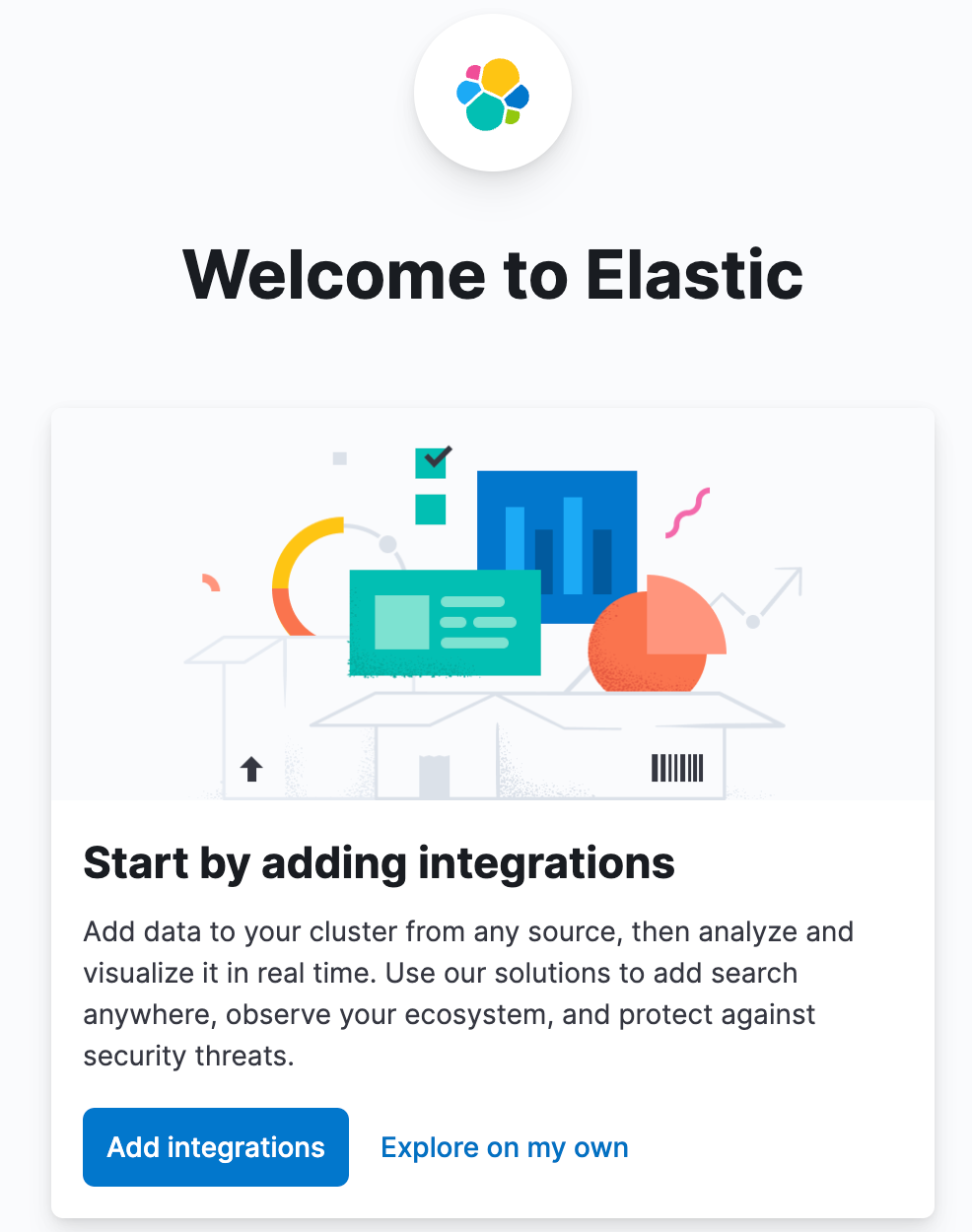
docker logs -f 服务名查看其日志。访问
http://ip:5601/当显示下列内容时表示成功。
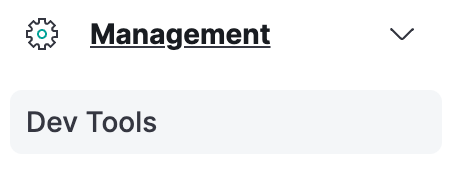
- 我们关注Kibana中的
左边菜单栏→Management→Dev Tools工具,后续用它来编写 DSL 操作。
4、IK分词器
Elasticsearch默认的分词器对中文分词兼容性极差,只能“按字依次分词”
IK分词器,专为Elasticsearch中文分词打造
-
离线安装(推荐):
- GitHub下载对应版本的 IK 分词器安装包,解压并重命名为
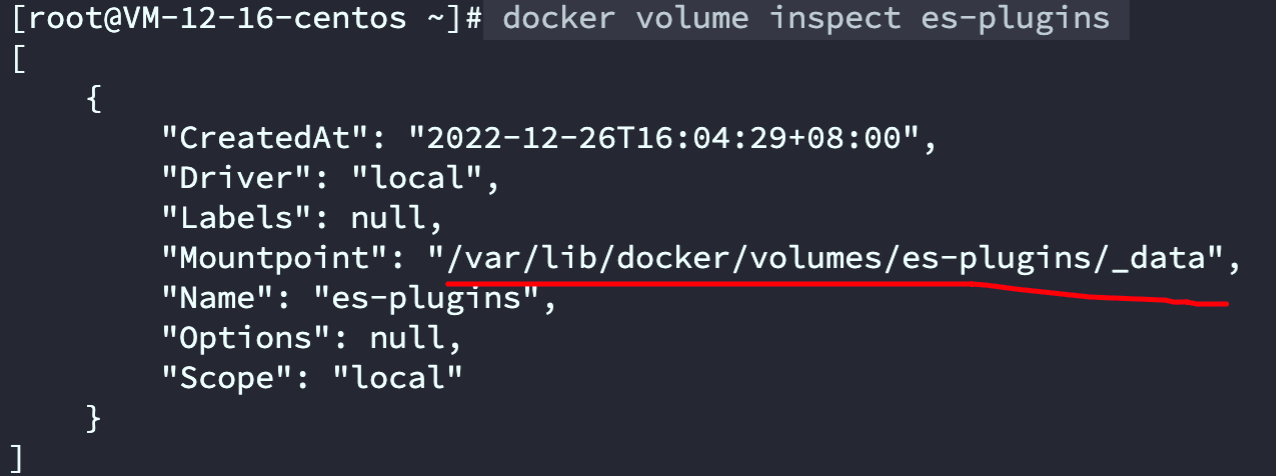
ik。 - 查看之前安装的 Elasticsearch 数据卷挂载位置,将解压后的
ik目录上传到该文件夹 - 重启Elasticsearch,查看日志确定重启成功
- Kibana
Dev Tools测试分词效果
docker volume inspect es-pluginsdocker restart es# 查看es日志 docker logs -f esPOST /_analyze { "text": "这是一段中文句子,请分词", "analyzer": "ik_smart" } - GitHub下载对应版本的 IK 分词器安装包,解压并重命名为
-
在线安装(服务器 GitHub 访问速度较慢,不推荐):
# 1、进入容器内部 docker exec -it elasticsearch /bin/bash # 2、在线下载并安装 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip # 3、退出 exit # 4、重启容器 docker restart elasticsearch -
IK分词器的 2 种模式
-
ik_smart:智能(最少)拆分 -
ik_max_word:重复(最细)切分
-
-
自定义字典(2种形式)
- 扩展词库:增加分词库词语。
- 停用词库:禁止对某些词语(敏感词)进行分词,直接忽略不显示。
要自定义词库,只需要到
ik/config/IKAnalyzer.cfg.xml中新增配置,并在配置文件的当前目录新建.dic字典,以行为分割属于相关词语,然后重启Elasticsearch容器即可(可以使用 Kibana 的Dev Tools进行测试)。<properties> <comment>IK Analyzer 扩展配置</comment> <!-- 扩展词库,myDict.dic 是文件名 --> <entry key="ext_dict">myDict.dic</entry> <!-- 停止词库,myStopwords.dic 是文件名 --> <entry key="ext_stopwords">myStopwords.dic</entry> </properties>

docker restart es
POST /_analyze
{
"text": "这是一段超长的词语,腾讯你好",
"analyzer": "ik_smart"
}

5、索引库创建
表,使用映射(约束)定义规则
-
Mapping映射规则:
- type:字段数据类型,常见的有:
- 字符串:text(可分词的文本)、keyword(不可分词的文本,例如品牌、国家名等)
- 数据:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- 地理坐标(经纬度):geo_point
- index:是否创建倒排索引,默认为
true(其实许多字段并不需要创建索引) - analyzer:使用哪种分词器
- properties:定义子字段
- type:字段数据类型,常见的有:
-
注意:索引库无数组概念,但允许某字段有多个值,例如下面的字段类型应为
integer。"score": [60,39,77,99] -
创建规则 以及 案例
PUT /索引库名称 { "mappings": { "properties": { "字段名1":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": false }, "字段名3":{ "properties": { "子字段名1":{ "type":"keyword" }, "子字段名2":{ "type":"keyword" }}}}}}PUT /mytable { "mappings": { "properties": { "info":{ "type": "text", "analyzer": "ik_smart" }, "email":{ "type": "keyword", "index": false }, "name":{ "properties": { "firstName":{ "type":"keyword" }, "LastName":{ "type":"keyword" }}}}}}

6、操作索引库
查询、删除、修改
-
首先声明:【索引库】和【Mapping】一旦创建就无法修改,但是可以(只能)添加新的字段,这是因为当索引库创建时 Elasticsearch 就会去创建倒排索引,如果允许修改索引库可能引起无法预知的错误,所以 Elasticsearch 在这点上比 MySQL 更加彻底,直接禁止修改。
-
查询:
GET /索引库名 -
删除
DELETE /索引库名 -
修改(新增)索引库
PUT /索引库名/_mapping { "properties":{ "新增的字段名":{ "type":"integer", "index":false } } }
7、文档操作
数据:新增、查询、删除、修改
-
新增文档:
文档id:类似 MySQL 主键,推荐手动添加(例如1),如果未添加则会自动生成较长的随机 id 代替POST /索引库名/_doc/文档id { "字段名1":{ "firstName":"张", "LastName":"三" }, "字段名2":18, "字段名3":"123@qq.com", "字段名4":"程序猿" }

-
查询
- 单条文档查询:
GET /索引库名/_doc/文档id- 全部查询
GET /索引库名/_search -
删除
DELETE /索引库名/_doc/文档id -
修改:修改文档这里有 2 种方式
- 全量修改:
PUT+_doc,先完全删除旧文档、然后用新文档替代。 - 增量修改:
POST+_update,在旧文档的基础上进行修改。
PUT 索引库名/_doc/文档id { "字段1":"值1", "字段2":"值2" }POST 索引库名/_update/文档id { "doc":{ "字段":"新的值" } } - 全量修改:
8、RestClient
Java 操作 Elasticsearch
-
简介:
ES官方提供了多种不同语言的客户端(包)用来操作ES。这些客户端的本质就是先组装DSL语句,然后通过 HTTP 请求发送给 ES。
-
建立索引库的【步骤】:
- 先建立相应 MySQL 数据库
- 对照 MySQL 数据库,编写索引库的创建语句(自己考虑逻辑、驼峰命名法)
- 在 Java 代码中使用 RestClient 借助 索引库编写语句创建索引库。
-
例如:
以下案例为 MySQL 建表语句,经过分析发现,发现酒店名称需要分词并建立索引,酒店品牌不需要分词但需要索引,酒店经纬度不需要建立索引,酒店价格、评分等需要建立索引以方便排序。
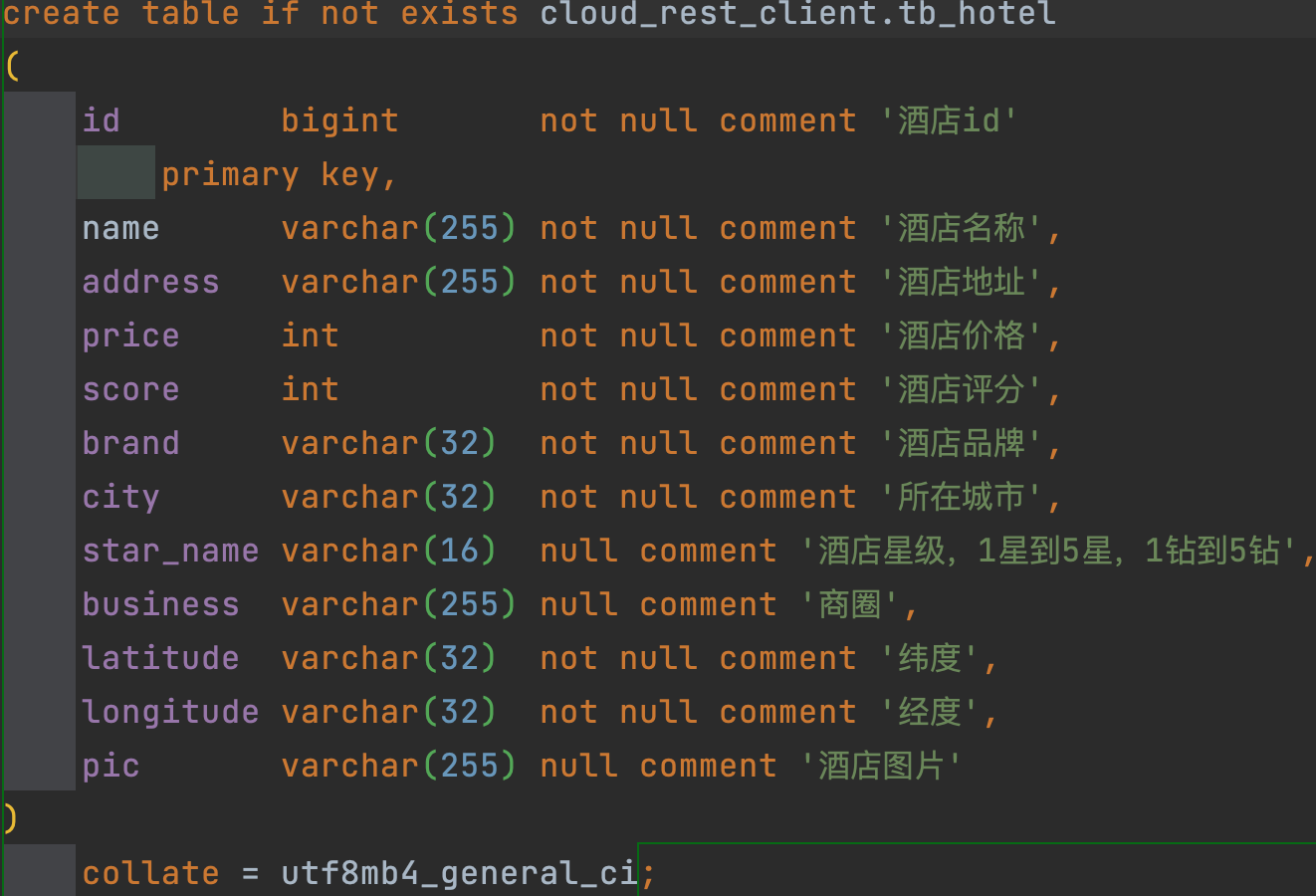
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address": {
"type": "keyword",
"index": false
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": {
"type": "keyword",
"copy_to": "all"
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": {
"type": "keyword",
"copy_to": "all"
},
"pic": {
"type": "keyword",
"index": false
},
"location": {
"type": "geo_point"
},
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
-
多字段搜索
字段拷贝:既想要实现多字段搜索,又想要效率最快
字段拷贝可以使用
copy_to属性将当前字段拷贝到指定字段,示例:"all": { "type": "text", "analyzer": "ik_max_word" } "brand":{ "type": "keyword", "copy_to":"all" } "name":{ "type": "keyword", "copy_to":"all" }all成功包含brand于name,以后搜索时只需要指定all即可。另外,虽然名叫“字段拷贝”,但是其实并不会真正的拷贝多份造成存储空间冗余。
-
初始化
Java RestClient- 引入 RestHighLevelClient 依赖
- 覆盖官方默认的 ES 版本(因为Spring Boot 会默认替我们导入某一版本的 ES 包,但这与我们的服务器软件版本可能不兼容,所以需要替换)
- 初始化 RestHighLevelClient

<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.17.7</elasticsearch.version>
</properties>
RestHighLevelClient client=new RestHighLevelClient(RestClient.builder(
HttpHost.create("175.178.20.191:9200")
));
或者将以上对象注册成Bean
@Configuration
public class CommonConfig {
@Bean
RestHighLevelClient rest() {
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("175.178.20.191:9200")
));
}
}
下面所有操作都是建立在初始化RestClient的基础上。
-
建立索引库
CreateIndexRequest request = new CreateIndexRequest("hotel"); request.source(MAPPING_TEMPLATE, XContentType.JSON); client.indices().create(request, RequestOptions.DEFAULT); -
删除索引库
DeleteIndexRequest request = new DeleteIndexRequest("hotel"); client.indices().delete(request, RequestOptions.DEFAULT); -
判断索引库是否存在
GetIndexRequest request= new GetIndexRequest("hotel"); Boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists); -
导入文档数据
- 单条导入:
IndexRequest - 批量导入:利用
Mybatis Plus + BulkRequest
// 注意在这可以赋予【id】 IndexRequest request = new IndexRequest("hotel").id("1"); // 利用 fastJSON 反序列化对象,生成 JSON 字符串 Hotel hotel = new Hotel(); hotel.setId(1L); hotel.setName("张三"); hotel.setAddress("北京"); request.source(JSON.toJSONString(hotel),XContentType.JSON); client.index(request,RequestOptions.DEFAULT);List<Hotel> list = hotelService.list(); BulkRequest bulkRequest = new BulkRequest(); for (Hotel hotel:list){ HotelDoc hotelDoc = new HotelDoc(hotel); bulkRequest.add(new IndexRequest("hotel") .id(hotelDoc.getId().toString()) .source(JSON.toJSONString(hotelDoc),XContentType.JSON)); } client.bulk(bulkRequest,RequestOptions.DEFAULT); - 单条导入:
-
获取文档数据
根据 id
GetRequest request = new GetRequest("hotel").id("1"); GetResponse getResponse = client.get(request, RequestOptions.DEFAULT); String json = getResponse.getSourceAsString(); System.out.println(json);此处为什么使用
getResponse.getSourceAsString()如此形式获取 JSON 字符串? 因为我们在调用
get()方法时,底层实际上使用的是GET /hotel/_doc/1,这种请求会返回一串json字符串,但是此时我们想要的数据却保存在_source结构体中。GET /hotel/_doc/1

-
更新文档数据
- 全量更新:方式跟前面的导入文档数据一模一样,即再次写入 id 相同的文档,新文档会完全覆盖旧文档。
- 局部更新:
UpdateRequest request = new UpdateRequest("hotel","1"); request.doc( "age","18", "name","李四" ); client.update(request,RequestOptions.DEFAULT); -
删除文档数据
// 10086 为文档id DeleteRequest request = new DeleteRequest("hotel","10086"); client.delete(request,RequestOptions.DEFAULT); -
文档操作总结:
- 初始化RestHighLevelClient
- 创建
__Request,即IndexRequest、BulkRequest、GetRequest、UpdateRequest、DeleteRequest - 准备参数(Index 和 Update 需要)
- 发送请求。调用
RestHighLevelClient.__()方法,即index()、bulk()、get()、update()、delete() - 解析结果(Get需要)
九、ES进阶
1、DSL查询
DSL 是基于 JSON 格式的查询方式
-
常见的查询方式
- 查询所有:查询所有数据,一般用于测试。
- match_all
- 全文检索:对用户输入的关键字进行分词,然后计算哈希值并根据倒排索引进行搜索。
- match:只能对单字段进行搜索
- mutil_match:多字段搜索
- 精确查询:根据精确词进行查询,一般查找的是 keyword 、数值、日期、Boolean 类型的数据。
- ids:
id s根据 id 进行查询 - range:范围
- term:精确查找
- ids:
- 地理查询:根据经纬度进行查询
- geo_distance
- geo_bounding_box
- 复合查询:组合查询查询方式
- bool:“与或非”形式的组合
- function_score:算分函数查询,可根据规则对文档相关性进行打分,控制文档的排名,常用于搜索引擎竞价。
- 查询所有:查询所有数据,一般用于测试。
-
【注意事项】
- 查询时 ES 默认只会返回命中的 10 条或 20 条数据,并不会一下子都将命中数据返回(自动分页节省资源)。
- 查询结果会按照“优先级”进行自动排序,相关度越高的结果排名越靠前。
-
查询的基本语法
GET /索引名称/_search { "query": { "查询类型": { "查询条件":"条件值" } } } -
查询所有:match_all
GET /hotel/_search { "query": { "match_all": {} } }

-
全文检索
以下两种方式查询结果一样。在前面时,我们定义 all 字段为拷贝字段,这里虽然两种方式的查询结果一样,但是推荐使用拷贝字段all,因为效率高;而在另一种查询方式中,联合查询的字段越多,性能越低。
常用于“搜索框”搜索
GET /hotel/_search { "query": { "match": { "all": "外滩如家" } } }GET /hotel/_search { "query": { "multi_match": { "query": "外滩如家", "fields": ["brand","name","business"] } } } -
精确查询
关键字不会分词,查询出来的结果也要与关键字完全匹配
- term:精确查询
city=="上海"
GET /hotel/_search { "query": { "term": { "city": { "value": "上海" } } } }- range:查询范围
GET /hotel/_search { "query": { "range": { "price": { "gte": 100, "lte": 2000 } } } } - term:精确查询
-
地理查询
可用作“打车”、“附近的人”等功能
geo_bounding_box:画矩形。查询值落在矩形内的所有文档。get_distance:画圆形。以点开始作半径查询,查询距离你多少米的人。常用于“附近的人”。
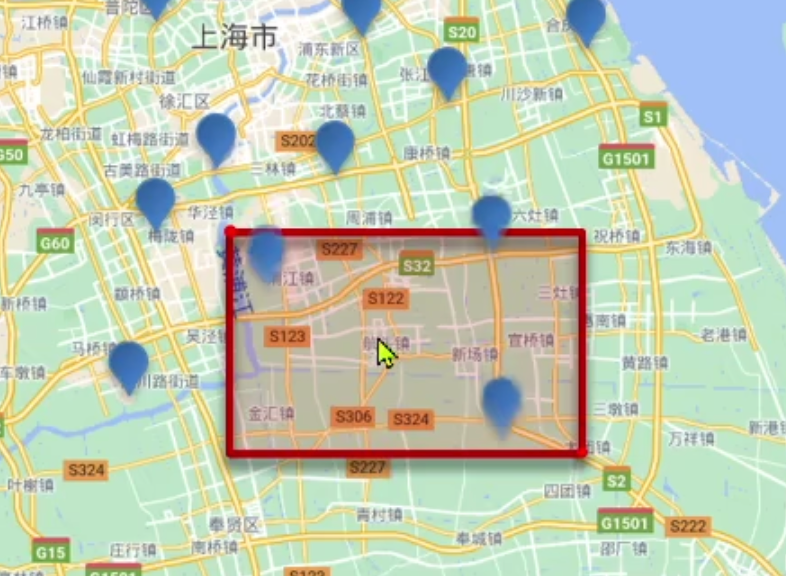
GET /hotel/_search
{
"query": {
"geo_bounding_box":{
"location":{
"top_left":{
"lat":31.1,
"lon":121.5
},
"bottom_right":{
"lat":30.9,
"lon":121.7
}
}
}
}
}
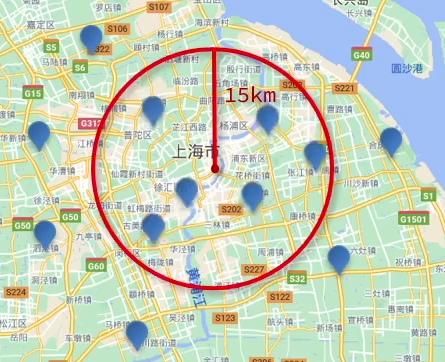
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance":"15km",
"location":"31.21,121.5"
}
}
}
-
复合查询
_socre字段表示得分- Function Score Query:算分函数查询,通过指定算法更改查询的相关度得分,常用于竞价排名。
原始查询条件、过滤条件、算分函数、加权模式
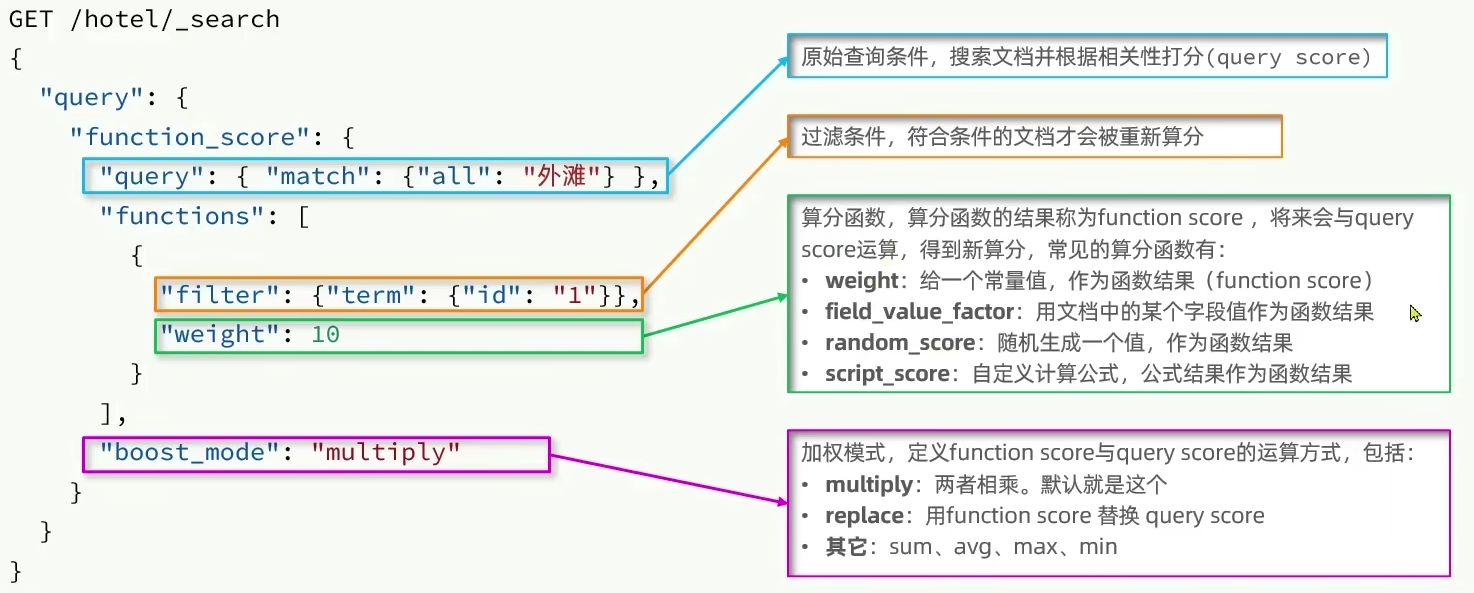

- Boolean Query:子查询组装,一个或多个查询子句的集合。具体的组合方式有
- must:【与】,必须匹配每个子查询,参与算分。
- should:【或】,只要匹配一个子查询就可以,参与算分。
- must_not:【非】,不匹配任何一个子查询,并且不参与算分。
- filter:必须匹配,单步不参与算分。(filter与must的区别只在于是否参与算分,不参与性能会更高)


2、搜索结果处理
排序、分页、高亮
一、排序
-
简介:
- Elasticsearch支持对搜索结果进行排序,默认根据相关度算分
_score进行排序,可以排序的字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。 - 与MySQL中的
order by思想一致。 - 当使用排序功能时,
_score就显得无意义,因此此时无得分,score始终为0。
- Elasticsearch支持对搜索结果进行排序,默认根据相关度算分
-
简单案例:
sort声明GET /hotel/_search { "query": { "match_all": {} }, // sort与query同级且为数组形式,意味着可以有多种排序定义 "sort": [ { "price": { "order": "desc" // 排序字段和排序方式,AES与DESC } } ] }简写版本
"sort": [ { "price": "desc" } ] -
地理位置排序:距离案例,结果单位为
km(有点智能)"sort": [ { "_geo_distance": { "location": { "lat": "18.57", "lon": "109.70" }, "order": "asc", "unit": "km" } } ]

二、分页
-
简介:使用
from与size标签。 -
案例
GET /hotel/_search { "query": { "match_all": {} }, "from": 100, "size": 20 } -
注意事项:【深度分页】限制
from与size标签相加不能大于10000,否则报错。这是由于Elasticsearch使用倒排索引所产生的限制(倒排索引本身并不适合分页),一般也不会超过10000,但是如果有需求,官方也推荐了两种解决方式如下:after search:- 记住上次翻页的位置,下次分页从上次的地方开始。
- 缺点:只能向后查询,不支持随机翻页。
scroll:- 预先缓存分页信息
- 已废弃,当数据改变时会重新缓存,不仅性能差劲,而且会导致数据的实时性缺失。
三、高亮
- 简介:在搜索结果中把搜索关键词突出显示。
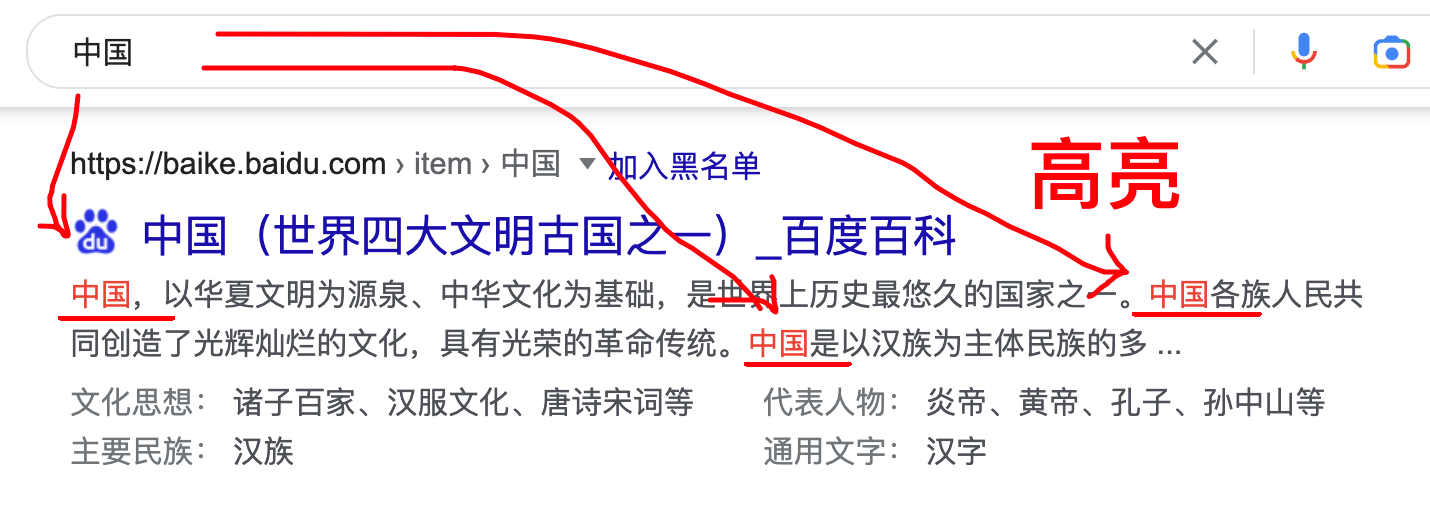
-
原理简介:
- 将搜索结果中的关键字用“标签”标记,例如
<em></em> - 在页面中添加 CSS 样式
- 将搜索结果中的关键字用“标签”标记,例如
-
注意:
- Elasticsearch内置默认高亮样式即为
<em></em> - 查询方式必须为
match而不能为match_all,因为后一种方式并无关键字!
- Elasticsearch内置默认高亮样式即为
-
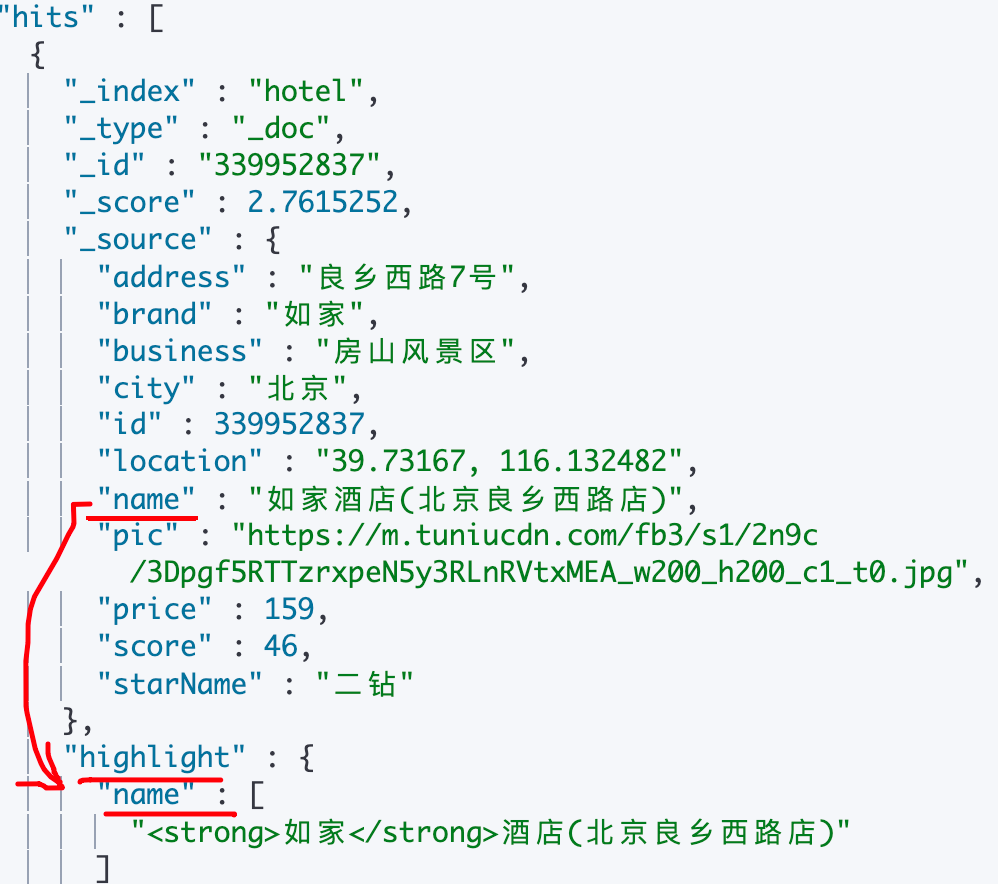
简单实现
GET /hotel/_search { "query": { "match": { "all": "如家" } }, "highlight": { "fields": { "name": { // ES默认搜索字段应该与搜索字段一致,如果不一致需要将:require_field_match=false // 这里查询字段为:all,高亮字段为:name "require_field_match": "false", "pre_tags": "<strong>", "post_tags": "</strong>" } } } }搜索结果展现形式:新增
highlight字段,高亮后的字段将放在里面,_source中的原内容并不会被改变,这点需十分注意!
3、RestClient
此处 ES 将 API 封装的比较完善,(不同于前面)无需硬编码。
一、查询
-
基本查询步骤:
- 创建
SearchRuquest对象 - 准备
Request.source().___query(),塞入QueryBuilder构建查询条件。 - 发送请求,得到结果
- 解析结果(从外到内,逐层解析 JSON 格式数据)
- 创建
-
注意:
- 支持链式编程
- 所有操作都基于
Request.source()API接口,掌握了该接口就掌握了本节
-
简单实现:
matchAllQuery()SearchRequest request = new SearchRequest("hotel"); // .QueryBuilder中包含绝大多数查询方式 request.source().query( QueryBuilders.matchAllQuery() ); // 发送请求,得到响应数据,获取响应数据(JSON)并解析 SearchResponse response = client.search(request, RequestOptions.DEFAULT); SearchHits hits = response.getHits(); System.out.println("查询到的文档数:"+hits.getTotalHits().value); // 遍历查询到的数据(有分页,默认10条) for (SearchHit hit:hits.getHits()){ String json = hit.getSourceAsString(); System.out.println(json); } -
【结果解析】示例图

-
单字段查询
QueryBuilders.matchQuery("all","如家") -
多字段查询
QueryBuilders.multiMatchQuery("如家","name","brand") -
精确查询
- 词条查询term
QueryBuilders.termQuery("brand","如家")- 范围查询
QueryBuilders.rangeQuery("price").gt(100).lte(1000) -
复合查询
较复杂
// 建立复合查询“构建器” BoolQueryBuilder boolQuery = new BoolQueryBuilder(); // request组装复合查询 boolQuery.must(QueryBuilders.termQuery("brand","如家")); boolQuery.filter(QueryBuilders.rangeQuery("price").gt(100)); request.source().query(boolQuery); // 同以往:发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); -
QueryBuilders选项一览(还有更多没有展示出来)
二、排序
-
普通排序
request.source().sort("price",SortOrder.ASC); -
距离排序


三、分页与高亮
-
分页
request.source() .query(QueryBuilders.matchAllQuery()) .from(56) .size(20); -
高亮
request.source() .query(QueryBuilders.matchQuery("all", "如家")) // requireFieldMatch 表示是否与查询字段匹配 .highlighter(new HighlightBuilder().field("name").requireFieldMatch(false)); -
【高亮结果】解析
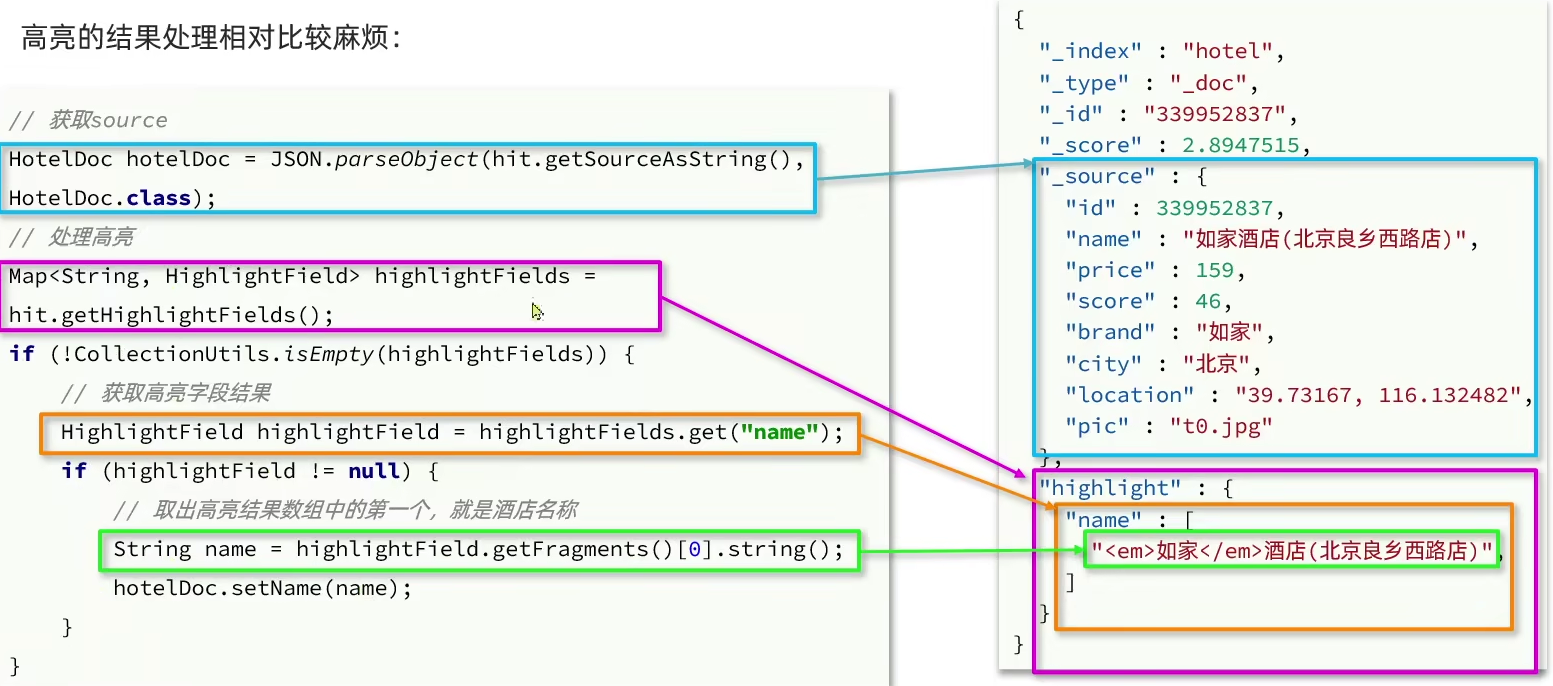
四、Function score

五、旅游网站案例
搜索、分页、条件过滤、附近、广告置顶
-
示意图
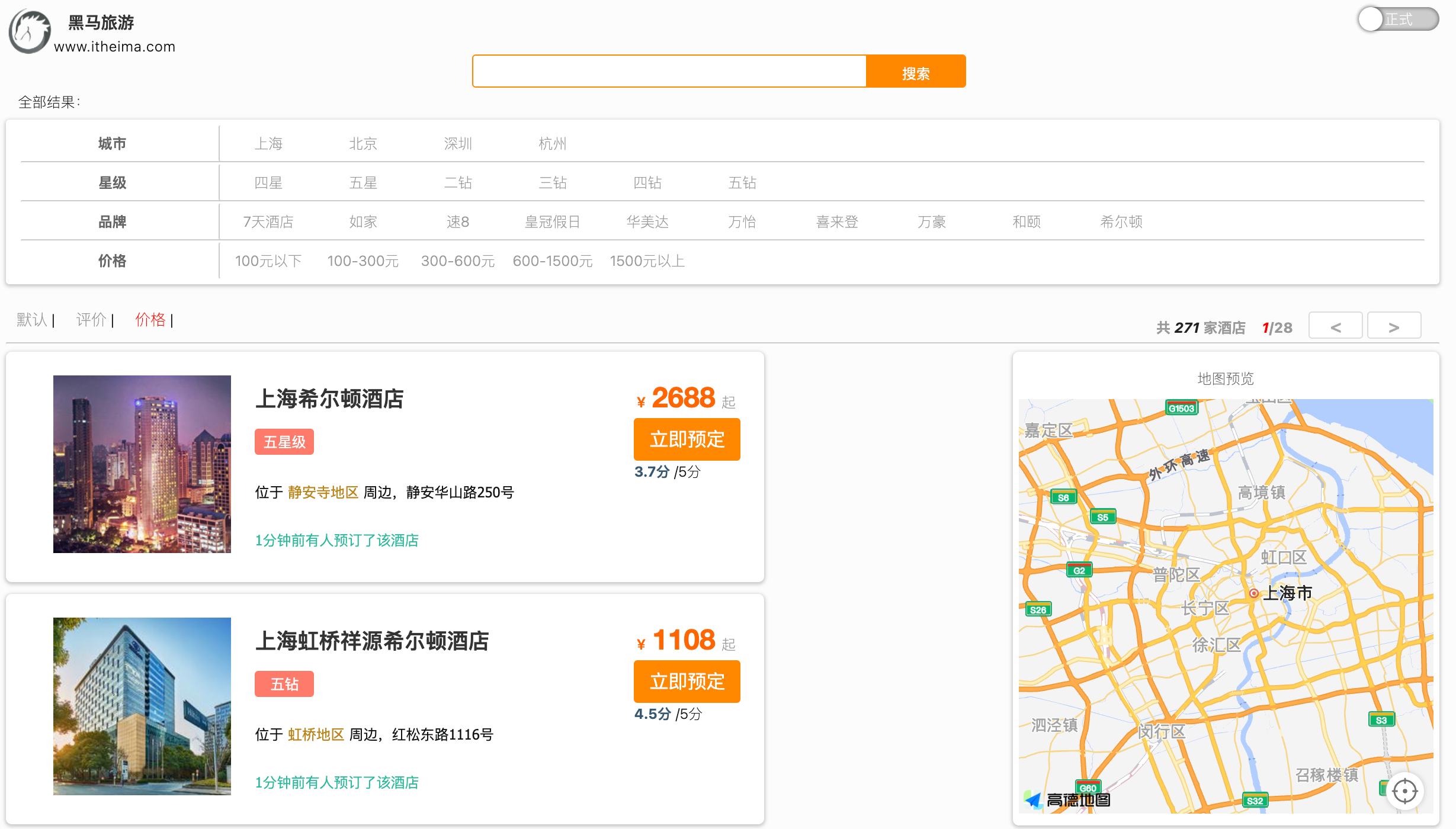
-
搜索框功能实现(核心代码)
-
终极案例
除 附近功能 之外均实现。
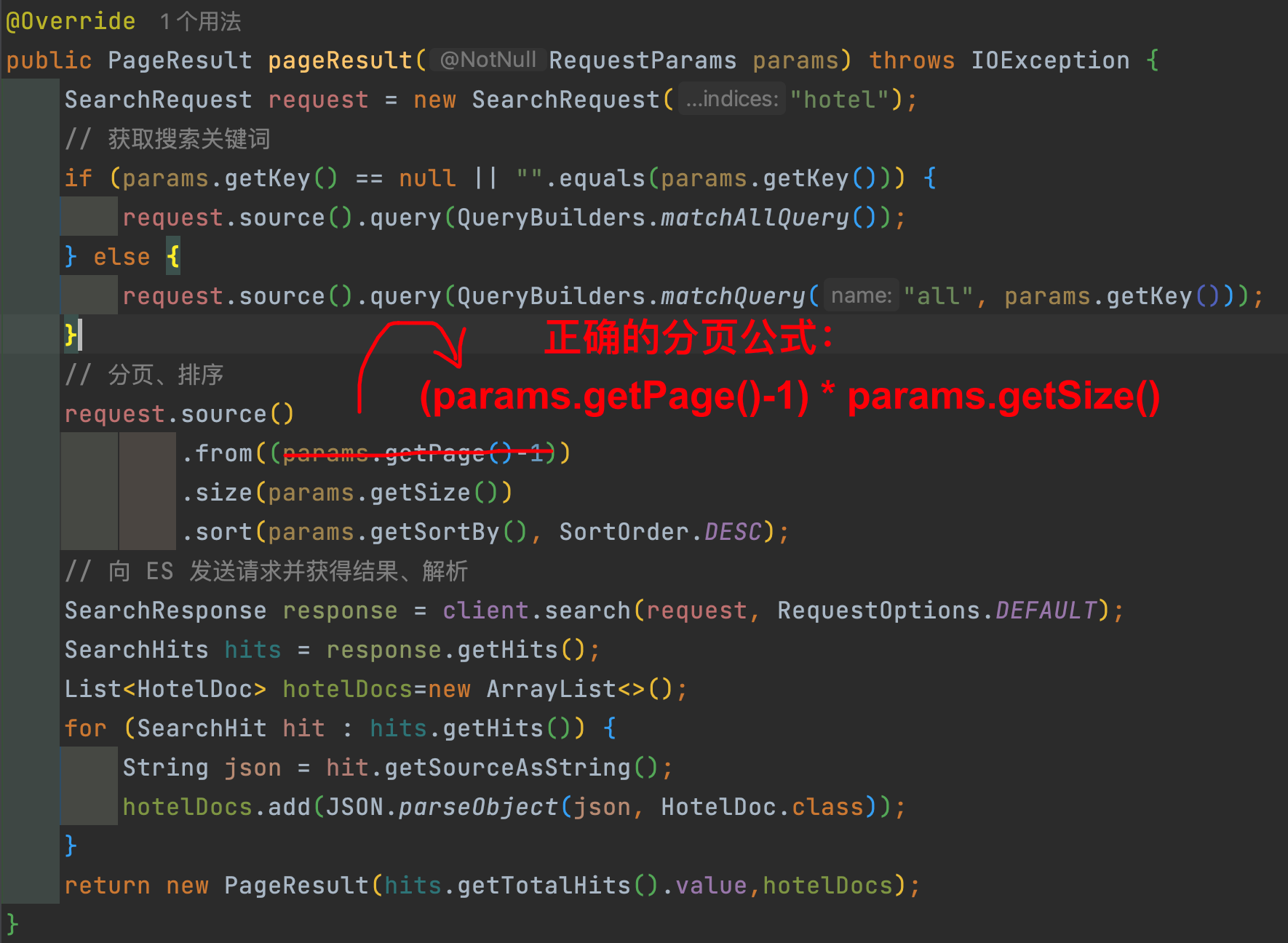
@Override public PageResult pageResult(RequestParams params) throws IOException { SearchRequest request = new SearchRequest("hotel"); BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); // 获取搜索关键词 if (params.getKey() == null || "".equals(params.getKey())) { boolQuery.must(QueryBuilders.matchAllQuery()); } else { boolQuery.must(QueryBuilders.matchQuery("all", params.getKey())); } String brand = params.getBrand(); if (StringUtils.isNotBlank(brand)) { boolQuery.filter(QueryBuilders.termQuery("brand", brand)); } // 1.3.城市 String city = params.getCity(); if (StringUtils.isNotBlank(city)) { boolQuery.filter(QueryBuilders.termQuery("city", city)); } // 1.4.星级 String starName = params.getStarName(); if (StringUtils.isNotBlank(starName)) { boolQuery.filter(QueryBuilders.termQuery("starName", starName)); } // 1.5.价格范围 Integer minPrice = params.getMinPrice(); Integer maxPrice = params.getMaxPrice(); if (minPrice != null && maxPrice != null) { maxPrice = maxPrice == 0 ? Integer.MAX_VALUE : maxPrice; boolQuery.filter(QueryBuilders.rangeQuery("price").gte(minPrice).lte(maxPrice)); } // 2.算分函数查询 FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery( boolQuery, // 原始查询,boolQuery new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{ // function数组 new FunctionScoreQueryBuilder.FilterFunctionBuilder( QueryBuilders.termQuery("isAD", true), // 过滤条件 ScoreFunctionBuilders.weightFactorFunction(100) // 算分函数 ) } ); // 设置查询条件 request.source() .query(functionScoreQuery) .from((params.getPage() - 1) * params.getSize()) .size(params.getSize()); // 向 ES 发送请求并获得结果、解析 SearchResponse response = client.search(request, RequestOptions.DEFAULT); SearchHits hits = response.getHits(); List<HotelDoc> hotelDocs = new ArrayList<>(); for (SearchHit hit : hits.getHits()) { String json = hit.getSourceAsString(); hotelDocs.add(JSON.parseObject(json, HotelDoc.class)); } return new PageResult(hits.getTotalHits().value, hotelDocs); }
十、ES高阶
数据聚合、自动补全、同步、集群
1、数据聚合
aggregations,聚合
一、DSL
-
简介:聚合可以实现对文档数据的统计、分析、运算,常见的 3 种类型为
- 桶聚合(Bucket):用来对文档分组
- Term Aggregation:精确匹配,按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周分为一组
- 度量聚合(Metric):用来计算值
- Avg:平均值
- Max:最大值
- Min:最小值
- Stats:同时求 max、min、avg、sum 等
- 管道聚合(pipeline):类似Linux中的管道,使用其他聚合的结果作为输入,再次进行聚合
- 桶聚合(Bucket):用来对文档分组
-
==【注意】==参与聚合的字段类型必须为:
- keyword
- 数值
- 日期
- 布尔
-
聚合必备的【三要素】
- 聚合名称
- 聚合类型
- 聚合字段
-
聚合可配置的属性
- size:指定聚合结果的数量(即分页)
- order:聚合结果的排序方式
- field:指定聚合字段
-
桶聚合Bucket案例
附加对统计结果
_count进行排序GET /hotel/_search { "size": 0, // 令文档查询数为0,避免干扰 "aggs": { // 定义聚合 "myAggs": { // 给聚合起个名字 "terms": { // 聚合的类型 "field": "brand", // 对“brand”字段进行聚合,这里选择精确查询 term 模式 "size": 20, // 聚合的结果也会进行分页,这里为20 "order": { // 对聚合结果根据 _count 进行排序 "_count": "desc" } } } } }

-
度量聚合Metric案例
GET /hotel/_search { "size": 0, "aggs": { "myAggs": { "terms": { "field": "brand", "size": 20, "order": { "_count": "desc" } }, // 【桶聚合】内套【度量聚合】,score字段为文档自带,这里对其求 stats 操作 "aggs": { "myScoreAggs": { "stats": { "field": "score" } } } } } }

-
【重要】:
默认情况下,Bucket聚合将会对索引库中的所有文档做聚合,当索引库很大时这无疑会很消耗性能,我们可以通过添加query条件限制要聚合的文档范围。
即先 query 后 bucket,先查询再聚合。
GET /hotel/_search { "query": { "range": { "price": { "lte": 300 // 只对 300 元以下的酒店作聚合 } } }, "size": 0, "aggs": { "myAggs": { "terms": { "field": "brand", "size": 20, } } } }
二、RestClient
-
标准实现流程:
-
准备 Request
-
准备 DSL
-
设置 Size==0
-
聚合语句
-
-
发出请求
-
解析结果
- 根据聚合名称获取聚合结果
- 获取 Buckets
- 遍历
-
-
聚合代码映射:依次对照
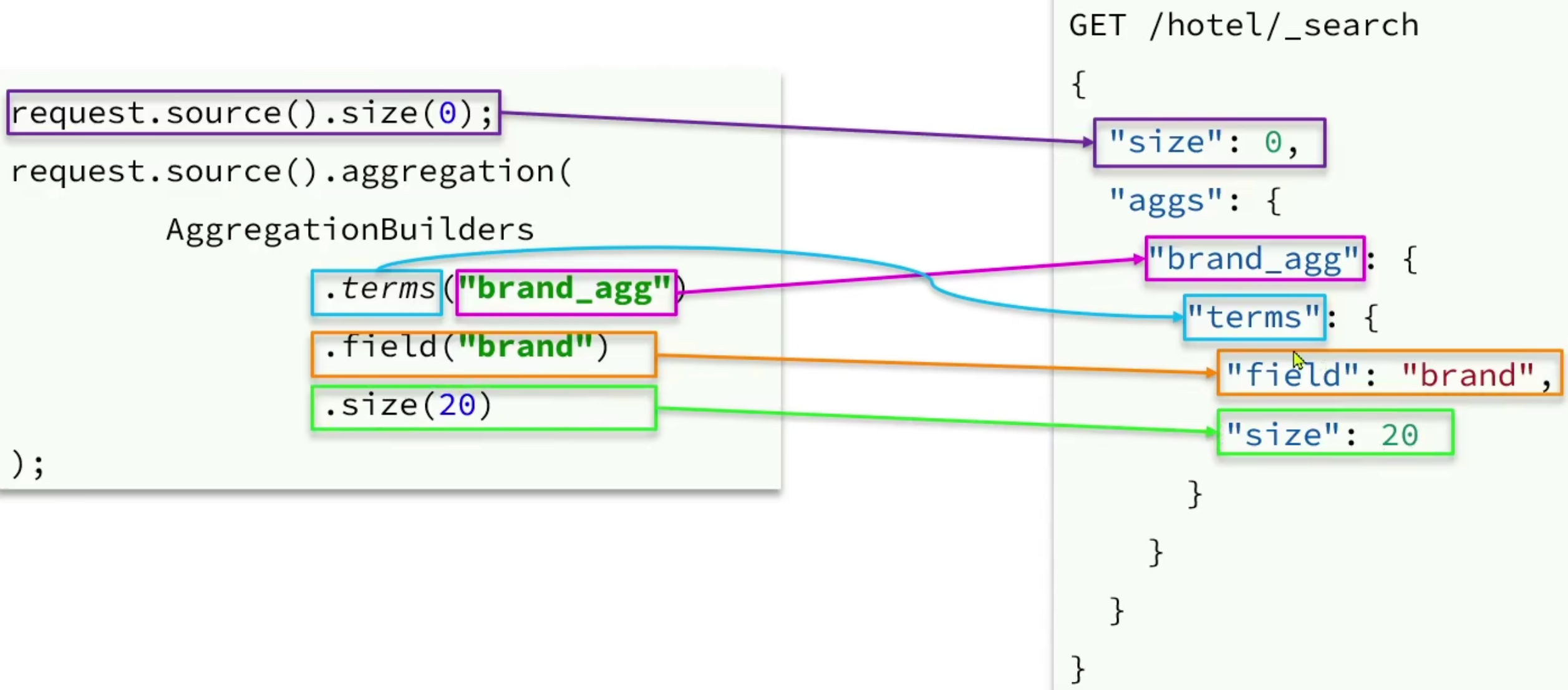
-
结果解析:获取 Buckets 数据

2、自动补全
一、基础
-
安装拼音分词器
pinyin(步骤与 IK 分词器一致)- GitHub下载并解压(注意对应版本)
- 将解压后的文件重命名为
py后上传至 ES 的plugin 目录 - 重启ES并测试
docker restart es
POST /_analyze
{
"text": "这是一段超长的词语,腾讯你好",
"analyzer": "pinyin"
}

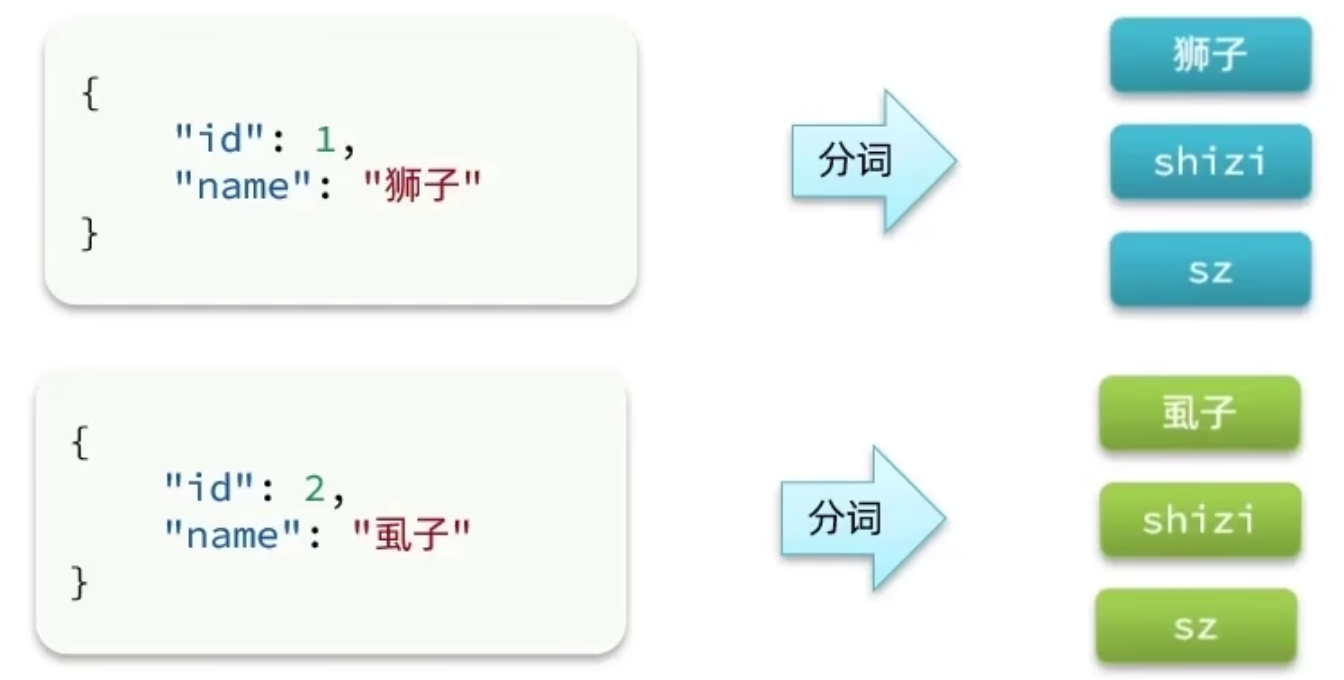
pinyin分词器分词说明:
-
ES分词器组成说明(3部分)
- character filters:在 tokenizer 之前对文本进行处理,例如字符替换、字符删除等。
- tokenizer:将文本安装一定的规则切割成词条(term),例如 keyword 不分词、ik_smart分词
- tokenizer filter:将 tokenizer 输出的词条进一步处理,例如大小写转换、同义词处理、拼音处理等

-
如何自定义分词器?
在创建索引库时,于 settings 中声明(同时可指定 character filters、tokenizer、tokenizer filter)。
**自定义分词器有什么用?**首先软件中可引入多种开源分词器,我想组合这些分词器(例如:分别在 3 各不同阶段使用不同分词器)以达到最佳效果。意即如果我自定义分词器,直接使用开源分词器也是可以的,只不过在这里我想自定义。
PUT /test { "settings": { "analysis": { "analyzer": { // 自定义分词器 "my_analyzer":{ // 分词器名称 "tokenizer":"ik_max_word", // 2 使用 ik_max_word "filter":"py" // 3 使用使用 py ( py 在下面定义) } }, "filter": { // 自定义 tokenizer filter 过滤器 "py": { // 过滤器名称,下面为属性,具体参考 pinyin 官网文档 "type": "pinyin", "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, // 字段定义,即“建表语句” "mappings": { "properties": { "name":{ "type": "text", "analyzer": "my_analyzer", // 插入数据时,使用【自定义分词器】,即 pinyin +ik "search_analyzer": "ik_smart" // 搜索时不应该使用 pinyin ,只需单独使用 ik } } } }插入数据并测试
POST /test/_doc/1 { "id": 1, "name": "狮子" } POST /test/_doc/2 { "id": 2, "name": "虱子" } // 查询 1 GET /test/_search { "query": { "match": { "name": "狮子" } } } // 查询 2 GET /test/_search { "query": { "match": { "name": "shizi" } } } -
使用【拼音分词器】时应该注意的问题:
为避免搜索到多音字情况,我们应该采取 2 套策略:
- 存入数据时使用:pinyin分词器 + ik分词器
- 搜索时:只用 ik 分词器
二、RestClient
-
建立酒店索引库(新增自动补全字段 suggestion )
DELETE /hotel // 酒店数据索引库 PUT /hotel { "settings": { "analysis": { "analyzer": { // 全文检索 "text_anlyzer": { "tokenizer": "ik_max_word", "filter": "py" }, // 自动补全 "completion_analyzer": { "tokenizer": "keyword", "filter": "py" } }, "filter": { "py": { "type": "pinyin", "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "id":{ "type": "keyword" }, "name":{ "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart", "copy_to": "all" }, "address":{ "type": "keyword", "index": false }, "price":{ "type": "integer" }, "score":{ "type": "integer" }, "brand":{ "type": "keyword", "copy_to": "all" }, "city":{ "type": "keyword" }, "starName":{ "type": "keyword" }, "business":{ "type": "keyword", "copy_to": "all" }, "location":{ "type": "geo_point" }, "pic":{ "type": "keyword", "index": false }, "all":{ "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart" }, "suggestion":{ "type": "completion", "analyzer": "completion_analyzer" } } } } -
更改
HotelDoc.java:新增suggestion字段,类型为List<String>@Data @NoArgsConstructor @AllArgsConstructor public class HotelDoc { private Long id; private String name; private String address; private Integer price; private Integer score; private String brand; private String city; private String starName; private String business; private String location; private String pic; private Boolean isAD; private List<String> suggestion; public HotelDoc(Hotel hotel) { this.id = hotel.getId(); this.name = hotel.getName(); this.address = hotel.getAddress(); this.price = hotel.getPrice(); this.score = hotel.getScore(); this.brand = hotel.getBrand(); this.city = hotel.getCity(); this.starName = hotel.getStarName(); this.business = hotel.getBusiness(); this.location = hotel.getLatitude() + ", " + hotel.getLongitude(); this.pic = hotel.getPic(); this.suggestion = Arrays.asList(this.brand, this.business); } } -
导入数据
@Test void importData() throws IOException { List<Hotel> list = hotelService.list(); BulkRequest bulkRequest = new BulkRequest(); for (Hotel hotel:list){ HotelDoc hotelDoc = new HotelDoc(hotel); bulkRequest.add(new IndexRequest("hotel") .id(hotelDoc.getId().toString()) .source(JSON.toJSONString(hotelDoc),XContentType.JSON)); } client.bulk(bulkRequest,RequestOptions.DEFAULT); } -
DSL测试自动补全功能
GET /hotel/_search { "suggest": { "suggestions": { // 关键词 "text": "sd", "completion": { "field": "suggestion", // 跳过重复字符 "skip_duplicates":true, "size":10 } } } } -
准备请求,解析结果


SearchRequest request = new SearchRequest("hotel"); request.source().suggest(new SuggestBuilder().addSuggestion( "mySuggestion", SuggestBuilders .completionSuggestion("suggestion") // 字段名 .prefix("sd") .skipDuplicates(true) .size(10) )); // 发送请求,获得结果并解析 SearchResponse response = client.search(request, RequestOptions.DEFAULT); CompletionSuggestion suggestion = response.getSuggest().getSuggestion("mySuggestion"); for ( CompletionSuggestion.Entry.Option option:suggestion.getOptions()){ String text = option.getText().string(); System.out.println(text); }
三、前后端结合案例
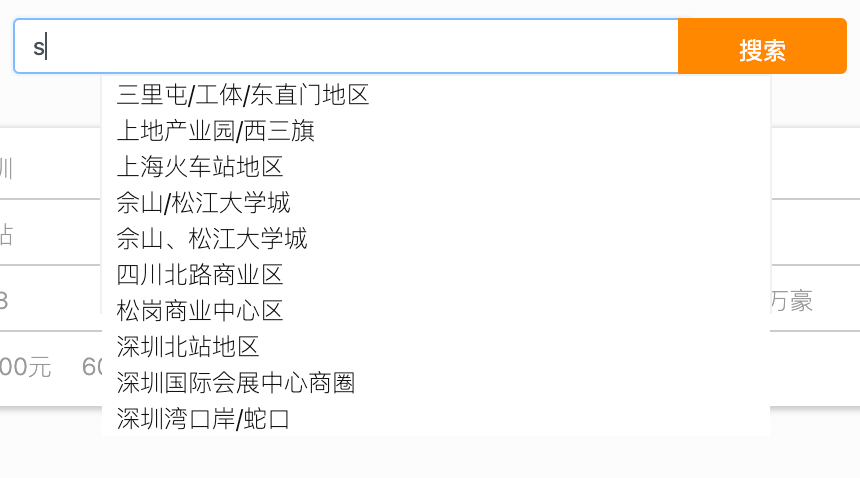

@GetMapping("suggestion")
List<String> suggestion(@RequestParam("key") String prefix) throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"mySuggestion",
SuggestBuilders
.completionSuggestion("suggestion") // 字段名
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
CompletionSuggestion suggestion = response.getSuggest().getSuggestion("mySuggestion");
List<String > suggestions=new ArrayList<>();
for ( CompletionSuggestion.Entry.Option option:suggestion.getOptions()){
String text = option.getText().string();
suggestions.add(text);
}
System.out.println(suggestions.size());
return suggestions;
}
3、数据同步
ES 的数据来源于 MySQL ,当 MySQL 数据发生改变时,ES也要跟着变化
一、简介
-
情境:ES 和 MySQL 分别来自不同的微服务。
-
3 种不同方案的同步方式:
- 同步调用:
- 优点:实现简单
- 缺点:业务耦合度高
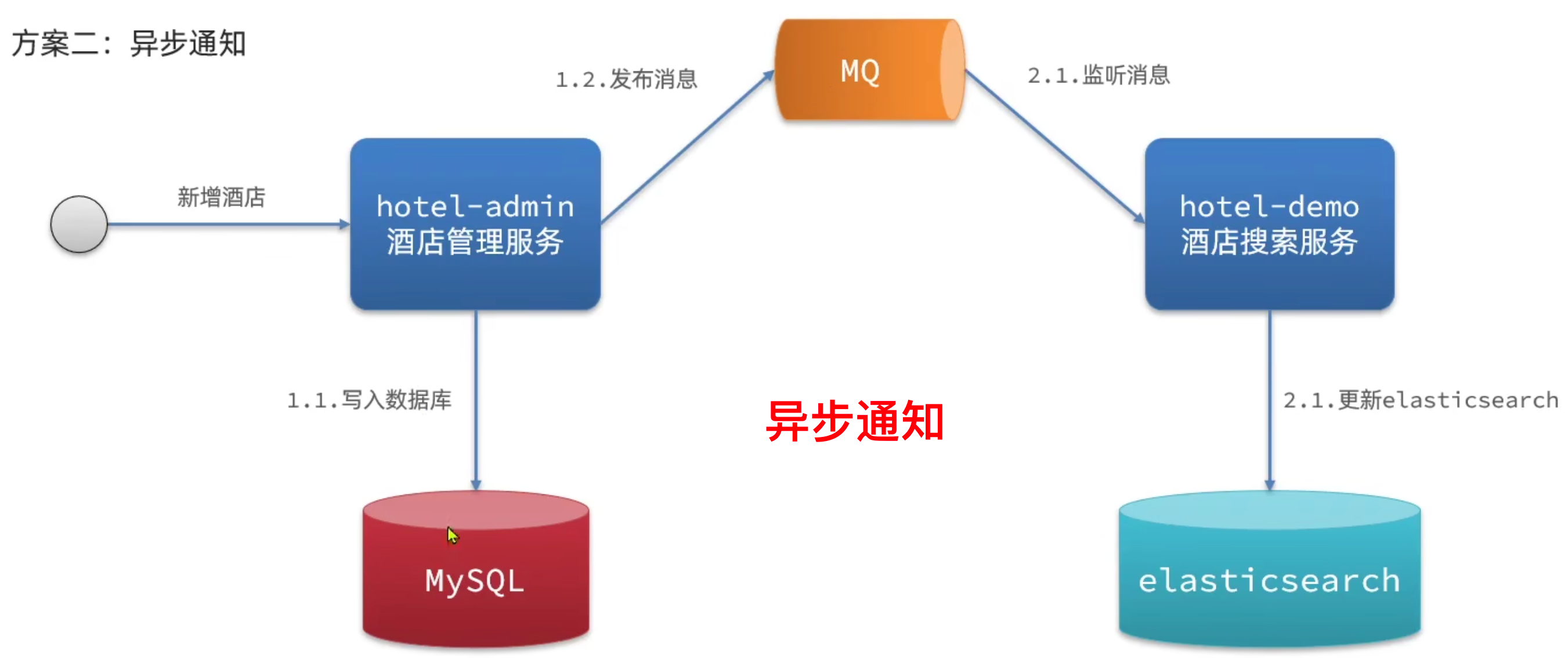
- 异步通知(主选)
- 优点:低耦合、实践难度一般
- 缺点:依赖 MQ 的可靠性,时间复杂度较另外两者高
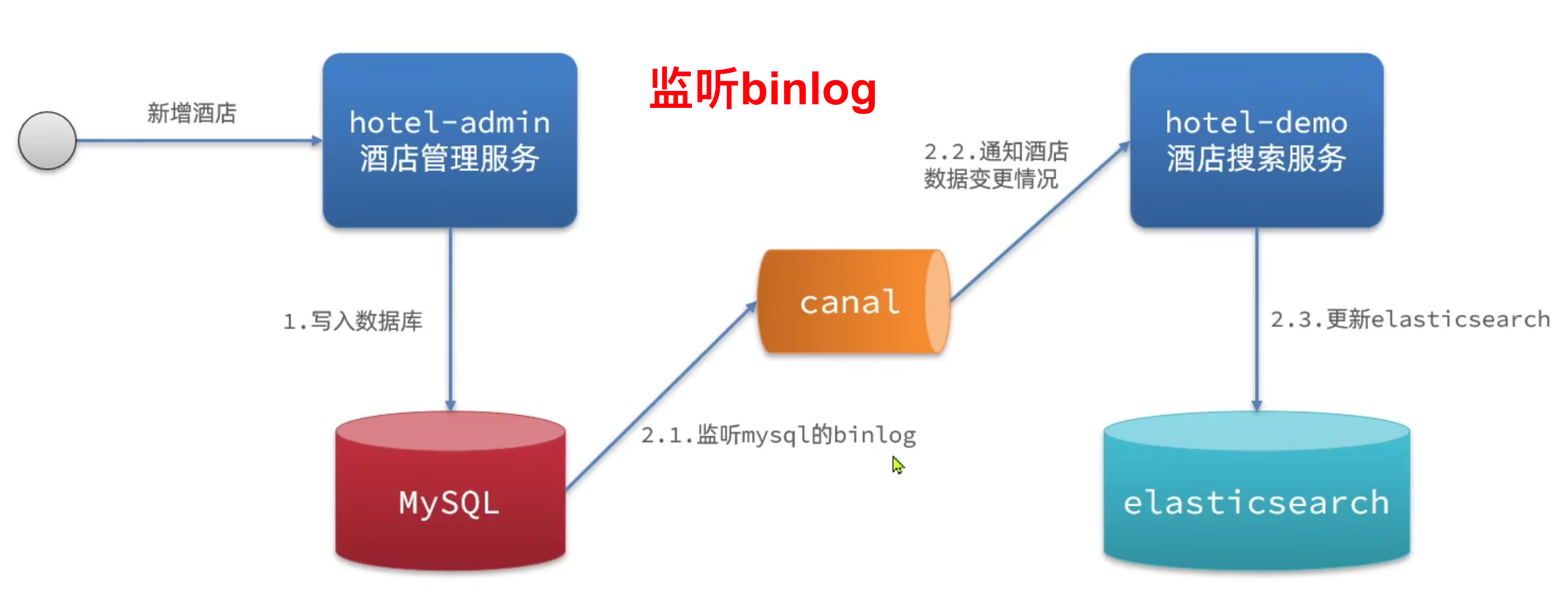
- 监听binlog
- 优点:完全解除服务间耦合
- 缺点:增加 MySQL 数据库负担,实现复杂度高

- 同步调用:
二、RestClient
实现的简单步骤流程,具体步骤请点击
准备 2 个项目
- 一:包含MySQL,只负责数据的增删改
- 二:包含 ES,只负责数据的查
4、ES集群部署
暂时跳过,待到后面有机会应用时自然会访问此章节
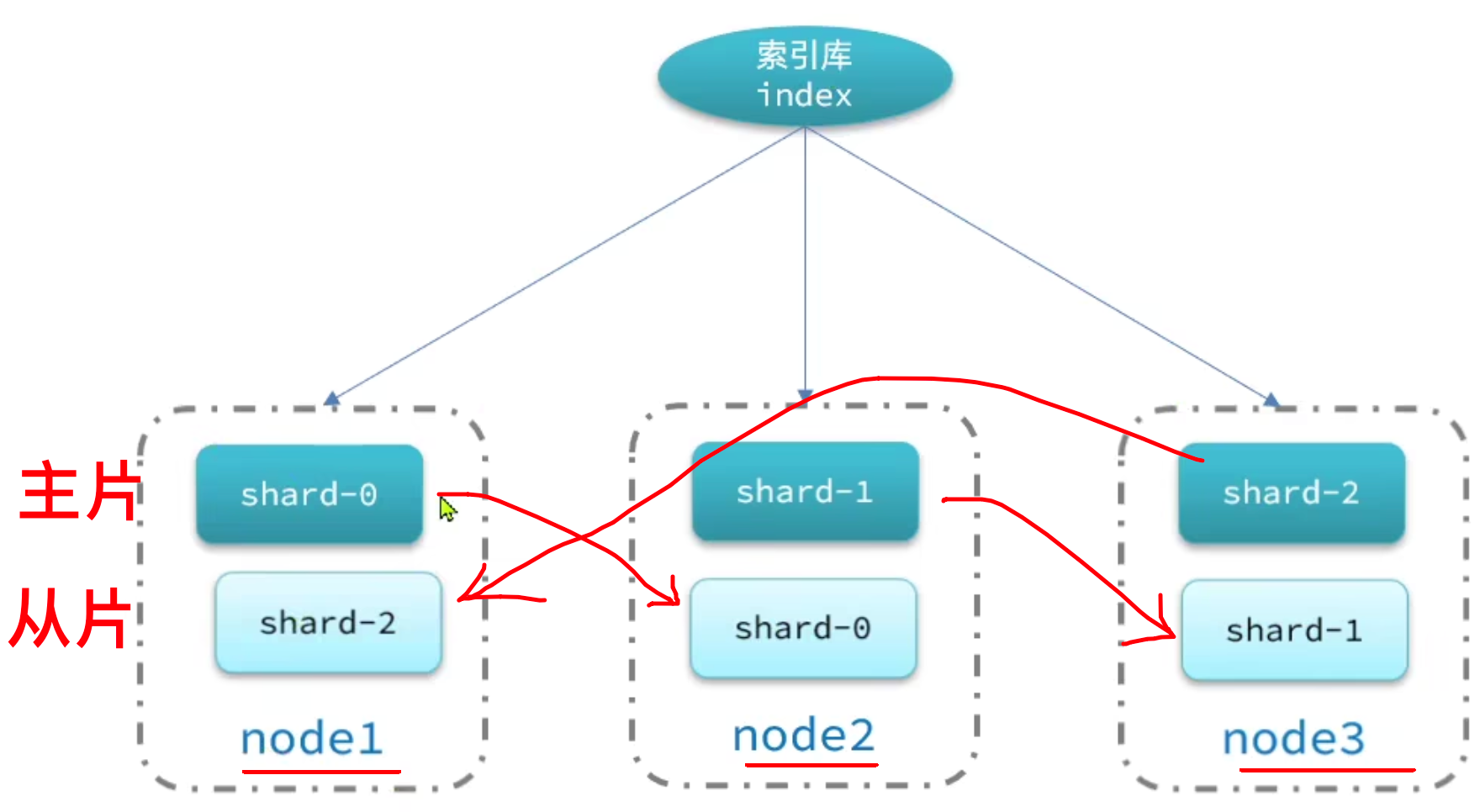
-
单机的 ES 面临 2 个问题:
- 海量数据存储问题
- 单点故障问题
-
解决方式:
- 将索引库进行逻辑分片,存储至多个节点
- 将分片的数据复制多份,分发到不同节点
微服务保护 + 面试三板斧:分布式事务、分布式缓存、分布式消息
十一、微服务保护 Sentinel
阿里 Sentinel,相比 Nginx 更加细粒度
流量控制、隔离降级、授权规则、规则持久化
一、基础与安装
-
简介:
- Sentinel 是阿里开源的微服务流量控制组件,是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
- 常用来防止“雪崩问题”
- 程序端口
8719,控制台端口自定义,注意两个端口是不一样的东西。
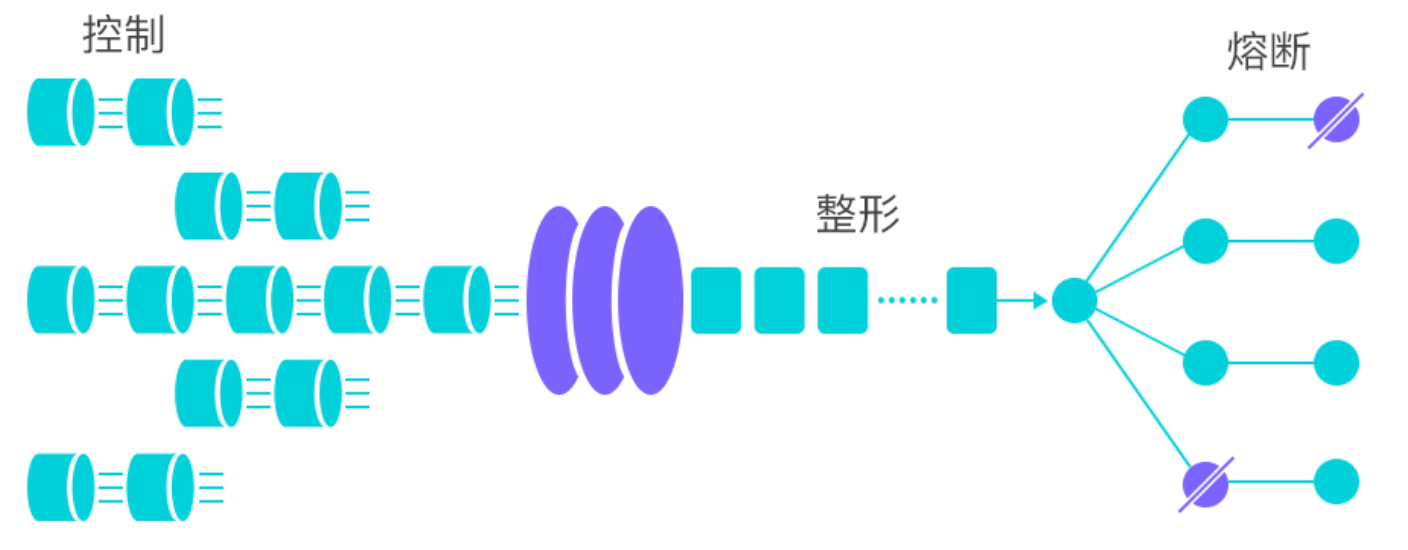
-
什么是雪崩问题?如何解决?
在微服务之间相互调用时,因为个别微服务发生故障而引起整条链路都发生故障的情况。
-
故障后纠错:超时处理、线程隔离、降级熔断(失败达到一定比例次数时暂停访问)。
-
故障前预防:流量控制,使用 Sentinel 哨兵模式限制业务访问的QPS,避免服务因流量突增而故障。
-

-
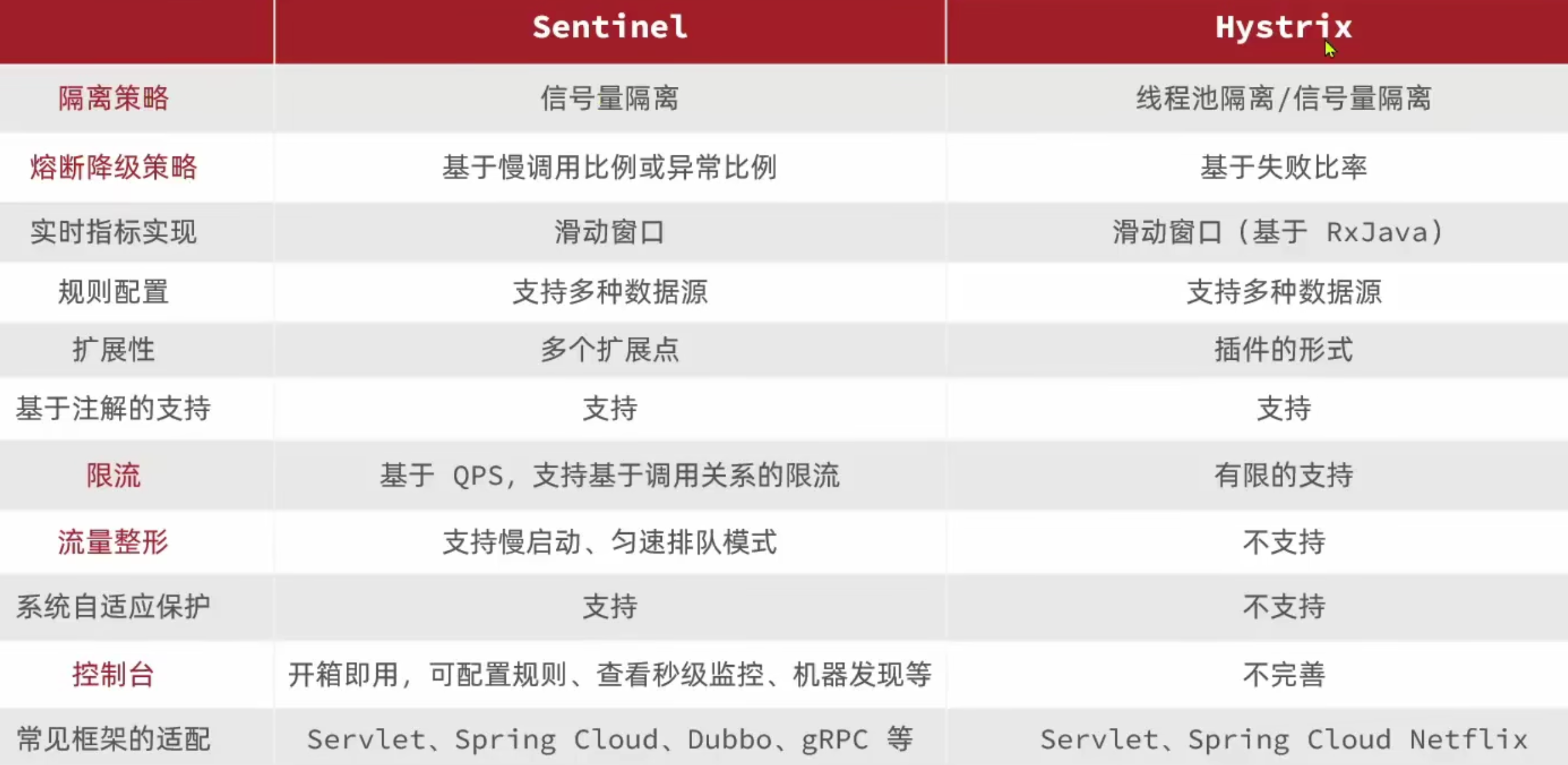
常见的服务保护技术对比
-
基本概念
-
资源
资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
-
规则
围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
-
-
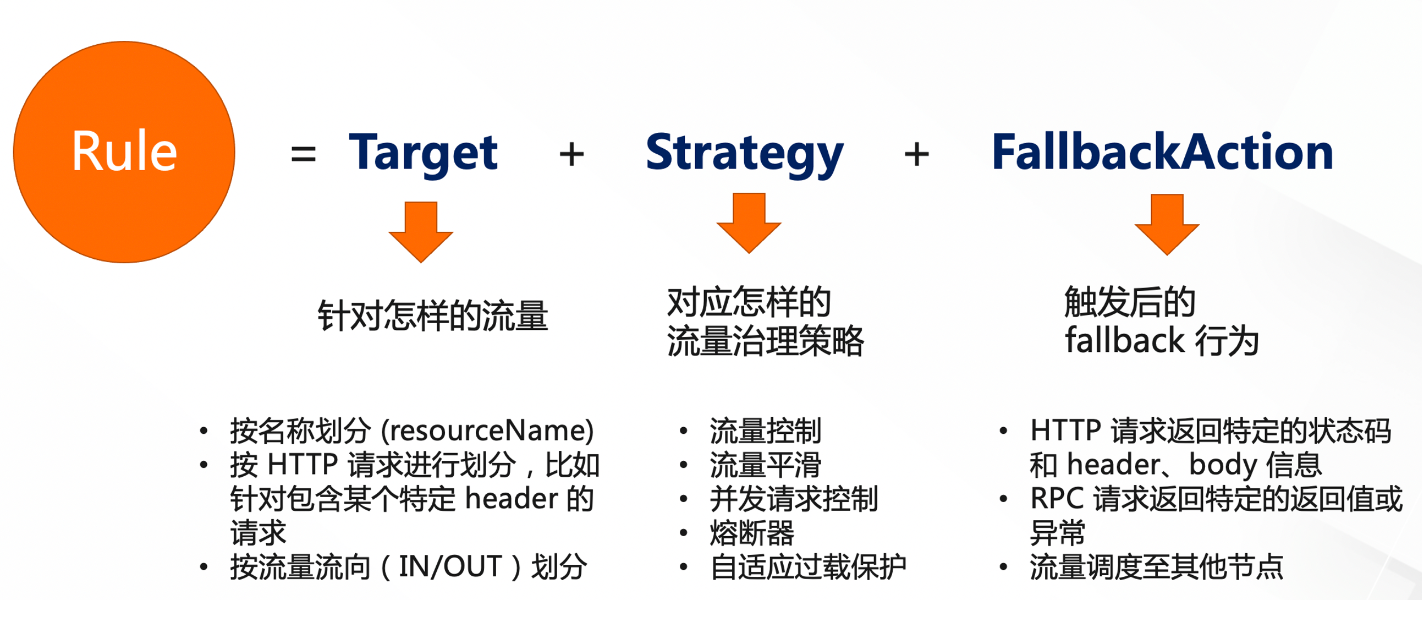
流控降级与容错标准
Rule = target + strategy +fallbackAction
-
安装步骤
- GitHub下载( jar包,Spring Boot 程序)
- 命令行启动
指定控制台端口为 8090(程序端口依旧为 8719),账号 Sentinel,密码123456.
java -Dserver.port=8090 \ -Dsentinel.dashboard.auth.username=sentinel \ -Dsentinel.dashboard.auth.password=123456 \ -jar sentinel-dashboard-1.8.6.jar

-
代码配置
- 选择某一服务
- 引入依赖并配置地址
- 启动程序,访问一次**端点(EndPoint)**后Sentinel生效(即访问一个Controller后生效)
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>spring: cloud: sentinel: transport: dashboard: localhost:8090
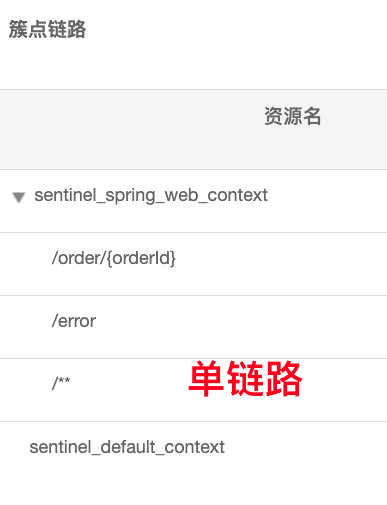
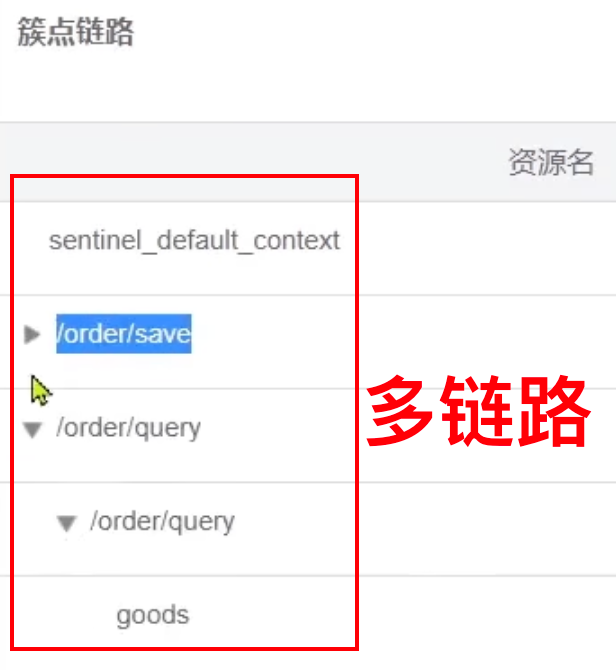
二、簇点链路
-
简介:
即项目内的调用链路,链路中被监控的一个接口就是一个资源。
默认情况下 sentinel 会监控 SpringMVC 的每一个端点( Controller),因此每一个端点就是调用链中的一个资源,我们可对资源进行如下 4 种操作:
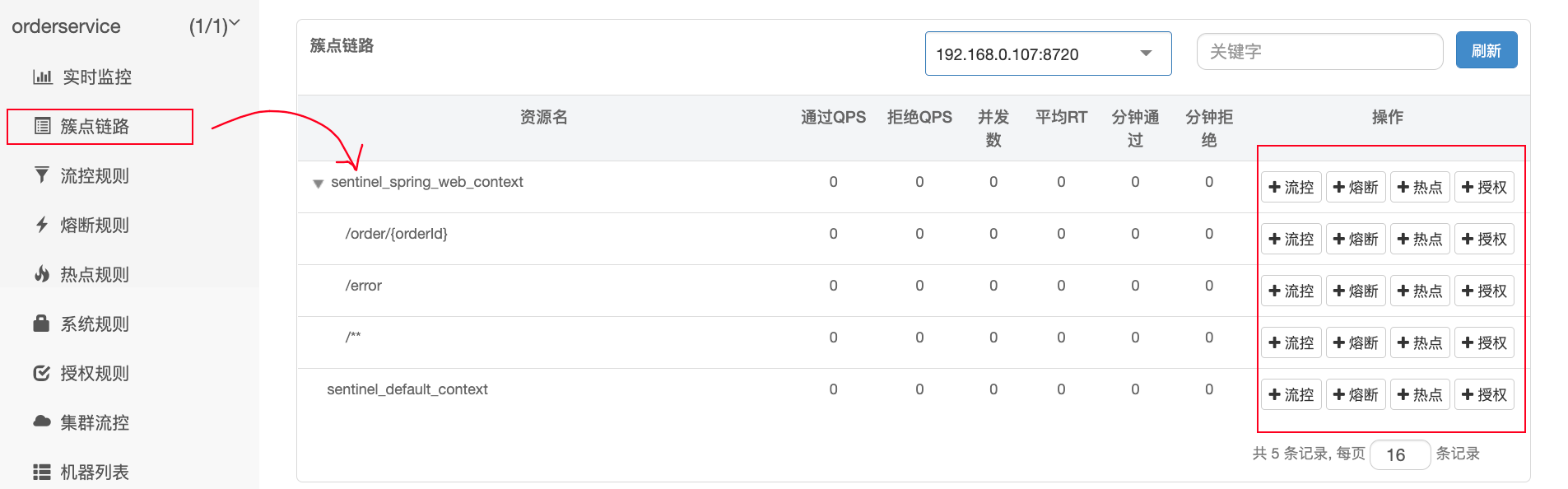
-
流控:流量控制
-
降级:熔断降级
-
热点:热点参数限流
-
授权:授权规则
-
-
【注意】
Sentinel 默认只会将 Controller 中的方法标记为“资源”,如果要标记其他方法(例如 Sevice),则要:
- 关闭 Sentinel context 整合模式(该模式为默认模式,会将所有的 Controller 整合成单一链条,而我们现在需要多条链条的模式)
- 使用
@SentinelResource注解标记方法
spring: cloud: sentinel: web-context-unify: false@SentinelResource("名称") public void queryGoods(){ // err 会打印出“红色标记”,更容易辨认 System.err.println("查询商品") }
三、流控模式
-
Sentinel提供了 3 种限流模式
- 直接限流(默认):统计当前资源的请求,触发阈值时对当前资源直接限流。
- 关联限流:统计与当前资源相关的另一个资源,触发阈值时对当前资源限流。例如存在端点 a 和 b ,本来两者并无关系,现在让两者“关联”,设置当 a 的访问次数达到阈值时,b 停止服务。(即优先 a,另外要限制谁就设置谁 )
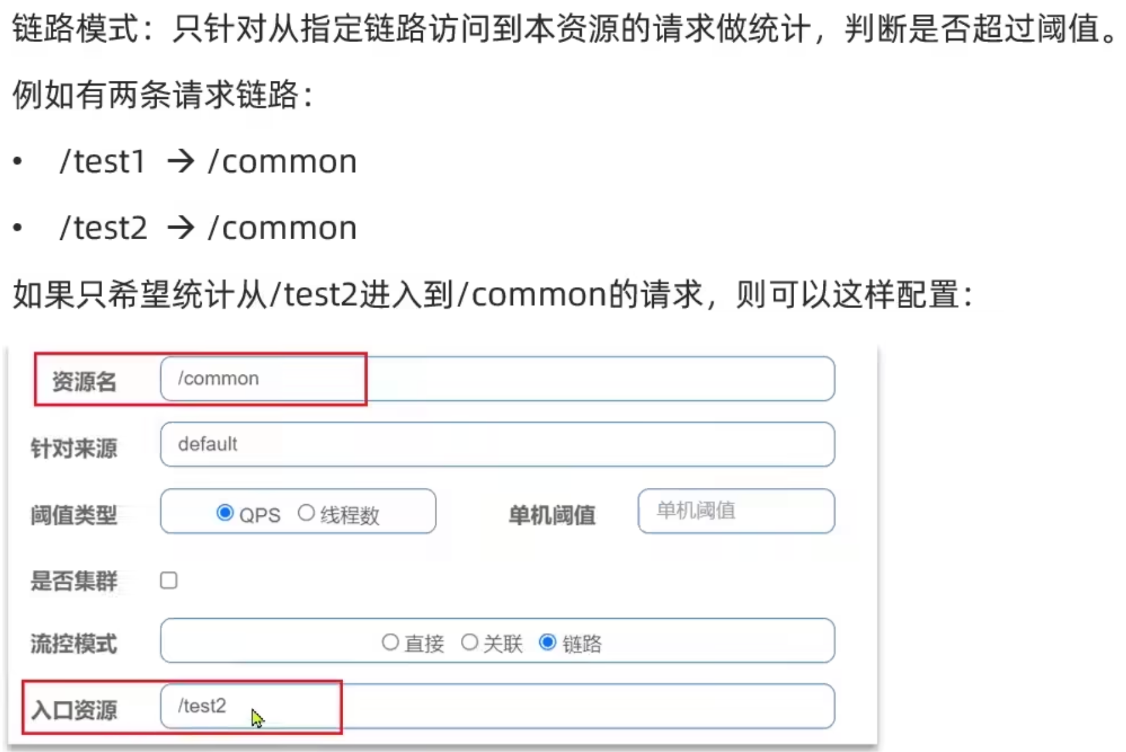
- 链路限流:统计从指定链路访问到本资源的请求,触发阈值对指定链路限流。如端点 a 与 b 均向 c 请求服务,则 c 可以只限制 a 链路,而对 b 链路不限制。(分别对待)
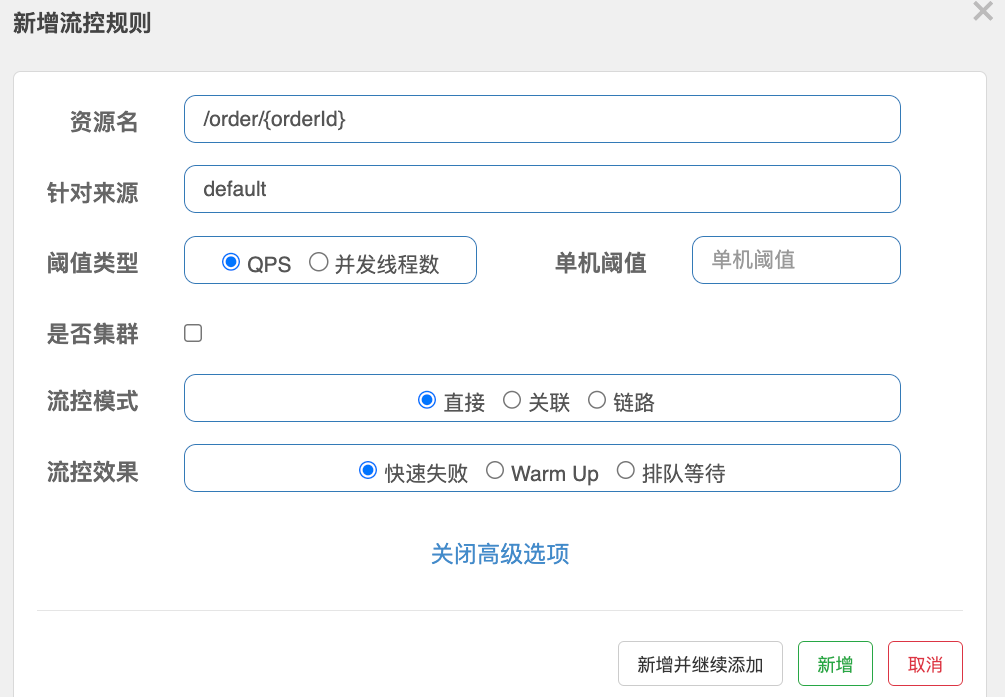
-
【关联限流】配置
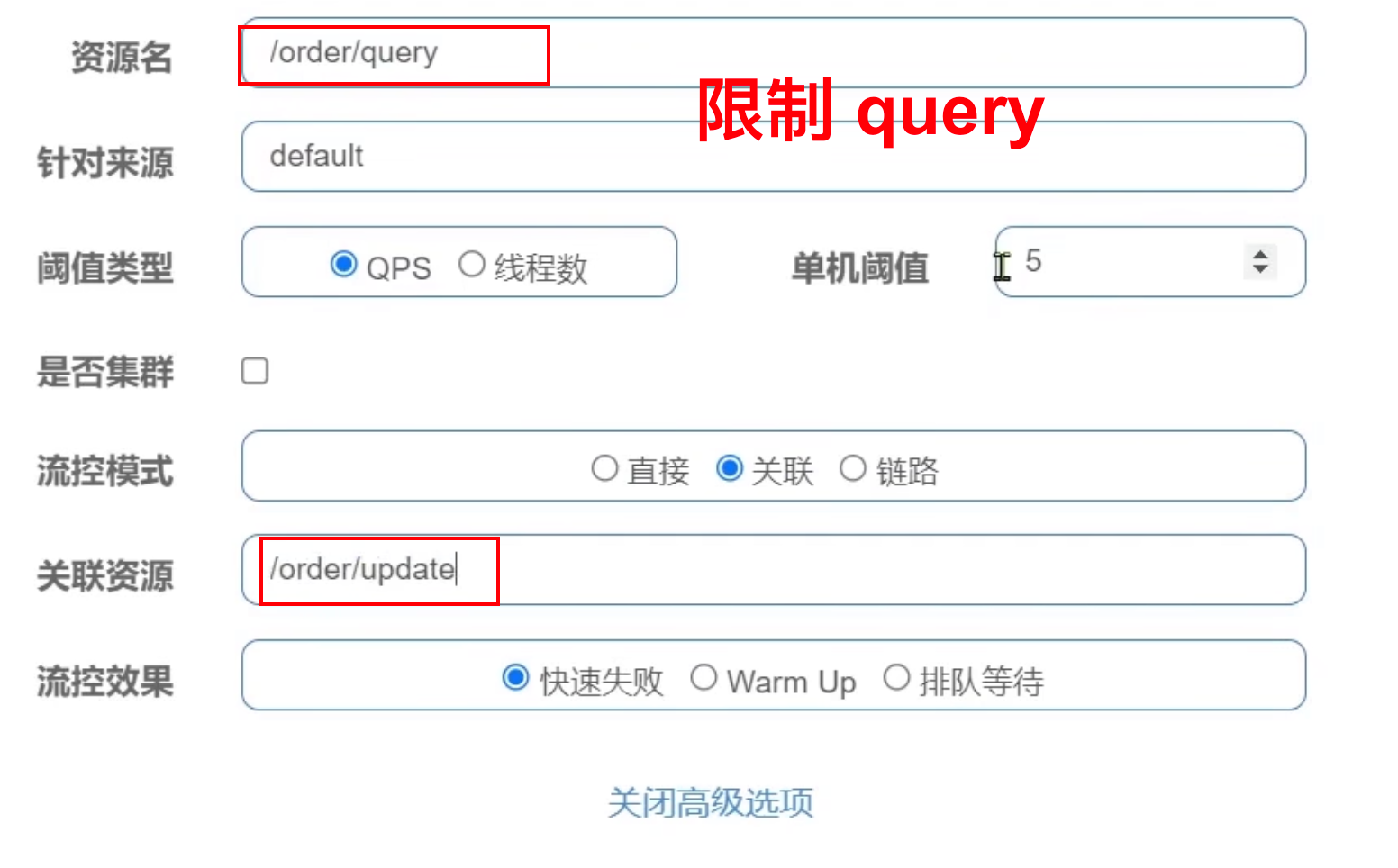
利用 update 限制 query,即 update 更新请求具有更高的优先级。
- 【链路限流】配置
-
失败返回数据

四、流控效果

- 快速失败:(默认、漏桶算法)QPS超过阈值,拒绝新的请求
- Warm Up:缓慢增长,QPS阈值缓慢增长(初始值为阈值的
1/3),可以避免冷启动时高并发导致的服务宕机,超过阈值拒绝新的请求。 - 排队等待:(令牌桶算法)请求会进入队列等待,按照阈值设置的时间间隔依次执行请求,如果请求预期等待的时间大于超时时间,则直接拒绝。
五、热点参数限流
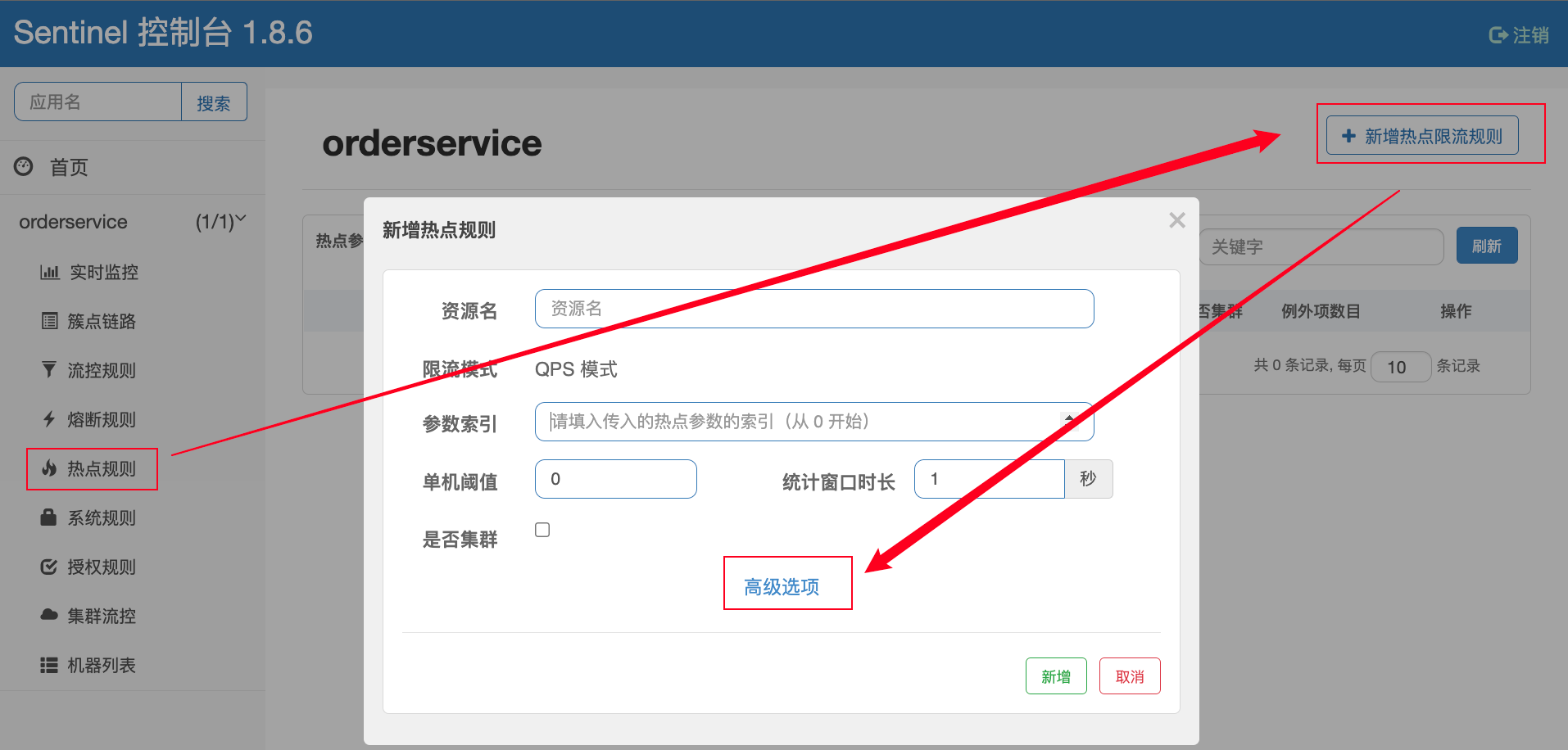
相较于 流控规则 ,热点参数限流规则 更细力度。
-
简介:对参数相同的请求进行限流。
-
配置选项
-
【注意】
Sentinel 的热点限流规则对只属于 Spring MVC 的资源无效,要想生效则必须标识
@SentinelResource注解。@SentinelResource("hot") @GetMapping("/hot") public String hot(){ return "hot榜单"; } -
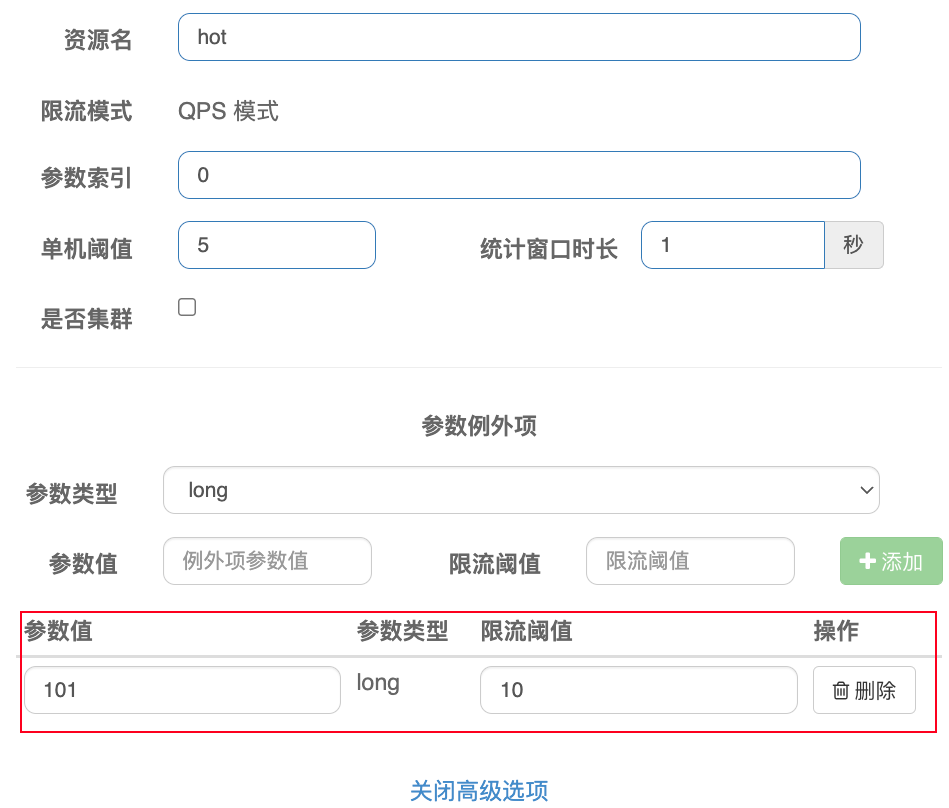
案例
- 对
hot资源的 0 号参数(第一个参数)做统计,相同参数值的请求每秒不能超过5次。
- 对
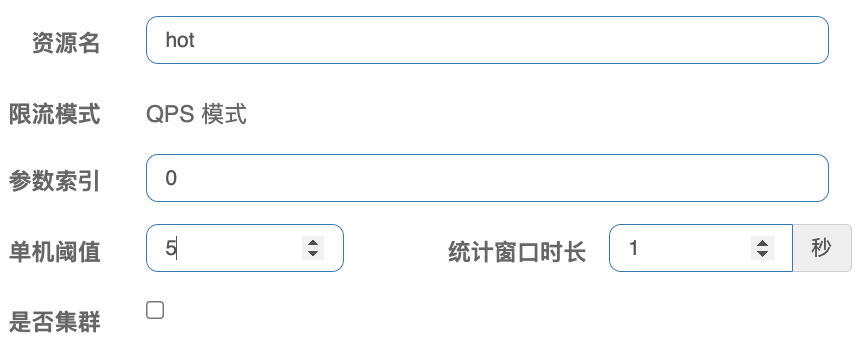
- 在上面的前提下,存在例外:参数值为
101的请求,阈值应为10。
六、整合Feign
“流控 与 热点”基于
QPS进行的限流整合 Feign 可以通过
线程数来进行限流
-
简介:
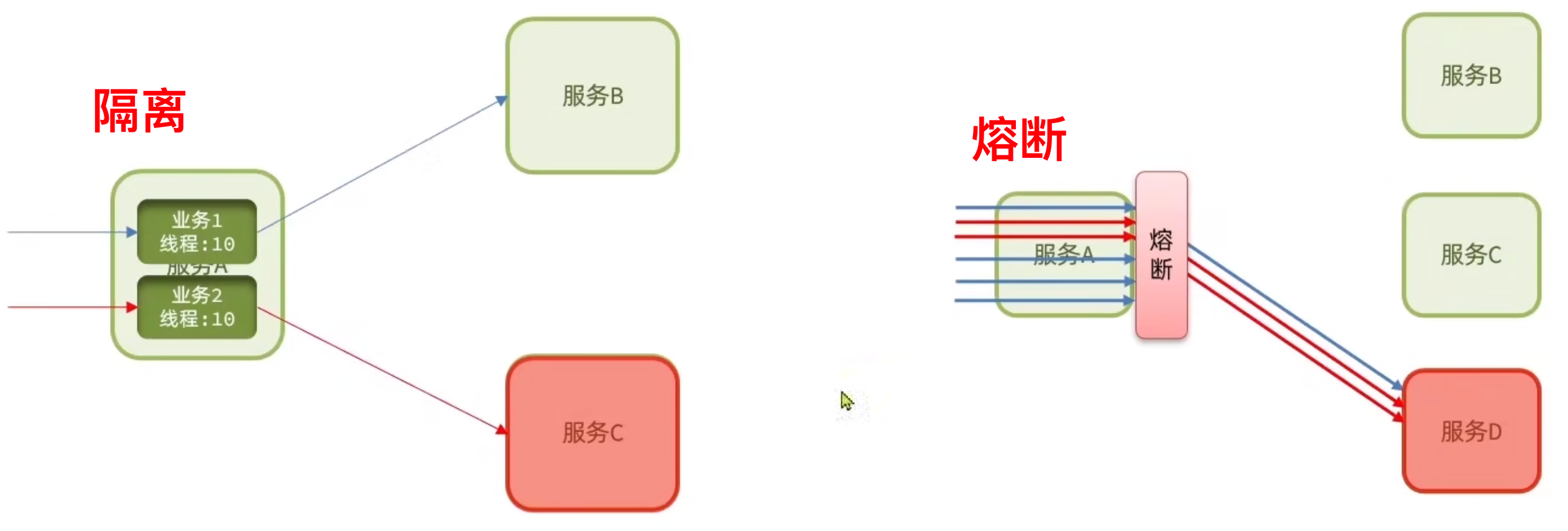
虽然限流可以尽量避免因高并发而引起的服务故障,但服务还是会因为其他原因而故障。我们要将这些故障控制在一定的范围内、避免雪崩,就要靠线程隔离和熔断降级。不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。
-
Feign整合Sentinel步骤
- 修改服务yaml配置,开启 Feign对 Sentinel 的支持
- 在 Feign Api 项目中定义
反馈类,实现泛型接口FallbackFactory<T>并注册成 Bean 对象。 - 在 Feign Api 项目中令原先的 UserClient 接口使用新建的
反馈类
feign: sentinel: enabled: true
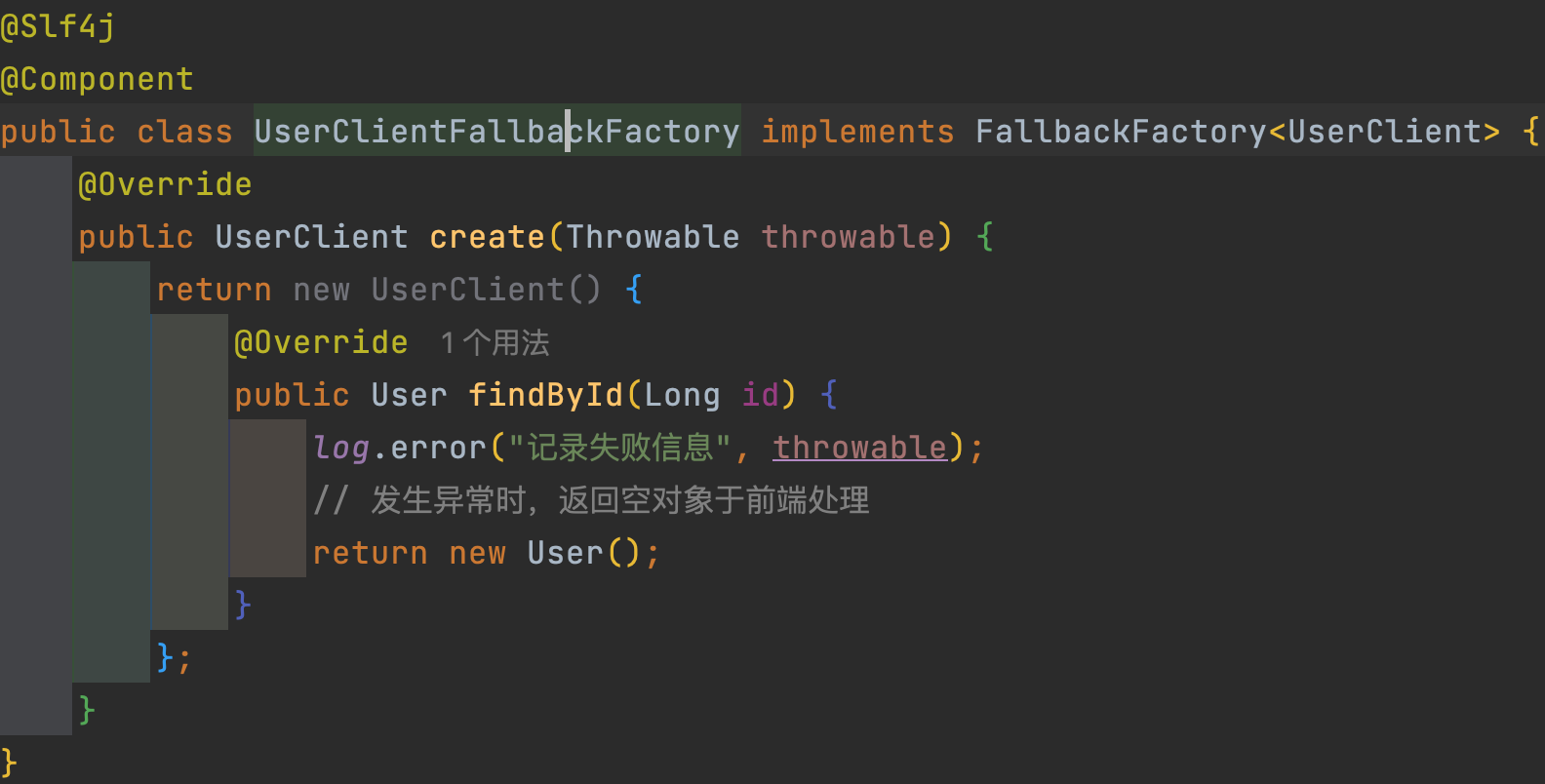
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public User findById(Long id) {
log.error("记录失败信息", throwable);
// 发生异常时,返回空对象于前端处理
return new User();
}
};
}
}
@Configuration
public class DefaultFeignConfiguration {
@Bean
public UserClientFallbackFactory factory ( ){
return new UserClientFallbackFactory();
}
}

通过对 Feign 的配置控制后,可以在 Sentinel 中设置限制最大
并发线程数实现限流

-
上步补充:
给 FeignClient 编写失败后的降级逻辑可以继承自 2 个接口:
- FallbackClass:无法对远程调用的异常作处理。
- FallbackFacotory:可以对远程调用的异常作处理(所以我们使用这种方式)。
-
==【线程隔离】==简介
2 种方式。
- 信号量隔离**( Feign 默认)**:使用PV模式对固定信号量进行分配,有则分、无则拒。
- 线程池隔离:针对不同的服务请求建立不同的线程池,隔离性高、资源消耗量大。
-
==【熔断降级】==简介
解决雪崩问题的重要手段,由断路器统计服务的异常比例、慢请求比例,如果超过阈值则会进行熔断(即拒绝服务),一段时间后断路器会再次统计服务异常比例,如果服务良好则恢复正常。
熔断降级,一共由 3 个阶段,分别为:
- Closed:正常状态
- Open:达到阈值,快速失败
- Halt-Open:尝试放行一次请求进行测试。
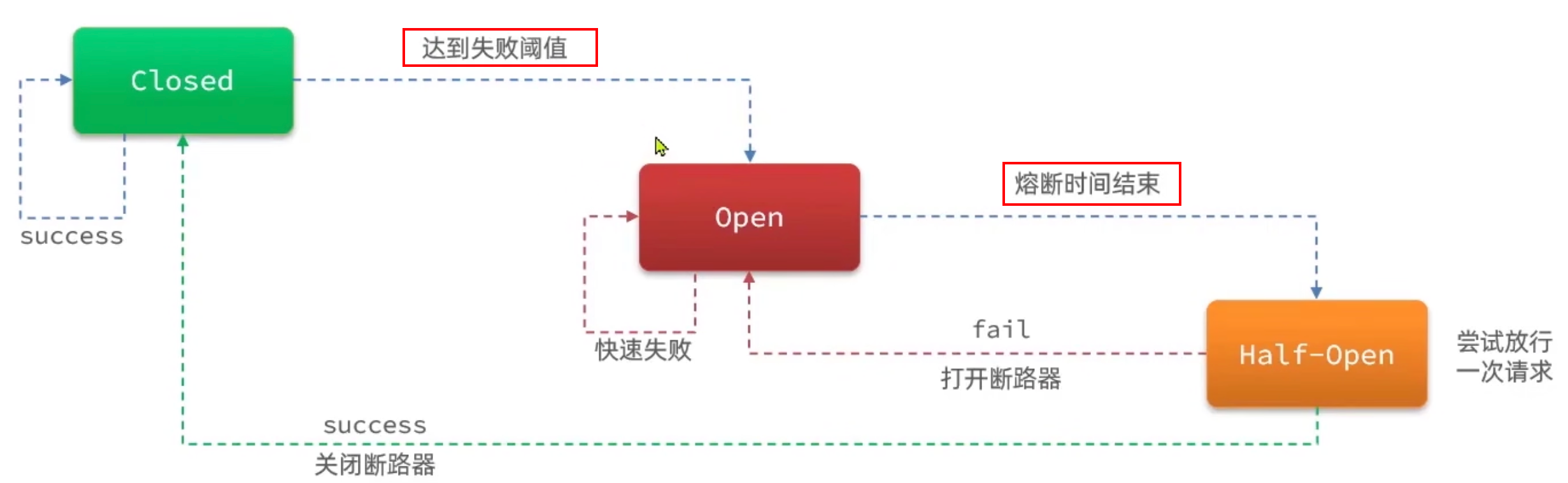
-
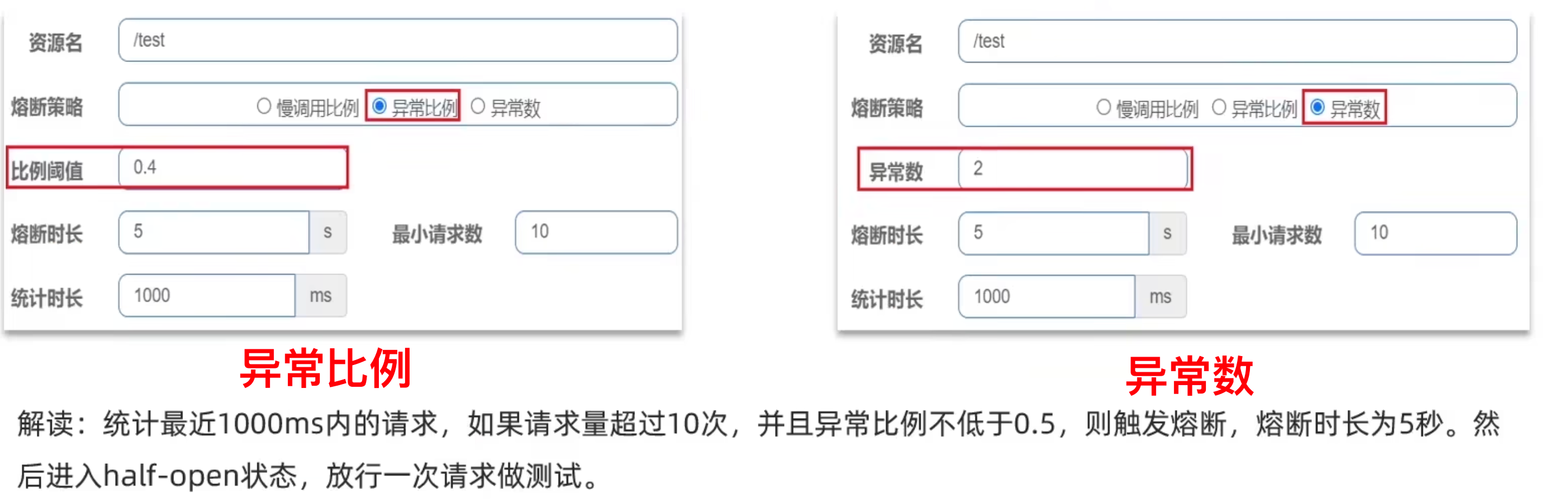
【断路器】的 3 种熔断策略:

- 慢调用比例:业务响应时间(RT,Response Time)大于指定时长的请求被认定为慢调用,监控比例。
- 异常比例:监控指定时间业务产生的异常比例。
- 异常数:监控指定时间业务产生的异常数。

七、系统规则
只对 Linux 系统有效,保护系统

八、授权规则
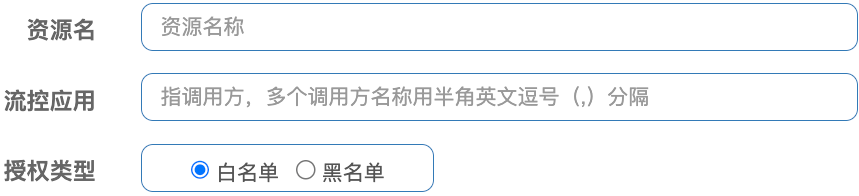
-
简介:
- 黑名单、白名单
- 服务鉴权,例如某微服务只想被网关访问,不想被外网或者内部直接访问,则可以设置白名单规则。
- 在网关上定义每次发送请求时都会携带相应的“请求头”,如果微服务检测不到该请求头则拒绝响应。
-
实现:
- 某微服务中配置请求解析类(默认全局,有了这个类才能在 Sentinel 中设置鉴权规则,即 value 值)
- Sentinel 中设置鉴权规则(即 value 值)
- 网关配置 yaml 文件,标记每次发送请求都自动携带相应请求头
@Component public class HeaderOriginParser implements RequestOriginParser { @Override public String parseOrigin(HttpServletRequest request) { // cipher 为网关中自定义的请求头 key String cipher = request.getHeader("cipher"); if (StringUtils.isEmpty(cipher)){ return "blank"; } return cipher; } }
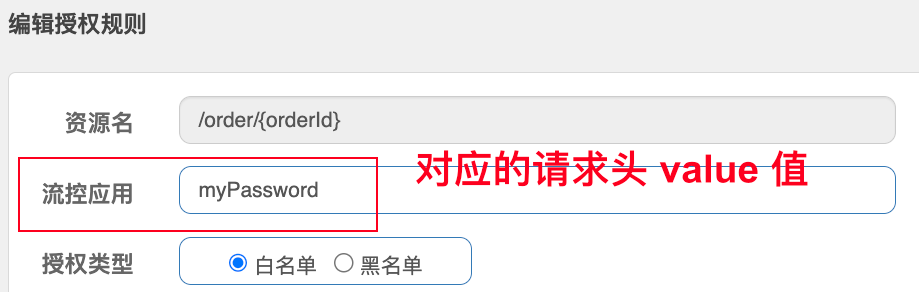
spring:
cloud:
gateway:
default-filters:
# 网关每次发送请求都会默认携带的请求头 key-value
- AddRequestHeader=cipher,myPassword
-
实现效果:
- 不经过网关直接访问服务
http://localhost:8088/order/101
- 经过网关访问服务
http://localhost:10010/order/101?authorization=admin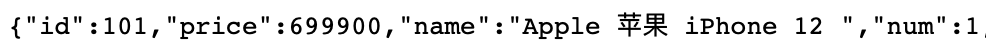
九、自定义异常
-
简介
在前面我们可以观察到无论是被限流、熔断降级、授权拒绝,被请求的微服务总是会返回相同的响应数据
Blocked by Sentinel (flow limiting),这对于用户来说并不友好,我们可针对不同的场景定义不同的响应内容。 -
可定义的异常类型

-
实现方式:自定义
___BlockHandler并实现BlockExceptionHandler接口,返回不同内容。@Component public class SentinelExceptionHandler implements BlockExceptionHandler { @Override public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception { String msg = "未知异常"; int status = 429; // 自适配异常类型,返回不同内容 if (e instanceof FlowException) { msg = "请求限流"; } else if (e instanceof ParamFlowException) { msg = "请求热点参数限流"; } else if (e instanceof DegradeException) { msg = "请求降级"; } else if (e instanceof AuthorityException) { msg = "未授权"; status = 401; } response.setContentType("application/json;charset=utf-8"); response.setStatus(status); response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}"); } }
十、规则持久化
待后续寻找最佳方案并实现,官网教程
-
简介:
Sentinel默认将配置保存在内存中,重启数据丢失。
-
数据的 3 种控制台管理模式:
- 原始模式:(默认)将规则保存在内存中,重启则丢失。
- Pull 模式:控制台将配置规则推送到 【Sentinel 客户端】,客户端将配置保存在本地文件或数据库,集群中的其他 Sentinel 客户端则定时读取配置(存在问题:时效性慢、更新不及时)。目前支持动态文件数据源、Consul 、Eureka。
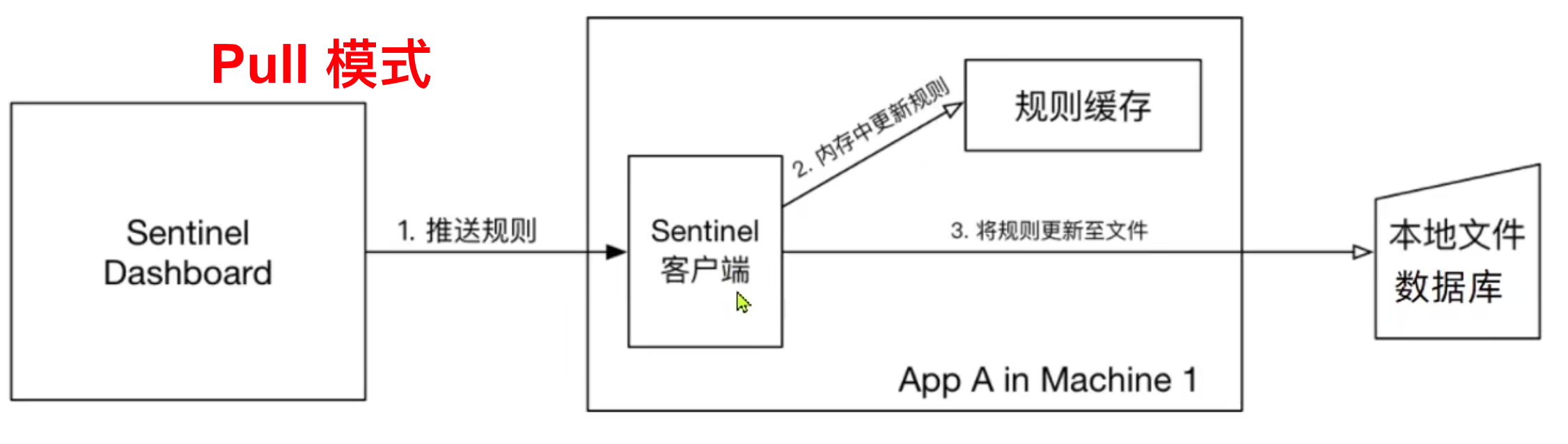
- Push 模式:控制台将配置规则推送到【远程配置中心】(如 Nacos ),其他 Sentinel 客户端则监听 Nacos 实现配置的存储与及时更新。目前支持 ZooKeeper、Redis、Nacos、Apollo、etcd。
-
【注意点】
在以上 3 种方式种,Push 模式无疑是最好的,但是阿里在开源 Sentinel 的时候并没有附带此模式,而是将其作为商业版(云服务)进行兜售,所以如果我们不想要付费,并且想要实现 Push 模式的规则持久化,则需要自己改写并编译 Sentinel 程序,实现起来相当复杂。
十一、整合原有项目
Sentinel整合原有项目非常简单,只需要引入依赖,然后进行简单的 yml 配置即可,但是需要注意 Sentinel 所兼容的 SpringBoot 版本问题(SpringBoot版本太新时,需要降级)。
但是没有持久化就意味着服务终归还是不稳定!!!
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
<version>2021.1</version>
</dependency>
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
# 存在一些“循环依赖”的情况,下面配置允许忽略这种情况(否则报错)
main:
allow-circular-references: true
十二、分布式事务 Seata
1、简介
-
事务基本要求:ACID,原子性、一致性、隔离性、持久性。
-
本章解决问题:
基于微服务的分布式事务。在分布式系统下,一个业务跨越多个服务或数据源,每个服务都是一个分支事务,要保证所有分支事务最终状态一致,这样的事务就是分布式事务。
-
CAP定理
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有 3 个指标:
- Consistency:一致性
- Available:可用性
- Partition tolerance:分区容错性
于是 CAP 定理的内容为:
- 分布式系统节点通过网络连接,一定会出现分区问题(P)
- 当分区出现时,系统的一致性(C)和可用性(A)就无法同时满足
我们之前搭建的 Elasticsearch 集群属于 CP,不属于 AP。
-
BASE理论
解决CAP存在的问题
- Basically Available(基本可用):在分布式系统出现故障时,允许损失部分可用性,但保证核心可用。
- Soft State(软状态):在规定时间内允许出现不一致状态。
- Eventually Consistent(最终一致性):数据最终会达到一致性。
解决的方式:
- 【AP模式】:各子事务分别提交,允许出现结果的不一致,然后采用措施恢复数据,最终达到一致性。
- 【CP模式】:各子事务执行后互相等待,同时提交、同时回滚,最终达到一致性。但在事务等待的过程,本次服务处于弱可用,同时因为各子事务必须彼此感知各自事务状态才能保证一致性,因此需要一个“事务协调者”负责协调,由此也诞生出了全局事务、分支事务的概念。
2、Seata简介
分布式事务解决方案,http://seata.io/zh-cn/
每个微服务都需配置 Seata,略微繁琐
-
简介:
- Seata 是 2019 年 1 月份蚂蚁金服与阿里巴巴共同开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。
- Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
-
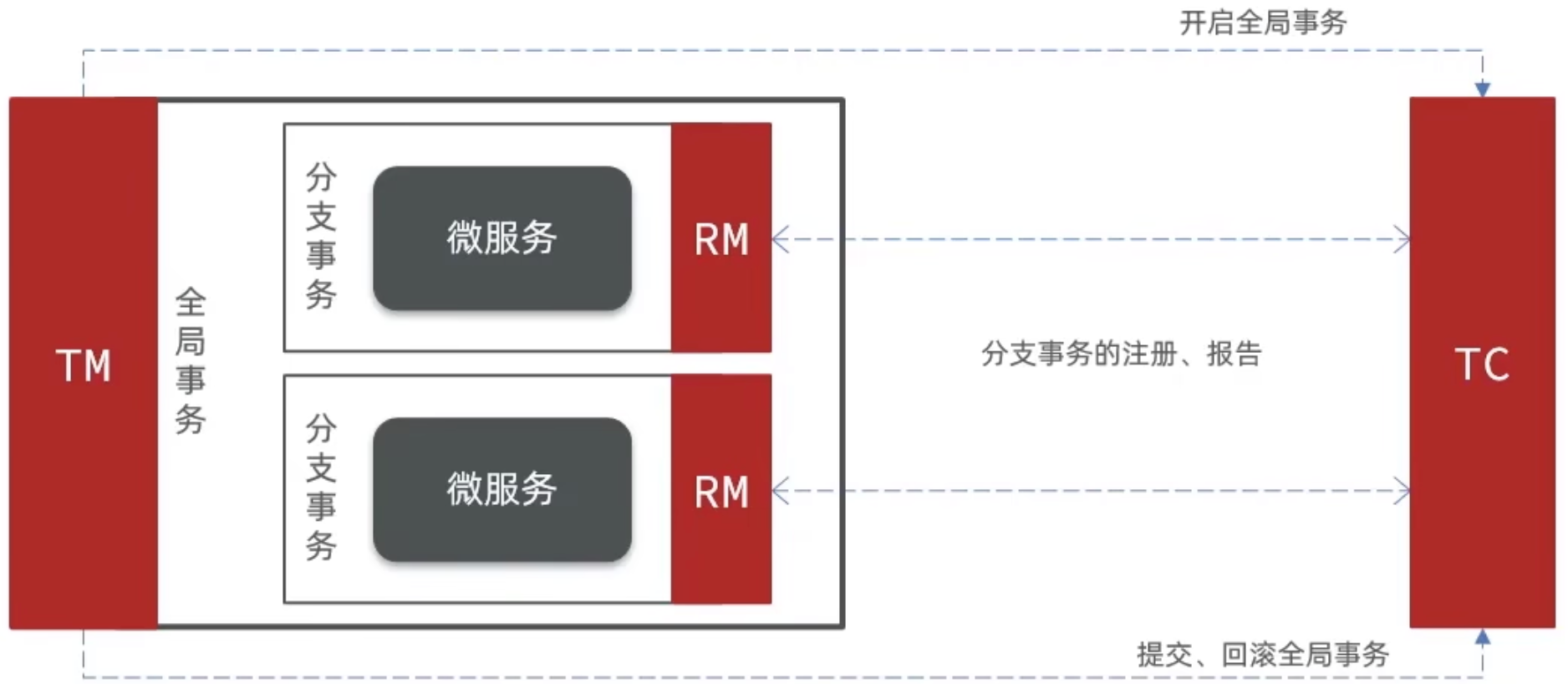
Seata 事务中有 3 个重要角色
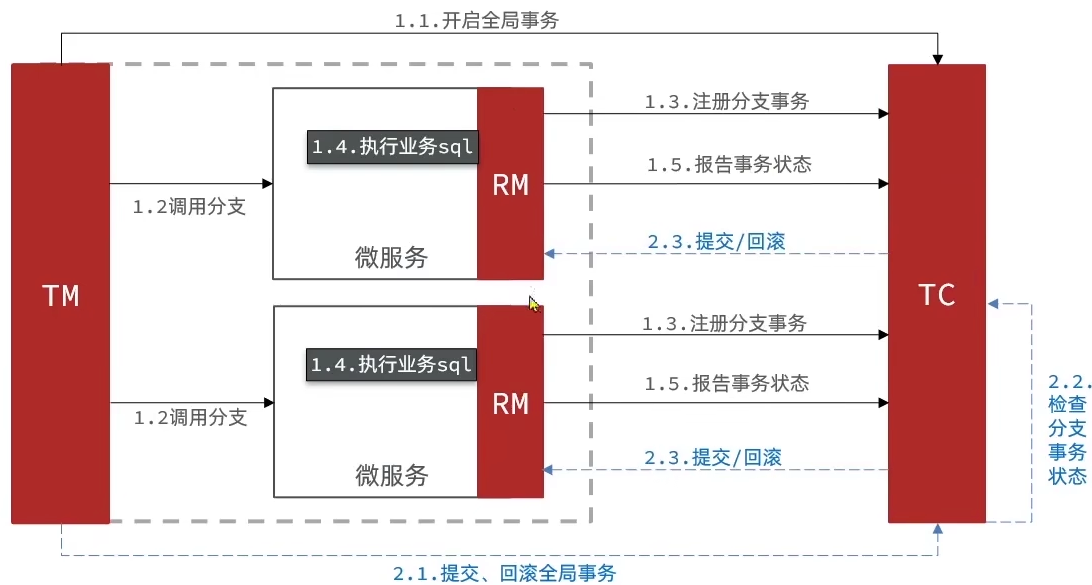
- TC(Transaction Coordinator)事务协调者:维护全局事务和分支事务的状态,协调全局事务的提交与回滚。
- TM(Transaction Manager)事务管理器:定义全局事务的范围,开启、提交或回滚全局事务。
- RM(Resource Manager)资源管理器:管理分支事务,向 TC 注册分支事务并报告状态,提供分支事务的提交与回滚功能。
Seata 就是 TC(作为TC,搭建成功后我们不需要访问它,这是给 TM 和 RM 访问的),企业中需要搭建集群。
-
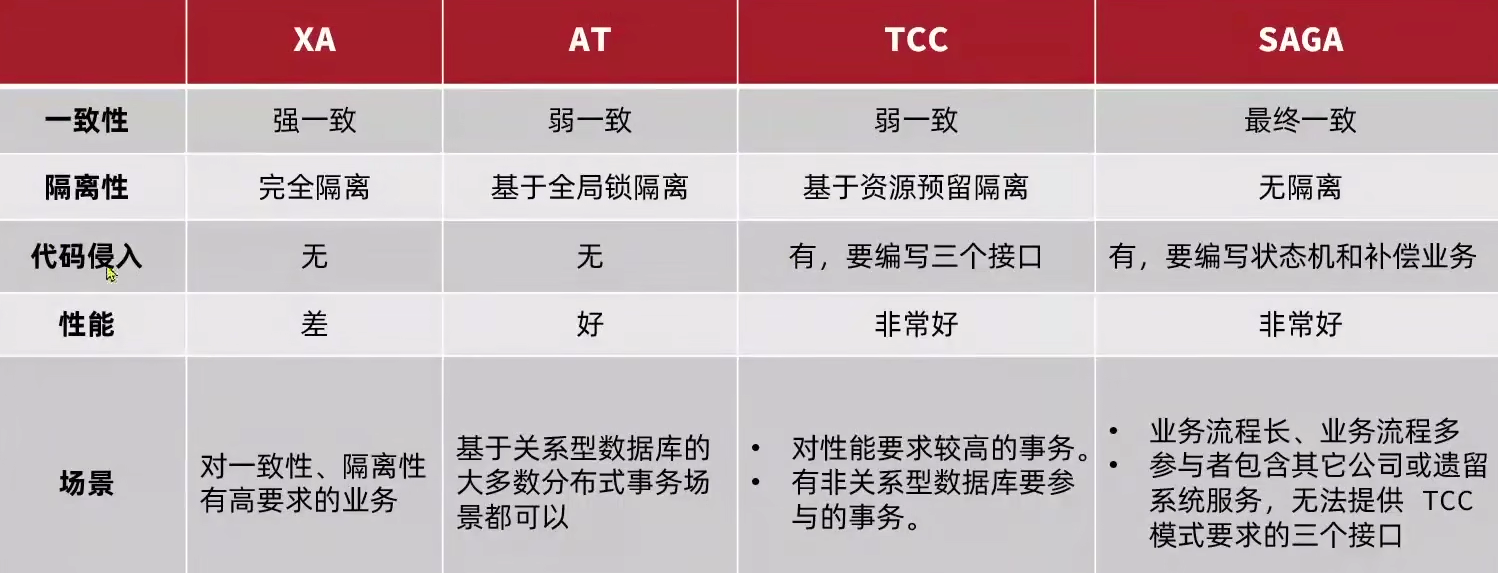
Seata提供了 4 种不同的分布式事务处理方案:
- XA模式:强一致性分布阶段事务模式,牺牲一定可用性,无业务侵入。
- AT模式(默认):最终一致的分阶段事务模式,无业务侵入。
- TCC模式:最终一致的分阶段事务模式,有业务侵入。
- SAGA模式:长事务模式,有业务侵入。
3、安装
- 下载 seata-server 包并解压:https://github.com/seata/seata/releases
-
修改conf目录下的
application.yml文件1.4.2版本为
registry.confserver: port: 7091 spring: application: name: seata-server logging: config: classpath:logback-spring.xml file: path: ${user.home}/logs/seata # 若无以下配置则注释 # extend: # logstash-appender: # destination: 127.0.0.1:4560 # kafka-appender: # bootstrap-servers: 127.0.0.1:9092 # topic: logback_to_logstash console: user: username: seata password: seata seata: # 配置中心 config: type: nacos nacos: server-addr: 127.0.0.1:8848 namespace: "" # 命名空间为空,默认 public group: SEATA_GROUP username: nacos password: nacos data-id: seataServer.properties # 注册中心 registry: type: nacos nacos: server-addr: 127.0.0.1:8848 namespace: "" group: DEFAULT_GROUP username: nacos password: nacos cluster: SH # SH表示上海 # 已经配置了 nacos 作为配置中心,所以这里 store 与 server 不配置 # store: # support: file 、 db 、 redis # mode: file # server: # service-port: 8091 #If not configured, the default is '${server.port} + 1000' security: secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017 tokenValidityInMilliseconds: 1800000 ignore: urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-fe/public/**,/api/v1/auth/login -
新建数据库
seata,在此基础上新增两张表branch_table与global_table作事务管理。SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; DROP TABLE IF EXISTS `branch_table`; CREATE TABLE `branch_table` ( `branch_id` bigint(20) NOT NULL, `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `status` tinyint(4) NULL DEFAULT NULL, `client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime(6) NULL DEFAULT NULL, `gmt_modified` datetime(6) NULL DEFAULT NULL, PRIMARY KEY (`branch_id`) USING BTREE, INDEX `idx_xid`(`xid`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; DROP TABLE IF EXISTS `global_table`; CREATE TABLE `global_table` ( `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `status` tinyint(4) NOT NULL, `application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `timeout` int(11) NULL DEFAULT NULL, `begin_time` bigint(20) NULL DEFAULT NULL, `application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime NULL DEFAULT NULL, `gmt_modified` datetime NULL DEFAULT NULL, PRIMARY KEY (`xid`) USING BTREE, INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE, INDEX `idx_transaction_id`(`transaction_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; SET FOREIGN_KEY_CHECKS = 1; -
Nacos 新建配置文件
为 Seata 集群作准备
Nacos创建
seataServer.properties配置文件,修改 MySQL 数据库信息,其余配置默认。
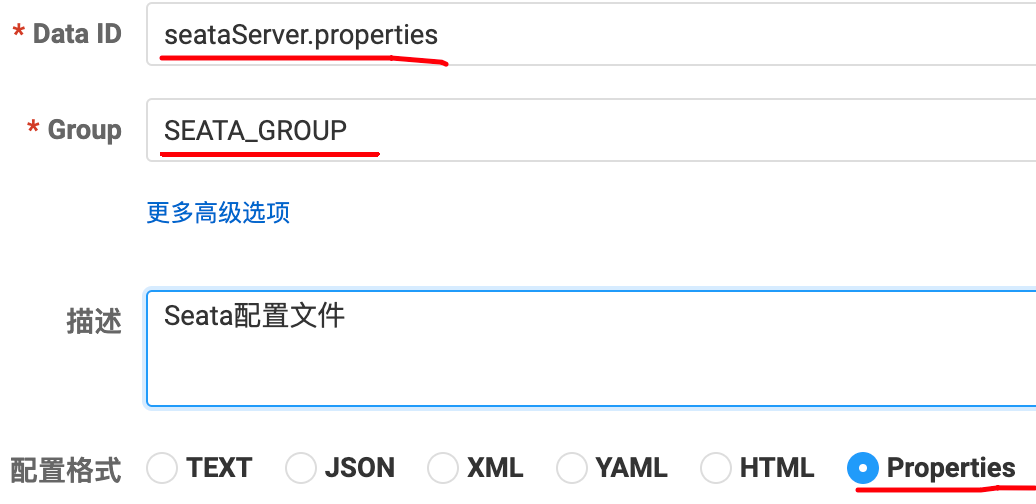
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=数据库密码
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
-
启动:
Linux 选择
.sh,Windows 选择.bat。另外注意这里可能会报
nohup: /Library/Internet: No such file or directory错误,原因是JDK路径查找失败,解决方式见我的另一篇博客。./bin/seata-server.sh -
查看启动日志:
/seata/logs/start.out判断是否启动成功。 -
微服务中引入依赖并配置连接
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <!-- 排除旧版本 Seata ,引入 1.6.1 版本 --> <exclusions> <exclusion> <artifactId>seata-spring-boot-starter</artifactId> <groupId>io.seata</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <version>1.6.1</version> </dependency>nacos服务名称必须包括 4 部分,而且每个微服务都必须配置这些信息,微服务将根据这些信息去注册 Seata。
namespacegroupserviceNameclusterseata: registry: type: nacos nacos: server-addr: 127.0.0.1:8848 namespace: "" group: DEFAULT_GROUP application: seata-server # TC 在 Nacos 中的名称 tx-service-group: seata-demo service: vgroup-mapping: seata-demo: SH
- 重启微服务,查看 Seata 日志

4、XA规范

-
分阶段事务模式,几乎所有的主流数据库都对其提供了支持。
-
示意图:
-
优点:
- 事务具有强一致性,满足ACID
- 常用数据库均支持,实现简单、无代码侵入
-
缺点:
- 事务之间耦合度很高
- 事务之间相互等待,性能较差
- 事务的实现依赖于关系型数据库
-
实现步骤
- 各微服务附加配置后重启
- 业务 Service 加 全局事务注解
@GlobalTransaction
seata: data-source-proxy-mode: XA # 使用 XA 模式@Override @GlobalTransactional public void create(Order order) { // 创建订单 // 扣用户余额 // 扣库存 } -
【补充说明】
data-source-proxy-mode配置的作用: 设置数据源代理模式,Seata 通过劫持数据源
data-source来实现分布式事务的管理,配置后所有事务都将由 Seata 托管。
5、AT模式
默认

-
同样是分阶段事务模式,弥补了 XA 模式中资源锁定周期过长的缺陷,但同时也牺牲了一些安全性。
-
示意图:允许先成功,后续使用
undo log进行回滚。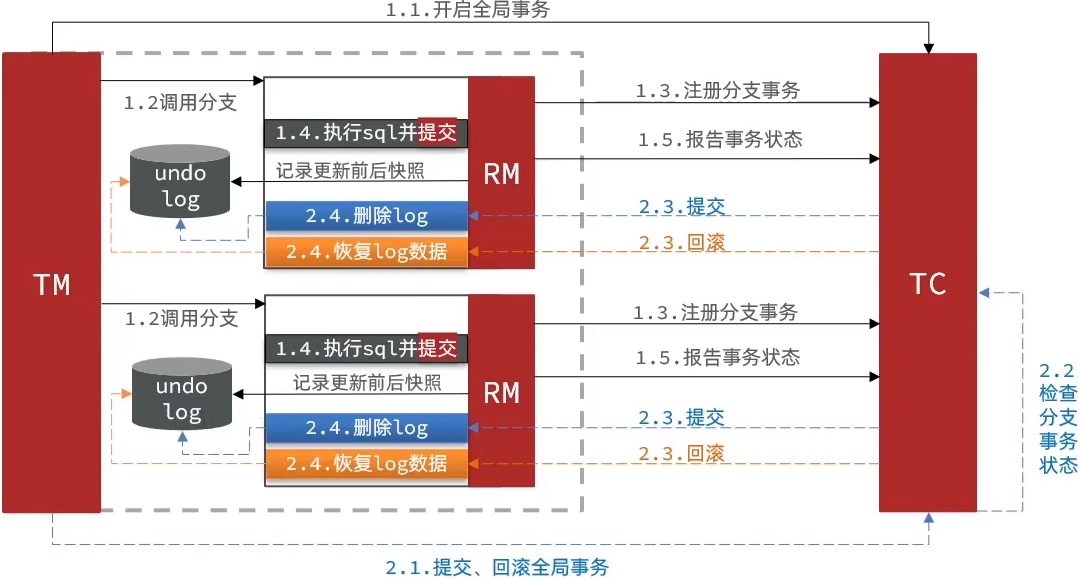
-
【脏读问题】:
这里阐述比较复杂,总之 AT 模式就是牺牲一定的安全性换来效率
-
由于各事务在一定程度上存在“独立性”,所以 AT 模式存在“脏读”现象。
-
AT 模式新增**【全局锁】**用来防止数据脏读,当数据遇到同时 update 请求时,全局锁会限制另一方的提交,直到原来的一方释放全局锁,此时 AT 模式相当于退化为 XA 模式。
-
但是全局锁只能作用于 Seata 事务,也就是说对非 Seata 管理的事务无效,在这种情况下依旧会产生“脏读”现象(无法解决)。幸运的是,Seata 能察觉这种现象的产生并抛出异常,我们可以捕获这种异常并编写代码发送邮件告知服务管理者。
-
当数据没有发生“脏读”问题时,AT模式效率较高,原因如下:
-
事务分布式提交,突破“木桶效应”限制。
- Seata 的“全局锁”粒度较细,只锁字段中的具体数据,对相同字段的其他数据无影响。
- MySQL 属于“粗粒度”锁,会锁住整张表,极大的降低效率。
// 例如在下面字段中,当 name 被某事务支配时,money字段并不受影响 {"id":1,"name":"张三","money":100}

-
-
【 XA模式 与 AT模式 总结】
AT模式牺牲的只是一些比较小的安全性(sava 与 update 属于“小概率”操作),换来的是极大的效率提升,在业务sava 与 update 次数较少且安全性要求不高的数据库,应优先使用AT模式。
-
实现步骤
- 数据库新建 2 张表,存储在不一样地方
lock_table:导入到与 TC(即 Seata 服务端)相关联的数据库undo_log:导入到与微服务相关的数据库(也就是在每个相关的微服务数据库中都需要导入undo_log表)
- 修改相关微服务的
application.yml配置文件,声明为使用 AT 模式(其实默认模式)。
DROP TABLE IF EXISTS `lock_table`; CREATE TABLE `lock_table` ( `row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `branch_id` bigint(20) NOT NULL, `resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime NULL DEFAULT NULL, `gmt_modified` datetime NULL DEFAULT NULL, PRIMARY KEY (`row_key`) USING BTREE, INDEX `idx_branch_id`(`branch_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id', `xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'global transaction id', `context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'undo_log context,such as serialization', `rollback_info` longblob NOT NULL COMMENT 'rollback info', `log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status', `log_created` datetime(6) NOT NULL COMMENT 'create datetime', `log_modified` datetime(6) NOT NULL COMMENT 'modify datetime', UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'AT transaction mode undo table' ROW_FORMAT = Compact;seata: data-source-proxy-mode: AT - 数据库新建 2 张表,存储在不一样地方
6、TCC模式

TCC模式效率很高,但过于复杂
具体案例见:链接
-
简介
需编写代码分别实现 3 个阶段
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源释放
-
示意图:

-
优点:
- 分布式提交事务,效率高
- 相比 AT 模式,无需生成快照(即 undo_log)、无需使用全局锁,性能最强
- 依赖补偿操作,不依赖数据库事务,可用于非事务型数据库
-
缺点:
- 代码侵入性很强,需同时编写 try、confirm、cancel 接口,特别繁琐与麻烦
- 事务最终一致而不是强一致
- 需要考虑Confirm与Cancel失败的情况,即做好幂等处理
- 另外需要注意空回滚的情况
-
【名词解释】
- 空回滚:当某分支事务的 try 阶段阻塞时,可能导致全局事务超时而触发其他服务的 cancel 操作。在未执行 try 操作时先执行了 cancel 操作,这时 cancel 不能做回滚,就是空回滚。
- 幂等处理:对于已经空回滚的业务,如果以后继续执行 try,就永远不可能 confirm 或 cancel ,这就是业务悬挂(应当阻止执行空回滚后的 try 操作,避免悬挂)。
-
举例


7、SAGA模式

TCC模式的“简化版”,牺牲了一定的安全性,存在数据“脏读”风险
Saga模式在实际中很少被运用
-
简介:
Saga模式是 Seata 提供的长事务解决方案,具体分为两个阶段:
- 一阶段:直接提交本地事务
- 二阶段:成功则什么也不做,失败则通过编写补偿业务回滚
-
优点:
- 类似 TCC,但不用编写 TCC 中 3 个阶段,实现简单
- 事务参与者可以基于事件驱动实现异步调用,吞吐量高
- 无锁,一阶段直接提交事务,性能好
-
缺点:
- 没有锁与事务隔离性,存在数据“脏写”情况
- 软状态持续的时间不确定,时效性较差
十三、分布式缓存 Redis
1、简介
-
单点 Redis 存在问题(附解决方案):
- 数据易丢失:设置持久化,将部分数据由内存转移至外存
- 并发能力弱:搭建主从集群,实现读写分离
- 故障恢复能力弱:利用 Redis 哨兵,实现健康监测与自动恢复
- 存储能力弱:搭建分片集群,利用插槽机制实现动态扩容
-
下面将根据以上 4 个问题实现解决方案。
-
Docker 安装 Redis
- 新建配置文件
redis.conf(必须设置密码,防止漏洞攻击)与存放目录 - Docker 启动 Redis
- 本机测试
mkdir -p /myredis/conf/ vim /myredis/conf/redis.confrequirepass 密码docker run -d\ -v /myredis/conf:/usr/local/etc/redis \ --name myredis \ -p 6379:6379 \ redis \ redis-server /usr/local/etc/redis/redis.confredis-cli -h 175.178.20.191 -p 6379 # 回车后 auth 密码 - 新建配置文件
2、Redis持久化
一、RDB
-
Redis Database Backup file:Redis数据备份文件,也叫“Redis数据快照”。简单来说就是把内存中的所有数据都记录到磁盘中,当发生故障重启时,从磁盘读取快照恢复数据。
-
快照文件称为 RDB 文件,默认保存在当前运行目录,我们由两种生成方式:
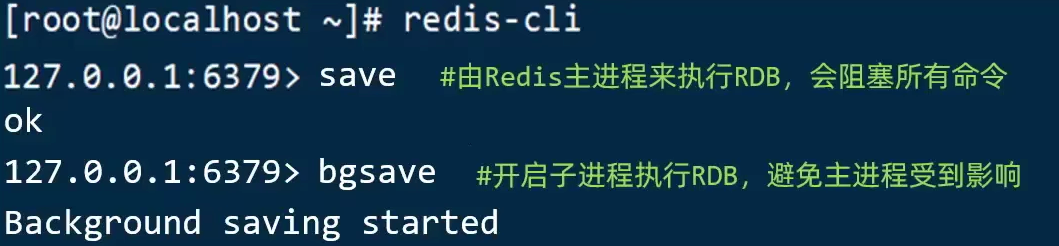
另外:Redis在停机时默认会自动执行一次 RDB。

二、AOF
3、Redis主从
4、Redis哨兵
5、Redis分片集群
十四、分布式消息 RabbitMQ
1、简介
- 简介
- 消费可靠性问题:如何确保发送的消息至少被消费一次
- 延迟消息问题:如何实现消息的延迟投递
- 消息堆积问题:如何解决消息堆积,无法消费的问题
- 高可用问题:如何避免单点的 MQ 故障而导致的不可用问题
- 后续章节
- 消息可靠性
- 死信交换机(死亡信息的交换机)
- 懒惰队列
- MQ集群
2、可靠性问题
一、简介
-
存在 3 种消息丢失类型
- 发送时丢失
- 生产者发送的消息未到达exchange
- 消息到达 exchange 后未到达 queue
- MQ 宕机,queue将消息丢失
- consumer接收到消息后未消费就宕机
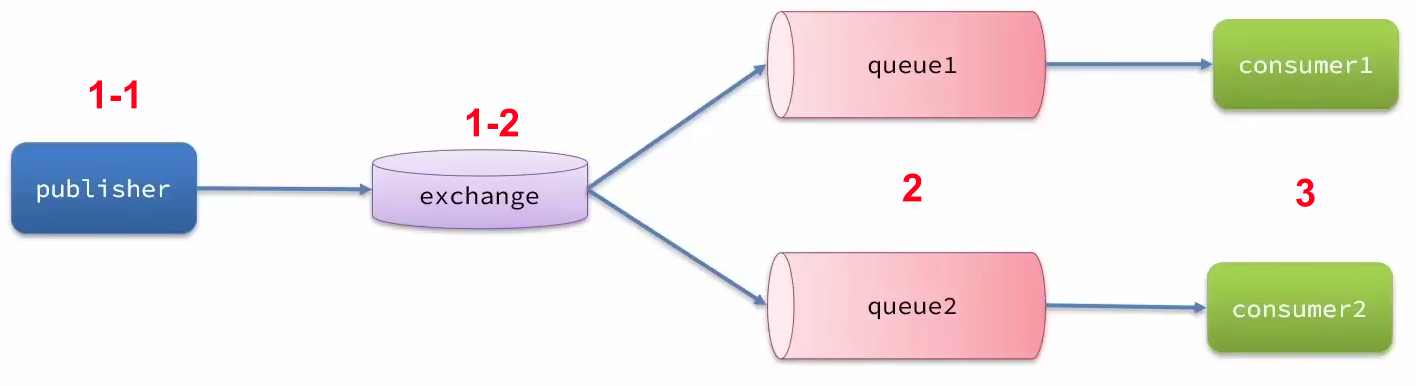
- 发送时丢失
-
【注意】:
在确认机制发送消息时,需要给每个消息设置全局唯一的 id,用以区分不同的消息,避免 ack 冲突。
二、生产者确认机制
-
简介
RabbitMQ 提供了
publisher confirm机制来避免消息在发送到 MQ 过程中丢失。即消息在发送到 MQ 后,会返回结果给发送方,表示消息投递状态。有两种结果:publisher-confirm,发送者确认- 消息成功投递倒交换机,返回
ack - 消息未投递到交换机,返回
nack - 消息发送过程中出现异常,没有收到回执
- 消息成功投递倒交换机,返回
publisher-return,发送者回执- 消息投递到交换机,但是没有路由到队列,返回
ack及路由失败原因
- 消息投递到交换机,但是没有路由到队列,返回

-
实现方式:
- 配置消息发送者
- 消息发送者中编写
publisher-confirm与publisher-return响应代码
-
编写配置文件
spring: rabbitmq: host: 175.178.20.191 port: 5672 username: user password: 123 virtual-host: / # 下面配置为本节新增 RabbitMQ 配置 template: mandatory: true publisher-confirm-type: correlated publisher-returns: true配置说明:
template.mandatory:定义消息路由失败时的策略,true表示调用 ReturnCallback ;false表示丢弃消息。publisher-confirm-type:开启 publisher-confirm ,支持两种类型:- simple:同步等待 confirm 结果,直至超时(性能较差)
- correlated:异步回调,定义 ConfirmCallback ,MQ返回结果时会回调这个ConfirmCallback。
publish-returns:开启 publish-return 功能,定义 ReturnCallback
-
【测试时使用】自建消息队列并绑定路由
-
自建队列
-
- 路由绑定
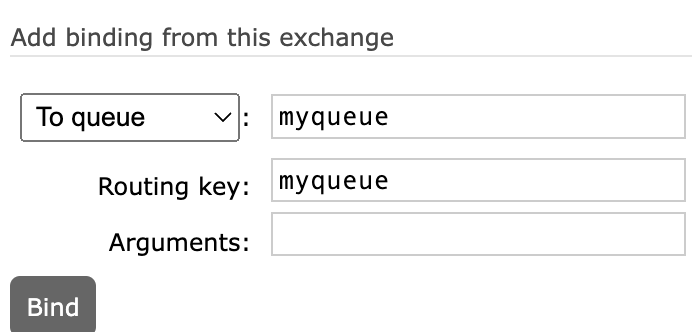
-
【代码编写】

ReturnCallback编写:每个 RabbitTemplete 只能配置一个 ReturnCallback(而 RabbitTemplete 也是全局唯一的),因此我们可以利用ApplicationContextAware进行配置(方式多样,唯一即可)。
@Slf4j @Configuration public class CommonConfig implements ApplicationContextAware { @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { // 获取 RabbitTemplate RabbitTemplate rt = applicationContext.getBean(RabbitTemplate.class); // 设置 ReturnCallback:失败记录日志 // 【注意】:这里可编写消息重发代码,或邮件通知管理员 rt.setReturnCallback((msg, replyCode, replyText, exchange, routingKey) -> { log.info("消息发送到队列失败,应答码{},原因{},交换机{},路由键{},消息{}", replyCode, replyText, exchange, routingKey, msg); }); } }-
ConfirmCallback:每次发送消息时携带(可配置多个),维护其全局唯一 ID 。
@Test public void postMsg() { String msg = "Hello RabbitMQ!"; // 定义异步回调 CorrelationData,并赋予全局唯一 ID(UUID,作辨识) CorrelationData correlation = new CorrelationData(UUID.randomUUID().toString()); // 类似 AJAX,3种结果 correlation.getFuture().addCallback( result -> { if (result.isAck()) { log.debug("消息发送成功投递到交换机,ID:{}", correlation.getId()); } else { log.error("消息投递到交换机失败,ID:{},原因:{}", correlation.getId(), result.getReason()); } }, ex -> { log.error("消息发送失败,ID:{},原因:{}", correlation.getId(), ex.getMessage()); } ); // 发送消息时附加上异步回调 correlation 的定义 rabbitTemplate.convertAndSend("amq.direct", "simple", msg, correlation); // 这里是 Test 测试环境,休眠 2s 等待消息的回执 // 否则 MQ 会收不到消息回执,而认为消息投递到交换机失败 Thread.sleep(2000); }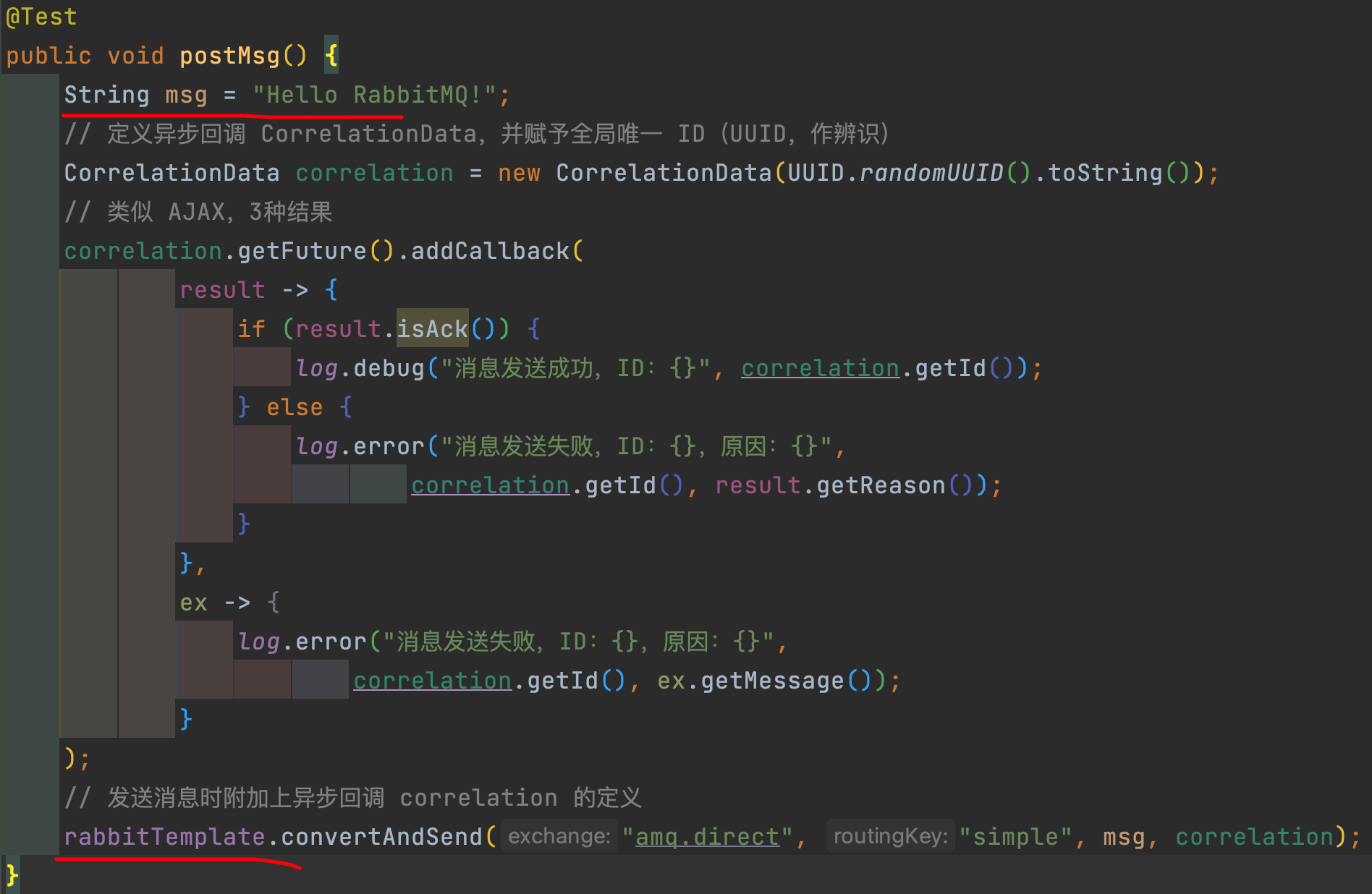
-
测试
-
成功

-
提供错误的路由地址
rabbitTemplate.convertAndSend("error.amq.direct", "simple", msg, correlation);
-
提供错误的队列名
rabbitTemplate.convertAndSend("amq.direct", "error.simple", msg, correlation);
-
三、消息持久化
SpringAMQP 规范定义路由、队列以及消息的创建默认都是
durable 持久化的。
-
简介:MQ 默认内存存储消息,开启持久化功能可以避免缓存在 MQ 中的消息丢失。
-
类型分类
durable:持久化transient:暂时性的
-
持久化(代码创建版)
以下都是默认持久化的,如果需要暂时性的配置再更改即可
- 交换机持久化
@Bean public DirectExchange simpleExchange(){ // 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否删除 return new DirectExchange("simple.direct",true,false); // return new DirectExchange("simple.direct",false,false); }- 队列持久化
@Bean public Queue simpleQueue(){ return QueueBuilder.durable("simple.queue").build(); // return QueueBuilder.nonDurable("simple.queue").build(); }- 消息持久化
Message message = MessageBuilder.withBody("msg".getBytes("UTF-8")) .setDeliveryMode(MessageDeliveryMode.PERSISTENT) // .setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT) .build(); rabbitTemplate.convertAndSend(message); -
持久化(图形界面版):
- 交换机与队列:勾选 durable 就行
- 消息:选择
Persistent(代号2)

-
如何查看某条消息是否属于“持久化消息”?
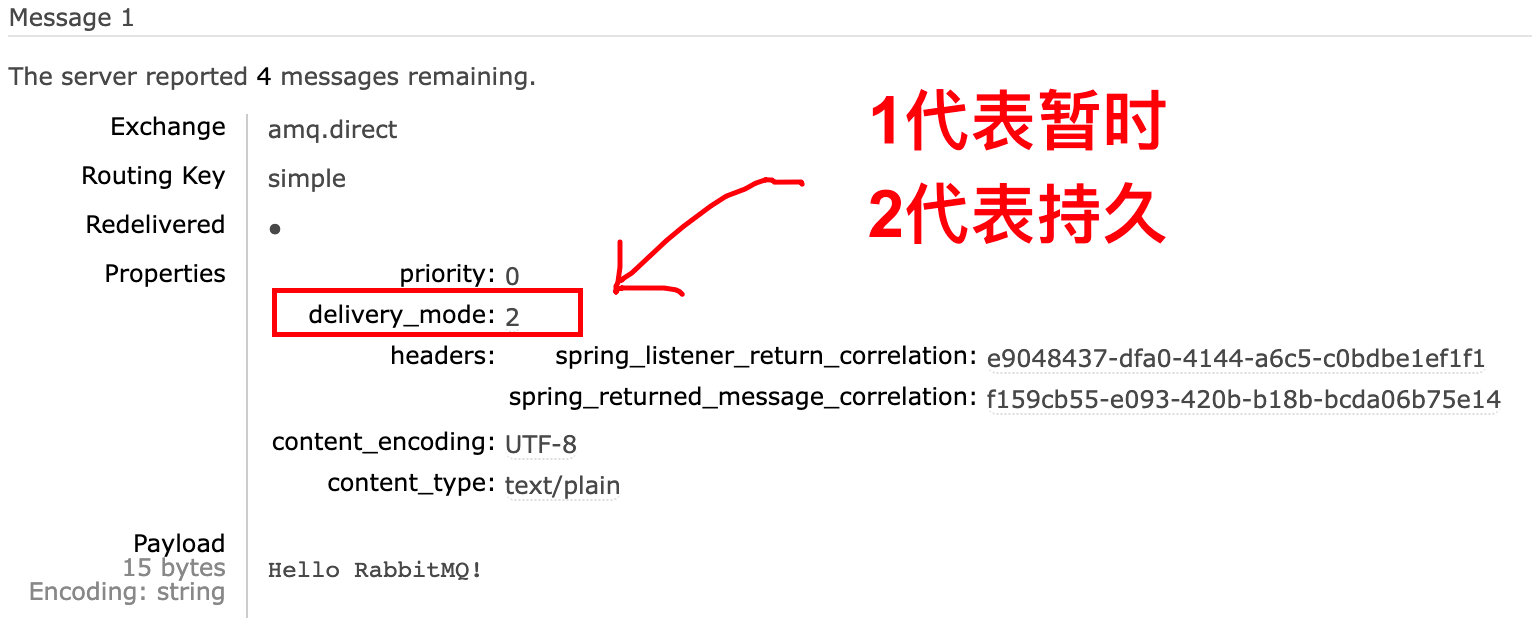
四、消费者消息确认
-
RabbitMQ 支持消费者确认机制,即消费者在处理完信息后向MQ发送回执,MQ收到回执之后才会正式删除该消息。
-
SpringAMQP 可以配置 3 种【确认模式】:
消息接收方中配置
- manual:手动 ack,需要在业务代码结束后,调用 API 发送 ack。
- auto(默认):自动 ack,由 Spring 监测消费者是否发生异常,没有异常返回 ack,否则返回 nack。
- none:关闭 ack,MQ只负责将消息转发出去然后删除,不负责验证。
spring: rabbitmq: host: 175.178.20.191 port: 5672 username: user password: 123 virtual-host: / listener: simple: prefetch: 1 # 配置消息确认机制 acknowledge-mode: auto -
【注意】:当确认模式为 “auto” (而且就是这种方式),没有配置【失败重试模式】时,生产者的消息会一直处于“悬挂”状态(即每次都没有被真正消费),消费者会无限循环的从生产者获取消息,造成严重的资源空转浪费。

-
【失败重试模式】设置:
注意
initial-interval规定的是第一次立即读取失败后的等待时间,并不是第一次读取前的等待时间!需理。spring: rabbitmq: host: 175.178.20.191 port: 5672 username: user password: 123 virtual-host: / listener: simple: prefetch: 1 acknowledge-mode: auto # 设置【失败重试模式】 retry: enabled: true initial-interval: 1000 # 第一次立即读取,第二次(即初始等待时长)为 1s multiplier: 2 # 下次等待时长倍数,下次等待时长=上次等待时长 * 等待时长倍数 max-attempts: 3 # 最大重试次数 max-interval: 60000 # 最大等待时间间隔(我这可不设) stateless: true # true表无状态(默认),false表有状态(业务包含事务时需设) -
在上述设置情境,消息一旦达到重试次数的限制后,即被丢弃。然而有时候我们却并不想直接把消息丢弃,而是想把它保存下来(例如用日志的形式),这时候就需要更改**【消费者失败信息处理策略】**,我们有 3 种形式:
实际就是覆盖 Spring 默认的 Bean:
MessageRecoverer(是接口)- RejectAndDontRequeueRecoverer(默认):重试耗尽后,直接 reject,丢弃消息。
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回 nack,消息重新入队。
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机。
我们以实现第 3 种方式为例:
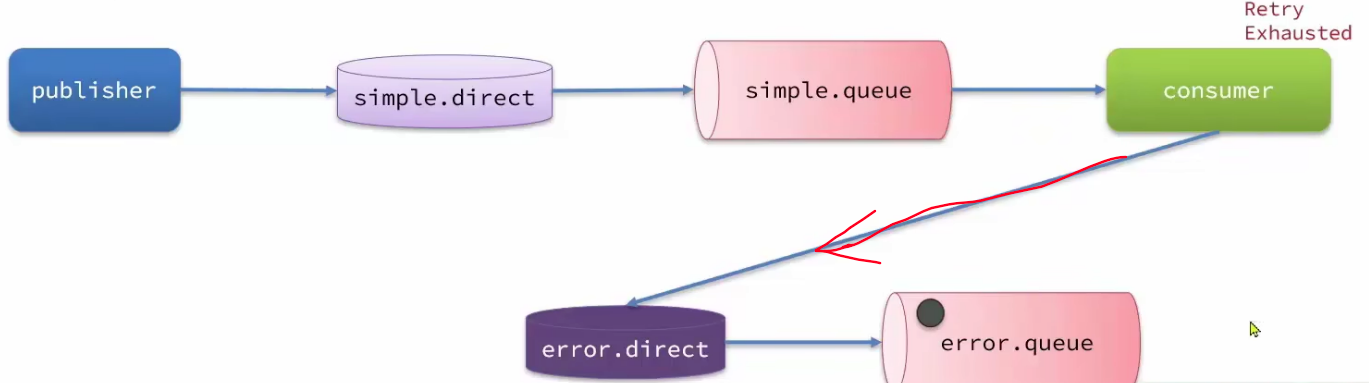
代码创建负责处理“已经死亡的信息”的交换机、队列,并绑定两者
@Configuration
public class CommonConfig {
@Bean
public DirectExchange errorExchange() {
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue() {
return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding() {
return BindingBuilder.bind(errorQueue())
.to(errorExchange())
.with("error");
}
}
定义RepublishMessageRecoverer(即覆盖 Spring 默认的 Bean):
@Autowired
RabbitTemplate rabbitTemplate;
@Bean
public MessageRecoverer RepublishMessageRecoverer() {
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}

3、死信交换机
一、简介
-
概念理解:
- 死信:当一个队列中的消息满足以下情况之一事时,便可以称为死信
- 消费者使用 basic.reject 或 basic.nack 声明消费失败,消息的 requeue 参数设置为 false
- 消息过期,无人消费
- 队列消息堆积过多,最早的消息被抛弃
- 死信交换机:如果一个队列配置了
dead-letter-exchange属性,并且指定了一个交换机,那么队列中的所有死信就会投递到这个交换机中,而这个交换机也被成为“死信交换机”。
- 死信:当一个队列中的消息满足以下情况之一事时,便可以称为死信
-
【死信交换机】与上节的【消费者失败信息处理策略】区别:
- 死信交换机由**“队列”**负责转发,而消费者失败信息处理策略由消费者负责转发
- 死信交换机可以实现的功能更加丰富
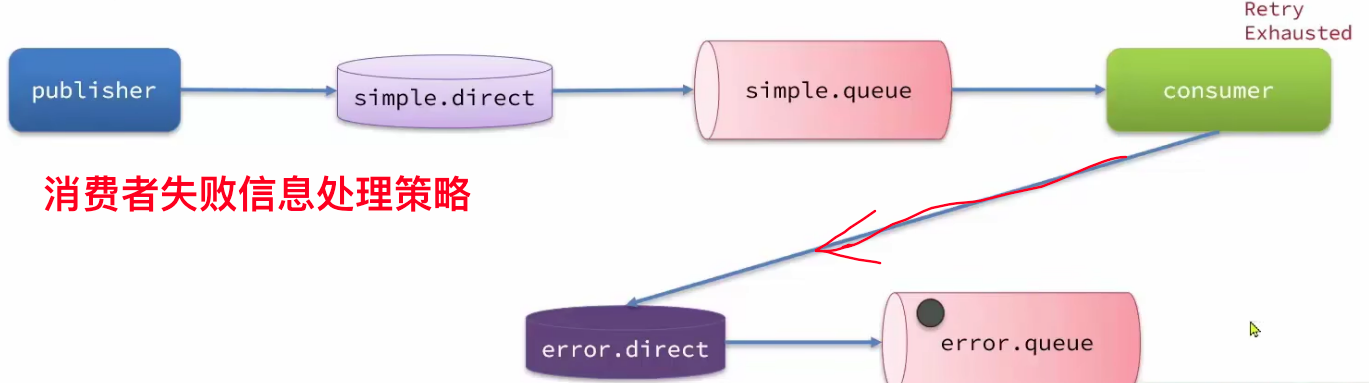
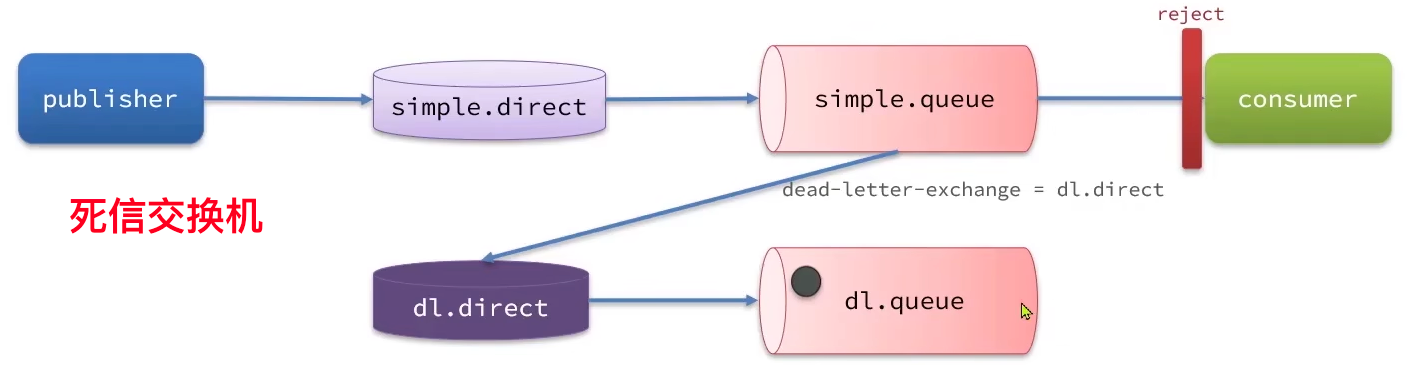
二、TTL
Time To Live,存活时间(默认未设置)
-
如果一个队列中的消息在 TTL 结束时仍未被消费,则会变为“死信”,具体可以分为 2 种情况:
- 消息所在的队列设置了存活时间
- 消息本身设置了存活时间
**注意:**如果两者同时设置了,则以【时间短的】为准!
-
应用
- 设置消息的超时时间
- 延迟消费者对消息的接收
-
简单实现:设置超时时间 与 延迟消费者对消息的接收
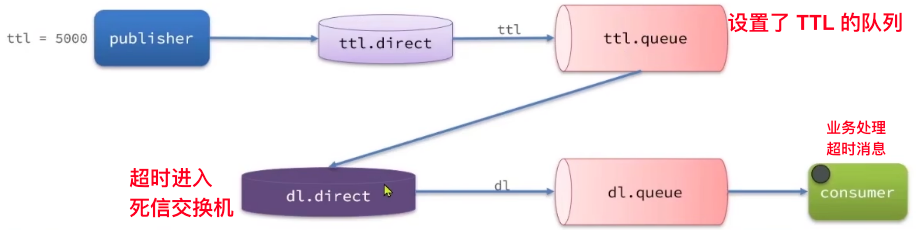
- TTL队列:超时时长为 10s
@Bean public DirectExchange ttlExchange() { return new DirectExchange("ttl.direct"); } @Bean public Queue ttlQueue() { return QueueBuilder.durable("ttl.queue") .ttl(10000) // 指定超时后转发的“死信交换机”与其 routingKey .deadLetterExchange("dl.direct") .deadLetterRoutingKey("dl") .build(); } @Bean public Binding ttlBinding() { return BindingBuilder.bind(ttlQueue()) .to(ttlExchange()) .with("ttl"); }- 对应“死信交换机”的创建(注解方式),以及消费者监听
@RabbitListener(bindings = @QueueBinding( value = @Queue("dl.queue"), exchange = @Exchange("dl.direct"), key = "dl" )) public void listenDlQueue(String msg){ log.info("接收到 dl.queue 的延迟消息:{}",msg); }- 测试:发送消息,TTL设置为 5s
@Test public void testTTLMsg( ) throws UnsupportedEncodingException { Message msg =MessageBuilder .withBody("hello ttl".getBytes("UTF-8")) .setExpiration("5000") .build(); // 消息 ID,需要封装到 CorrelationData 中 CorrelationData correlation = new CorrelationData(UUID.randomUUID().toString()); // 发送消息 rabbitTemplate.convertAndSend("ttl.direct","ttl",msg,correlation); }
三、延迟队列
-
上节利用 TTL 结合死信交换机的方式虽然能实现消息的延迟接收,但是我们可以有更加简便的办法。
-
延迟队列的使用场景:
- 延迟发送短信
- 用户下单,若在规定时间内未完成付款则取消订单
- 预约工作会议,20分钟后通知所有参会人员
-
“延迟插件”原理:
对官方原生的路由 Exchange 做了功能升级,衍生出 DelayExchange ,其会将接收到的消息暂存在内存中直至“过期”(而官方的 Exchange 是无法存储消息的),过期后将消息投递到队列中。
-
安装“延迟队列”插件
前提:安装 RabbitMQ 时需创建“配置”插件目录容器卷
插件全称:
rabbitmq_delayed_message_exchange-3.11.1.ez- RabbitMQ有一个官方的插件社区,进入查找
DelayExchange插件,点击 release 进入 GitHub 下载 - 查看 RabbitMQ 插件容器卷的挂载地址,将插件直接上传到该目录(目录自带许多官方插件)
- 进入MQ容器内部,执行指令开启插件
- 重启容器
docker volume inspect 容器卷名 - RabbitMQ有一个官方的插件社区,进入查找
docker exec -it 容器名 bash
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
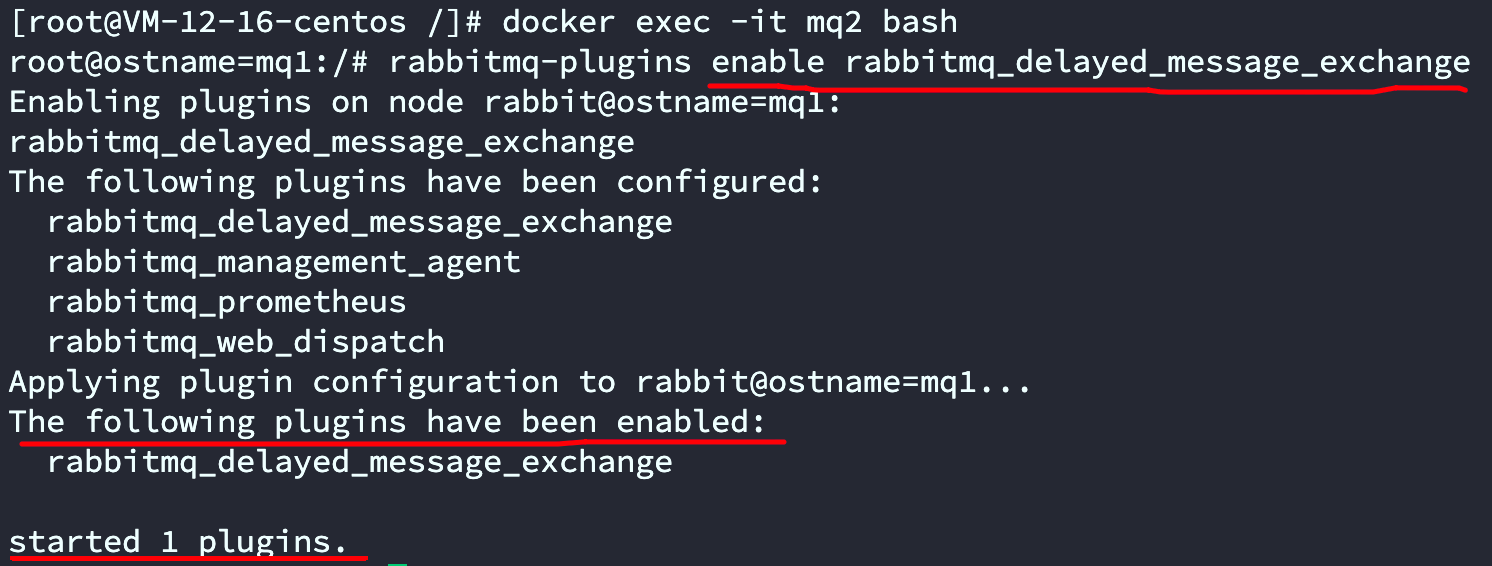
docker restart 容器名
插件安装成功之后,我们就可以在发送消息时直接指定消息的延迟时间,而无需其他繁杂配置。
-
【延迟队列实现】
- 图形界面版:先创建 DelayExchange,绑定队列,后续将消息转发至队列时,只需要增加请求头
x-delay并附上时间数值即可。
- 图形界面版:先创建 DelayExchange,绑定队列,后续将消息转发至队列时,只需要增加请求头
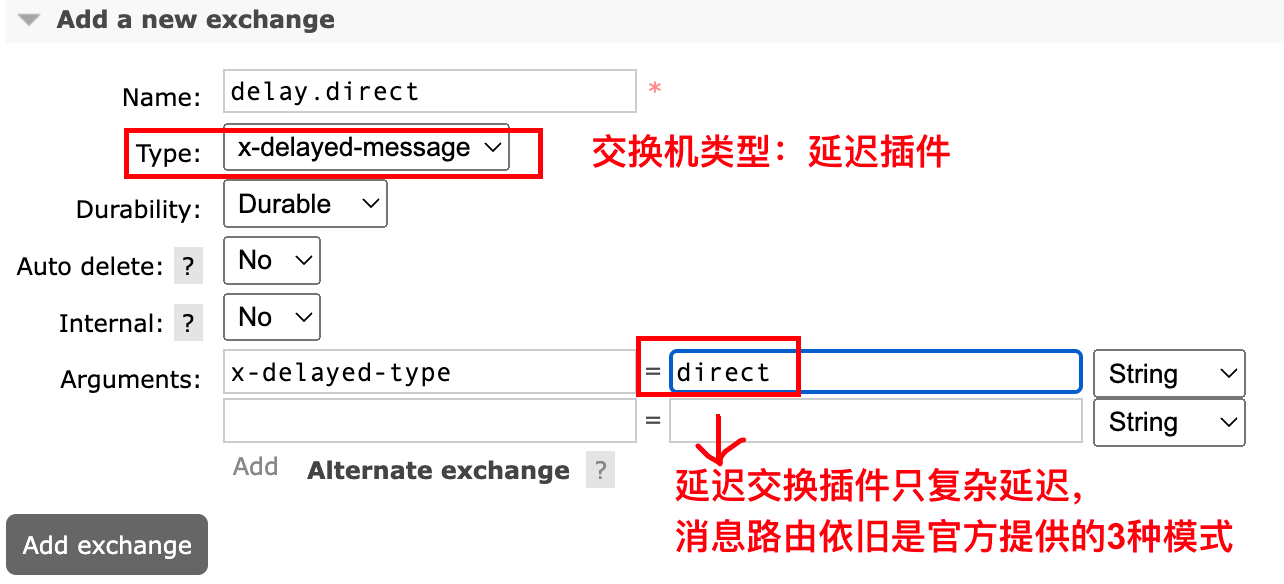
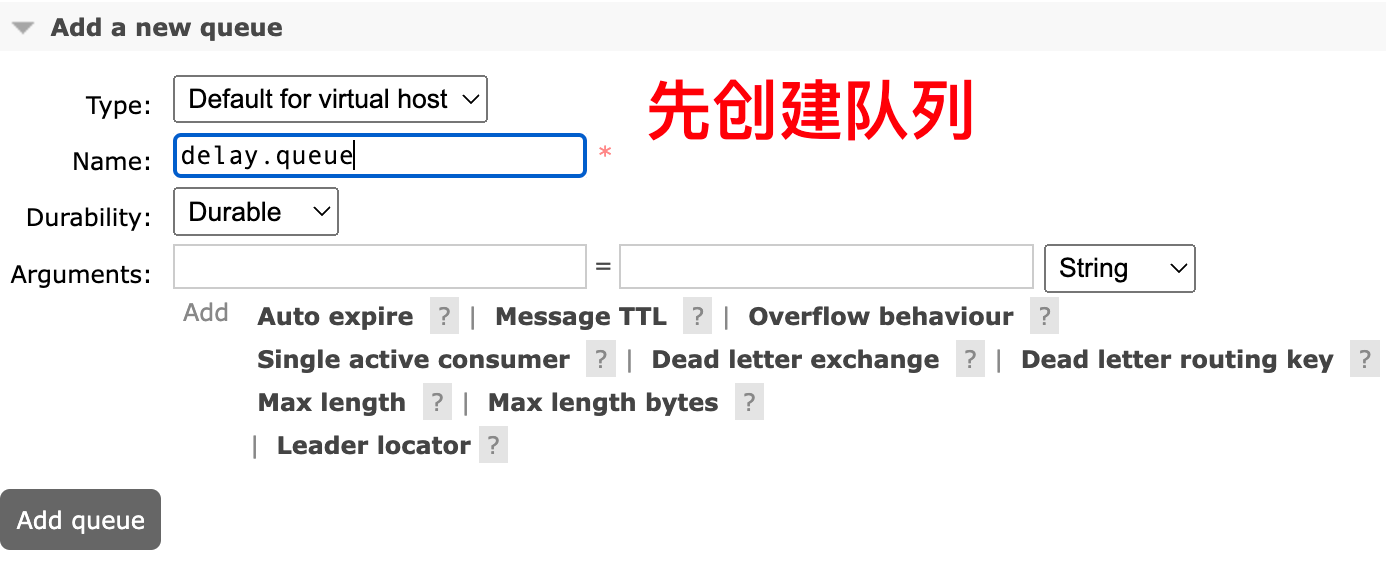
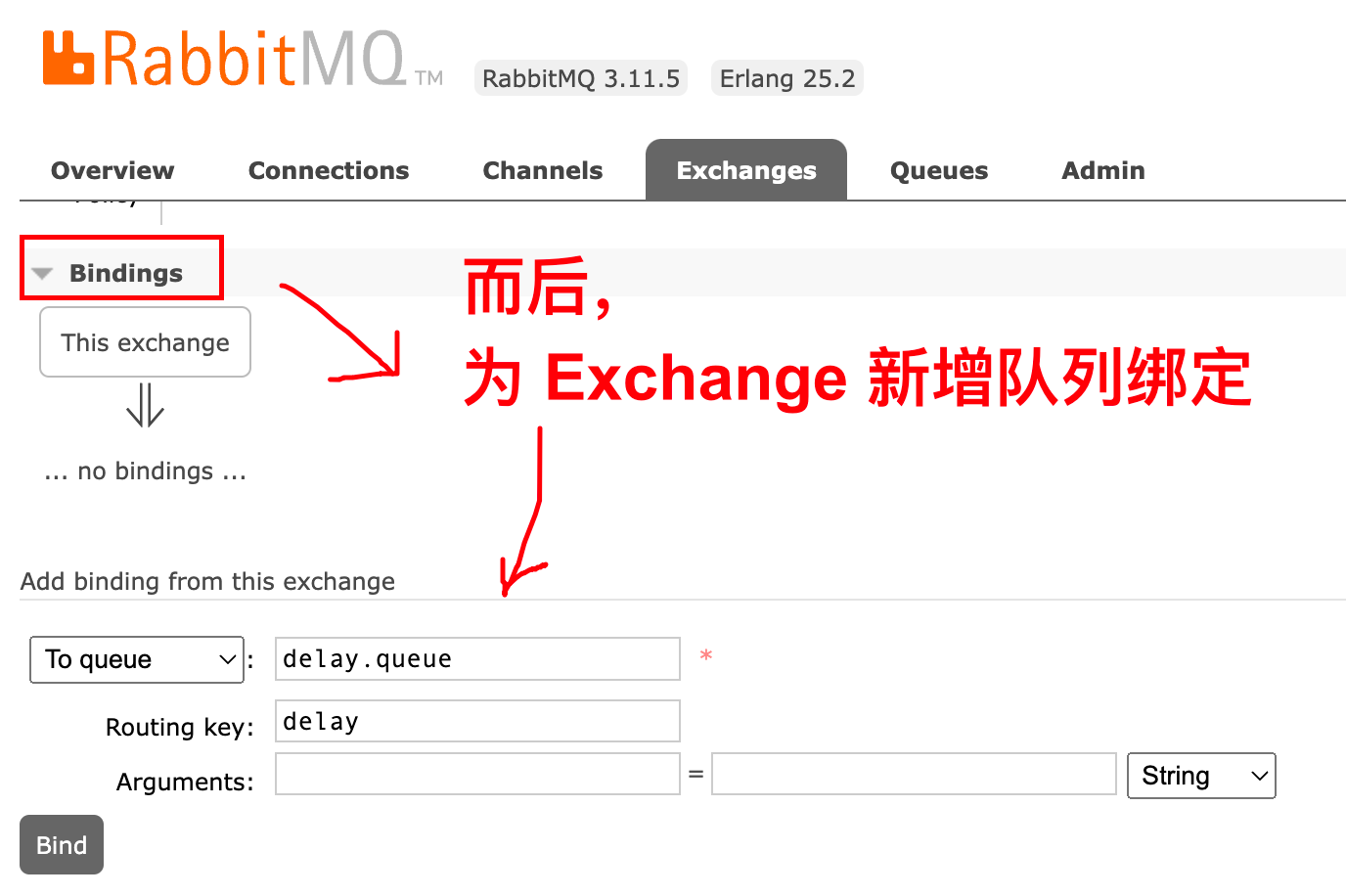
向 DelayExchange 发送消息
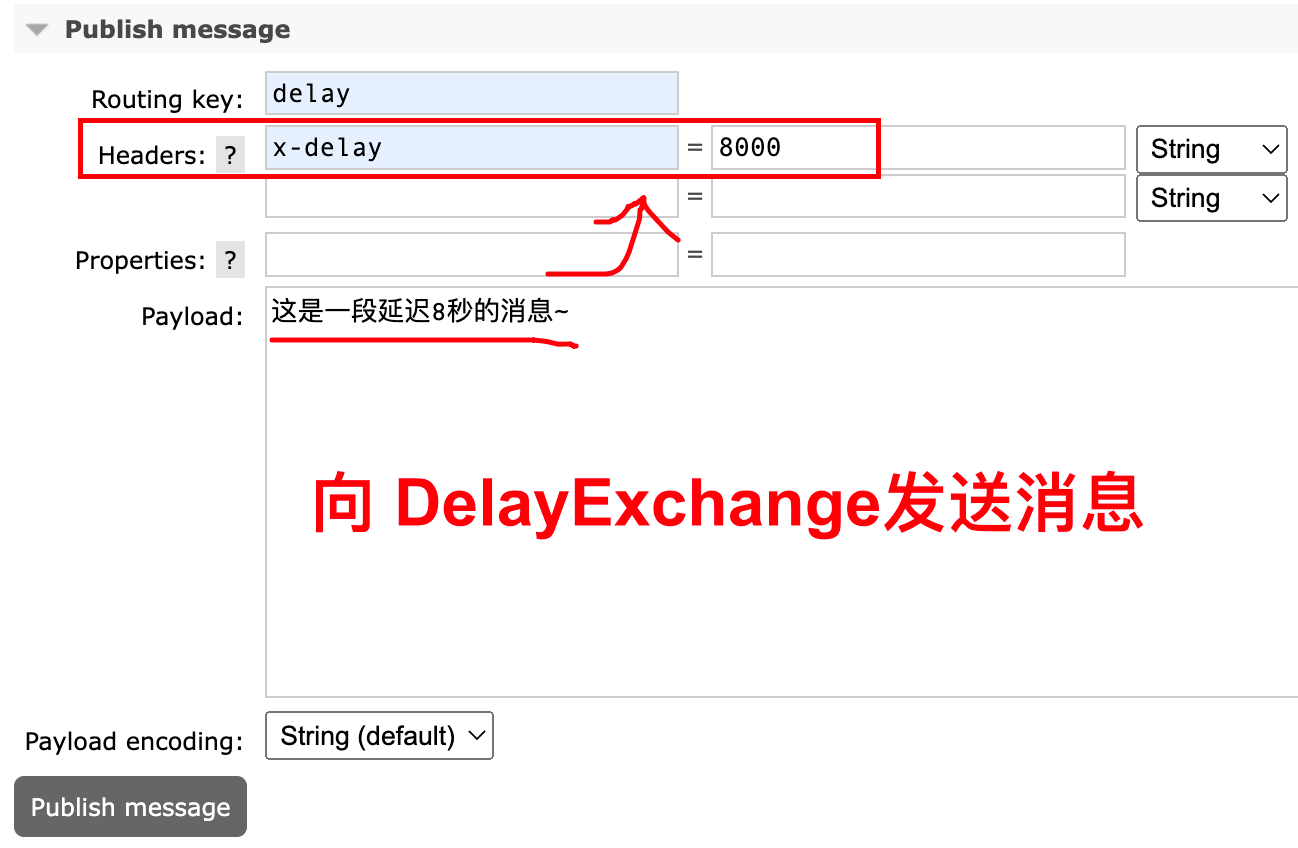
- 代码版:基于注解,基于 Bean 两种形式
@RabbitListener(bindings = @QueueBinding(
value = @Queue("delay.queue"),
// delayed 属性为 true
exchange = @Exchange(name = "delay.direct",delayed ="true" ),
key = "delay"
))
public void delayQueue(String msg){
log.info("接收到 dl.queue 的延迟消息:{}",msg);
}
@Bean
public DirectExchange delayExchange() {
return ExchangeBuilder.directExchange("delay.direct")
.delayed() // 设置则属性为 true
.build();
}
// 这里代码只负责创建,后续自行绑定队列
发送消息样板:添加请求头x-delay : 时间(单位毫秒)即可。
Message msg =MessageBuilder
.withBody("消息体.getBytes("UTF-8"))
.setHeader("x-delay",5000) // 设置延迟时间
.build();
// 消息 ID,需要封装到 CorrelationData 中
CorrelationData correlation = new CorrelationData(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend("delay.direct","delay",msg,correlation);
4、消息堆积及惰性队列
-
消息堆积问题:
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直至达到上限;这时最早接收到的消息很有可能就会成为“死信”。
-
解决消息堆积的 3 种思路:
- 增加消费者数量
- 在消费者内部开启线程池加快消息的处理速度
- 扩大队列容积,提高堆积上限
-
惰性队列
从 RabbitMQ 3.6.0 开始,新增 Lazy Queues (惰性队列)概念。
- Queue 接收到消息后直接将其存储至磁盘,而非内存
- 当 消费者 要 消费 消息时, Queue 才会将消息加载到内存
- 支持数以百万计的消息存储(因为是在磁盘中而不是内存)
-
设置惰性队列的 2 种方式:
- 未声明的队列:在声明队列时,指定
x-queue-mode属性为lazy
@RabbitListener(bindings = @QueueBinding( // 设置为“惰性队列” value = @Queue(name="dl.queue", arguments=@Argument(name="x-queue-mode",value="lazy")), exchange = @Exchange("dl.direct"), key = "dl" )) public void listenDlQueue(String msg){ log.info("接收到 dl.queue 的延迟消息:{}",msg); }@Beam public void lazyQueue(){ return QueueBuilder.durable("lazy.queue").lazy().build(;) }- 已声明的队列:修改队列属性值
queue-mode为lazy
# 正则表达式匹配,--apply-to queues 令所有匹配的队列属性值均修改 rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues - 未声明的队列:在声明队列时,指定
5、MQ集群
伪集群搭建,后续完善
注意!集群是指的是
Queue队列集群!
一、集群分类
RabbitMQ由 Erland语言(面向并发) 编写,天然支持集群模式,传统的 RabbitMQ 支持 2种集群模式:
- 普通镜像(分布式集群)
- 镜像集群(主从备份,提升数据安全性)
镜像集群虽然支持集群,但是主从同步并不是强一致的,在某些情况下可能存在数据丢失的风险。因此官方在 RabbitMQ 3.8 版本之后推出了新的集群模式仲裁队列来代替镜像集群,其底层使用 Raft 协议确保主从数据一致。
二、普通集群
-
简介:Classis Cluster,普通集群、经典集群。
-
特性
- 集群不进行数据同步
- 队列间元数据信息互相拥有。所有队列均知道其他队列的存在,并且拥有它们的详情信息。
- 队列间消息数据互通(不是互相拥有)。例如我们拥有 2 个队列 MQ1 和 MQ2 ,想要的数据在 MQ2 中,但是我们却连接到了 MQ1 中,于是 MQ1 就会去 MQ2 中拉取消息然后再返回数据给你;如果此时 MQ2 宕机,则无法获取消息。
下面为 黑马程序员 提供的“在相同 Docker 环境”的伪集群搭建教程
-
我们先来看普通模式集群,我们的计划部署3节点的mq集群:
主机名 控制台端口 amqp通信端口 mq1 8081 —> 15672 8071 —> 5672 mq2 8082 —> 15672 8072 —> 5672 mq3 8083 —> 15672 8073 —> 5672 集群中的节点标示默认都是:
rabbit@[hostname],因此以上三个节点的名称分别为:-
rabbit@mq1
-
rabbit@mq2
-
rabbit@mq3
-
-
获取cookie
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 cookie 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang cookie。cookie 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 cookie。实例之间也需要它来相互通信。
我们先在之前启动的mq容器中获取一个cookie值,作为集群的cookie。执行下面的命令:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie可以看到cookie值如下:
FXZMCVGLBIXZCDEMMVZQ接下来,停止并删除当前的mq容器,我们重新搭建集群。
docker rm -f mq -
准备集群配置
在/tmp目录新建一个配置文件 rabbitmq.conf:
vim /tmp/rabbitmq.conf文件内容如下:
loopback_users.guest = false listeners.tcp.default = 5672 cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config cluster_formation.classic_config.nodes.1 = rabbit@mq1 cluster_formation.classic_config.nodes.2 = rabbit@mq2 cluster_formation.classic_config.nodes.3 = rabbit@mq3再创建一个文件,记录cookie
# 写入cookie echo "FXZMCVGLBIXZCDEMMVZQ" > /tmp/.erlang.cookie # 修改cookie文件的权限 chmod 600 .erlang.cookieecho "LNFBFJDGJUGVBTXDJJYE" > .erlang.cookie准备三个目录,mq1、mq2、mq3:
cd /tmp # 创建目录 mkdir mq1 mq2 mq3然后拷贝rabbitmq.conf、cookie文件到mq1、mq2、mq3:
# 进入/tmp cd /tmp # 拷贝 cp rabbitmq.conf mq1 cp rabbitmq.conf mq2 cp rabbitmq.conf mq3 cp .erlang.cookie mq1 cp .erlang.cookie mq2 cp .erlang.cookie mq3 -
启动集群
创建一个网络:
docker network create mq-net运行命令
docker run -d --net mq-net \ -v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \ -v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \ -e RABBITMQ_DEFAULT_USER=itcast \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq1 \ --hostname mq1 \ -p 8071:5672 \ -p 8081:15672 \ rabbitmq:3.8-managementdocker run -d --net mq-net \ -v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \ -v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \ -e RABBITMQ_DEFAULT_USER=itcast \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq2 \ --hostname mq2 \ -p 8072:5672 \ -p 8082:15672 \ rabbitmq:3.8-managementdocker run -d --net mq-net \ -v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \ -v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \ -e RABBITMQ_DEFAULT_USER=itcast \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq3 \ --hostname mq3 \ -p 8073:5672 \ -p 8083:15672 \ rabbitmq:3.8-management访问网页,搭建成功

选择节点添加队列
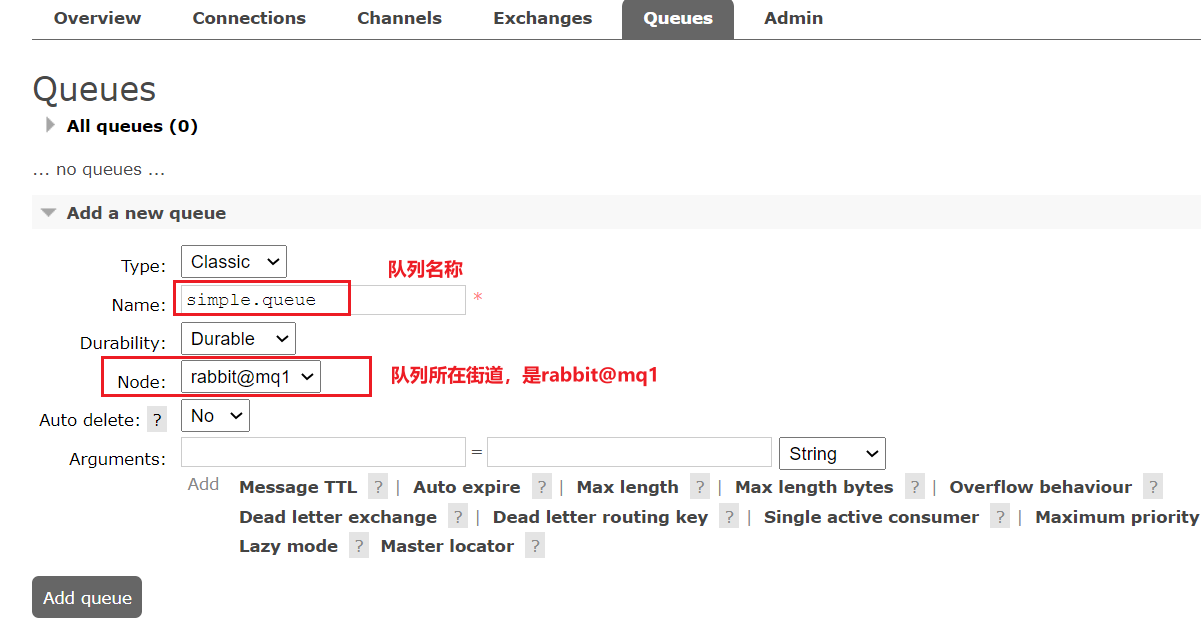
三、镜像集群
-
特性:
- 交换机、队列、队列中的消息会在各个镜像节点之间同步备份。
- 创建队列的节点称为【主节点】,备份的节点称为【镜像节点】。
- 一个队列的主节点可能是其他队列的镜像节点
- 所有的原始操作都会先由主节点完成,然后同步给镜像节点
- 主节点宕机后,镜像节点会成为新的主节点
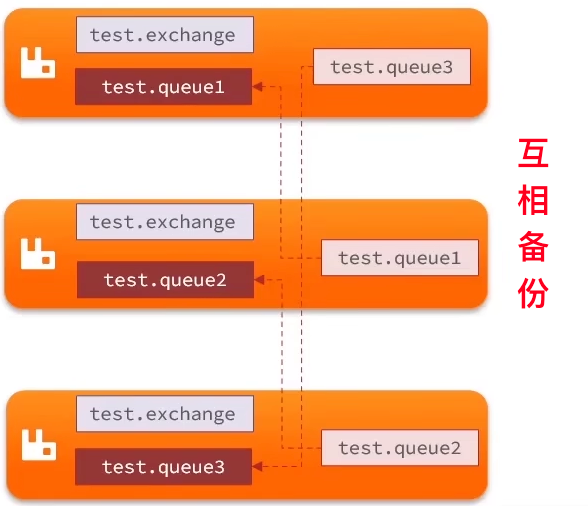
-
总结如下:
- 镜像队列结构是一主多从(从就是镜像)
- 镜像节点仅仅起到备份数据作用
- 所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主(如果在主从同步完成前,主就已经宕机,可能出现数据丢失)
- 不具备负载均衡功能,因为所有操作都会有主节点完成(但是不同队列,其主节点可以不同,可以利用这个提高吞吐量)
-
镜像模式的配置
镜像模式的配置有3种模式:
ha-mode ha-params 效果 准确模式exactly 队列的副本量count 集群中队列副本(主服务器和镜像服务器之和)的数量。count如果为1意味着单个副本:即队列主节点。count值为2表示2个副本:1个队列主和1个队列镜像。换句话说:count = 镜像数量 + 1。如果群集中的节点数少于count,则该队列将镜像到所有节点。如果有集群总数大于count+1,并且包含镜像的节点出现故障,则将在另一个节点上创建一个新的镜像。 all (none) 队列在群集中的所有节点之间进行镜像。队列将镜像到任何新加入的节点。镜像到所有节点将对所有群集节点施加额外的压力,包括网络I / O,磁盘I / O和磁盘空间使用情况。推荐使用exactly,设置副本数为(N / 2 +1)。 nodes node names 指定队列创建到哪些节点,如果指定的节点全部不存在,则会出现异常。如果指定的节点在集群中存在,但是暂时不可用,会创建节点到当前客户端连接到的节点。 这里我们以rabbitmqctl命令作为案例来讲解配置语法。
语法示例:
-
exactly模式
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'rabbitmqctl set_policy:固定写法ha-two:策略名称,自定义"^two\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以two.开头的队列名称'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}': 策略内容"ha-mode":"exactly":策略模式,此处是exactly模式,指定副本数量"ha-params":2:策略参数,这里是2,就是副本数量为2,1主1镜像"ha-sync-mode":"automatic":同步策略,默认是manual,即新加入的镜像节点不会同步旧的消息。如果设置为automatic,则新加入的镜像节点会把主节点中所有消息都同步,会带来额外的网络开销
-
all模式
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'ha-all:策略名称,自定义"^all\.":匹配所有以all.开头的队列名'{"ha-mode":"all"}':策略内容"ha-mode":"all":策略模式,此处是all模式,即所有节点都会称为镜像节点
-
nodes模式
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'rabbitmqctl set_policy:固定写法ha-nodes:策略名称,自定义"^nodes\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以nodes.开头的队列名称'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}': 策略内容"ha-mode":"nodes":策略模式,此处是nodes模式"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略参数,这里指定副本所在节点名称
-
测试
我们使用exactly模式的镜像,因为集群节点数量为3,因此镜像数量就设置为2.
运行下面的命令:
docker exec -it mq1 rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'下面,我们创建一个新的队列:

四、仲裁队列Quorum
-
Quorum:仲裁,3.8版本之后出现的功能,约定大于配置,目的在于取代镜像集群。
-
默认count值为5,即
1主4从。 -
添加仲裁队列
在任意控制台添加一个队列,一定要选择队列类型为Quorum类型。

在任意控制台查看队列:
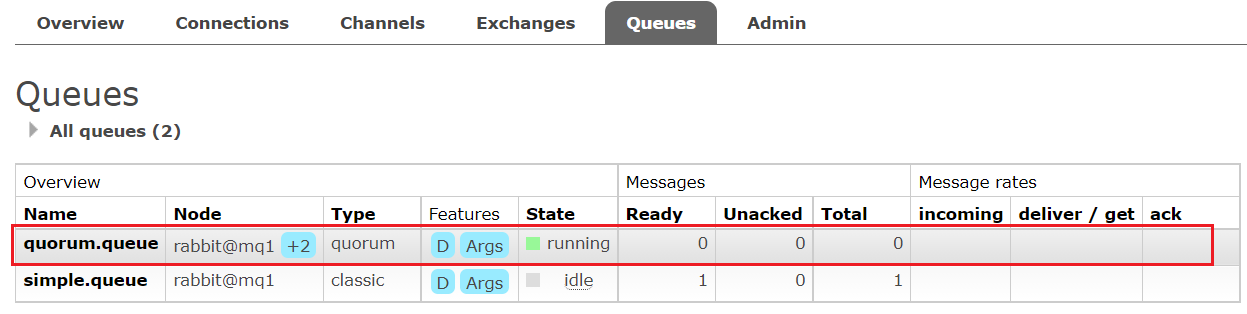
可以看到,仲裁队列的 + 2字样。代表这个队列有2个镜像节点。
因为仲裁队列默认的镜像数为5。如果你的集群有7个节点,那么镜像数肯定是5;而我们集群只有3个节点,因此镜像数量就是3.
五、集群扩容
加入集群
1)启动一个新的MQ容器:
docker run -d --net mq-net \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq4 \
--hostname mq5 \
-p 8074:15672 \
-p 8084:15672 \
rabbitmq:3.8-management
2)进入容器控制台:
docker exec -it mq4 bash
3)停止mq进程
rabbitmqctl stop_app
4)重置RabbitMQ中的数据:
rabbitmqctl reset
5)加入mq1:
rabbitmqctl join_cluster rabbit@mq1
6)再次启动mq进程
rabbitmqctl start_app

增加仲裁队列副本
我们先查看下quorum.queue这个队列目前的副本情况,进入mq1容器:
docker exec -it mq1 bash
执行命令:
rabbitmq-queues quorum_status "quorum.queue"
结果:
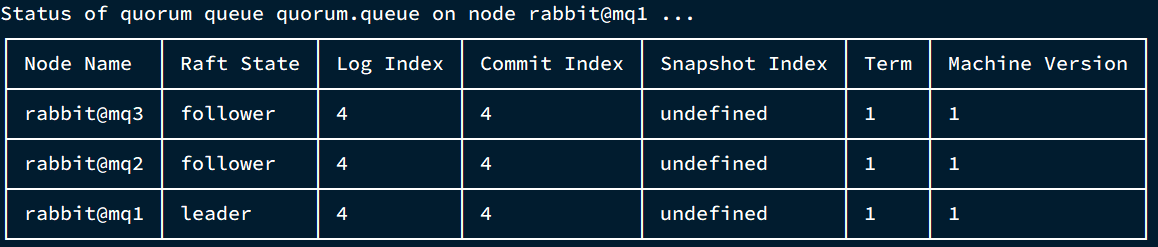
现在,我们让mq4也加入进来:
rabbitmq-queues add_member "quorum.queue" "rabbit@mq4"
结果:

再次查看:
rabbitmq-queues quorum_status "quorum.queue"
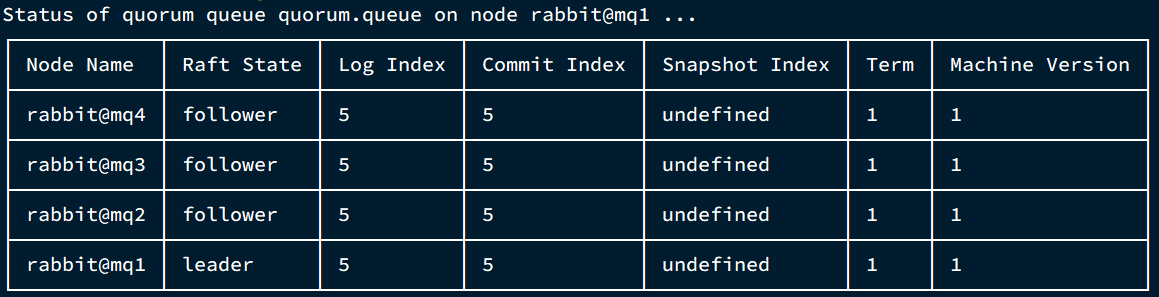
查看控制台,发现quorum.queue的镜像数量也从原来的 +2 变成了 +3:
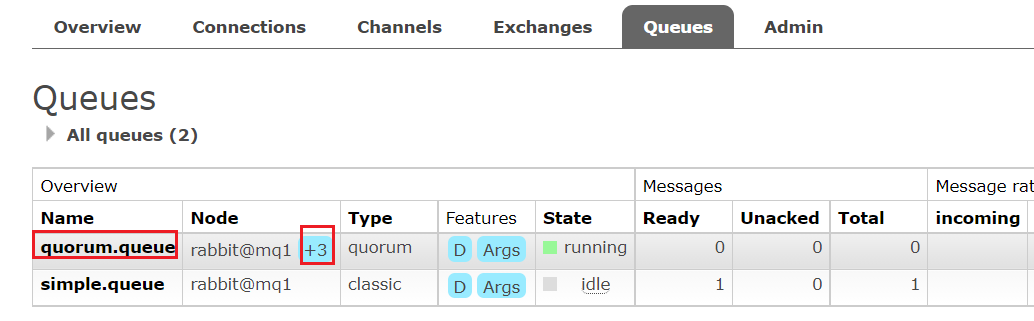
十五、分布式文件系统 MinIO
1、简介
-
简介:
- 文件系统:操作系统用于明确存储设备或分区上的文件的方法和数据结构,如 FAT16、NTFS、ext4、APFS 等。
- 分布式文件系统:也叫“网络文件系统”,是一种允许文件透过网络在多台主机上分享的文件系统,多台文件存储服务器组成集群共同对外提供服务。
-
应用实例:
- 云服务器厂商的 OSS 虚拟存储技术
- 单独微服务组件实现图片上传下载
2、MinIO
开源产品
英文官网:https://min.io|中文官网:https://www.minio.org.cn/
-
MinIO 是什么?
MinIO 是一个非常轻量的服务,可以很简单的和其他应用的结合使用,它兼容亚马逊 S3 云存储服务接口(亚马逊云的 S3 API 接口协议是在全球范围内达到共识的对象存储协议,是世界范围内认可的标准),非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等。我国的企业通常使用阿里云、腾讯云提供的 OSS 云端存储服务,不过对于一些敏感信息,可以“自建 OSS ”。
它一大特点就是轻量,使用简单,功能强大,支持各种平台,单个文件最大 5TB,兼容 Amazon S3接口,提供了 Java、Python、GO等多版本SDK支持。
-
特点:
- Golang编写
- 去中心化:MinIO集群采用去中心化共享架构,每个结点是对等关系,通过 Nginx 可实现负载均衡访问。
- 数据保护:使用
纠错码 erasure code和校验和 checksum保护数据免受硬件故障和数据损坏,即使丢失一半数量(N/2)的硬盘,仍然可以恢复数据。 - 高可用:多节点组成的分布式minio可保证服务的高可用(分布式 Minio 只要有 N/2 节点在线,数据就是安全的,不过需要至少有 N/2+1 个节点才能创建新的对象)
- 一致性保障:所有的 IO 操作中都严格遵循
read-after-write和list-after-write一致性模型
-
纠错码 erasure code 简介
纠删码是一种恢复丢失和损坏数据的数学算法,传输过程中发生错误后能在收端自行发现或纠正的码。为使一种码具有检错或纠错能力,须对原码字增加多余的码元。
Minio 将数据分块冗余的分散存储在各各节点的磁盘上,所有的可用磁盘组成一个集合,上图由8块硬盘组成一个集合,当上传一个文件时会通过纠删码算法计算对文件进行分块存储,除了将文件本身分成4个数据块,还会生成4个校验块,数据块和校验块会分散的存储在这 8 块硬盘上。
使用纠删码的好处是即便丢失一半数量(N/2)的硬盘,仍然可以恢复数据。在上图中,当丢失3个硬盘时,依旧可读可写;当丢失4个硬盘时,只能读不能写;当丢失数量大于一半即 4 个硬盘时,数据无法恢复。
-
纠错码 erasure code 工作流程
当数据对象在MinIO集群中进行存储时,先进行纠删分片,后打散存储在各硬盘上。具体为:
- MinIO自动在集群内生成若干纠删组,每个纠删组包含一组硬盘,其数量通常为4至16块;
- 对数据对象进行分片,默认策略是得到相同数量的数据分片和校验分片;
- 而后通过哈希算法计算出该数据对象对应的纠删组,并将数据和校验分片存储至纠删组内的硬盘上。
-
MinIO 恢复过程:
删除一个目录,稍等片刻删除的目录自动恢复。
-
一些思想:
- 桶内可以创建子目录
- 同一个桶内,对象名不能重复(相同则覆盖)
- 纠错码至少拥有 4 份存储空间
-
Docker安装
- 不使用纠错码:存储的文件在硬盘中不会被拆分,还是文件原来的模样。
docker run \ -p 9000:9000 \ -p 9090:9090 \ -d --restart=always \ -e "MINIO_ACCESS_KEY=minioadmin" \ -e "MINIO_SECRET_KEY=minioadmin" \ -v /home/minio/data:/data \ -v /home/minio/config:/root/.minio \ --name minio \ minio/minio:latest \ server /data --console-address ":9090" -address ":9000"端口
9000/9090,账号密码默认minioadmin。-
使用纠错码(8份):存储的文件被拆分,平均存储在 8 份硬盘。
实测存储
274KB,占用硬盘:67*8+4*16=600KB(其中 4*16 表示目录所占用的存储,即最小块 4KB * 16),当然这里只是大致估算,并不代表最终准确值,有印象即可。
docker run -d \ -p 9001:9001 \ -p 9091:9091 \ -e "MINIO_ACCESS_KEY=minioadmin" \ -e "MINIO_SECRET_KEY=minioadmin" \ -v /home/minio/data1:/data1 \ -v /home/minio/data2:/data2 \ -v /home/minio/data3:/data3 \ -v /home/minio/data4:/data4 \ -v /home/minio/data5:/data5 \ -v /home/minio/data6:/data6 \ -v /home/minio/data7:/data7 \ -v /home/minio/data8:/data8 \ -v /home/minio/config:/root/.minio \ --name minio1 \ minio/minio server /data1 /data2 /data3 /data4 /data5 /data6 /data7 /data8 \ --console-address ":9091" -address ":9001"tree -h \ /home/minio/data1 \ /home/minio/data2 \ /home/minio/data3 \ /home/minio/data4 \ /home/minio/data5 \ /home/minio/data6 \ /home/minio/data7 \ /home/minio/data8
- 创建新用户
设置账号密码及权限
- 创建新群组
- 创建
AccessKey与SecretKey
为用户创建AccessKey与SecretKey(相当于受限的账号密码),用以在其他客户端中声明使用。
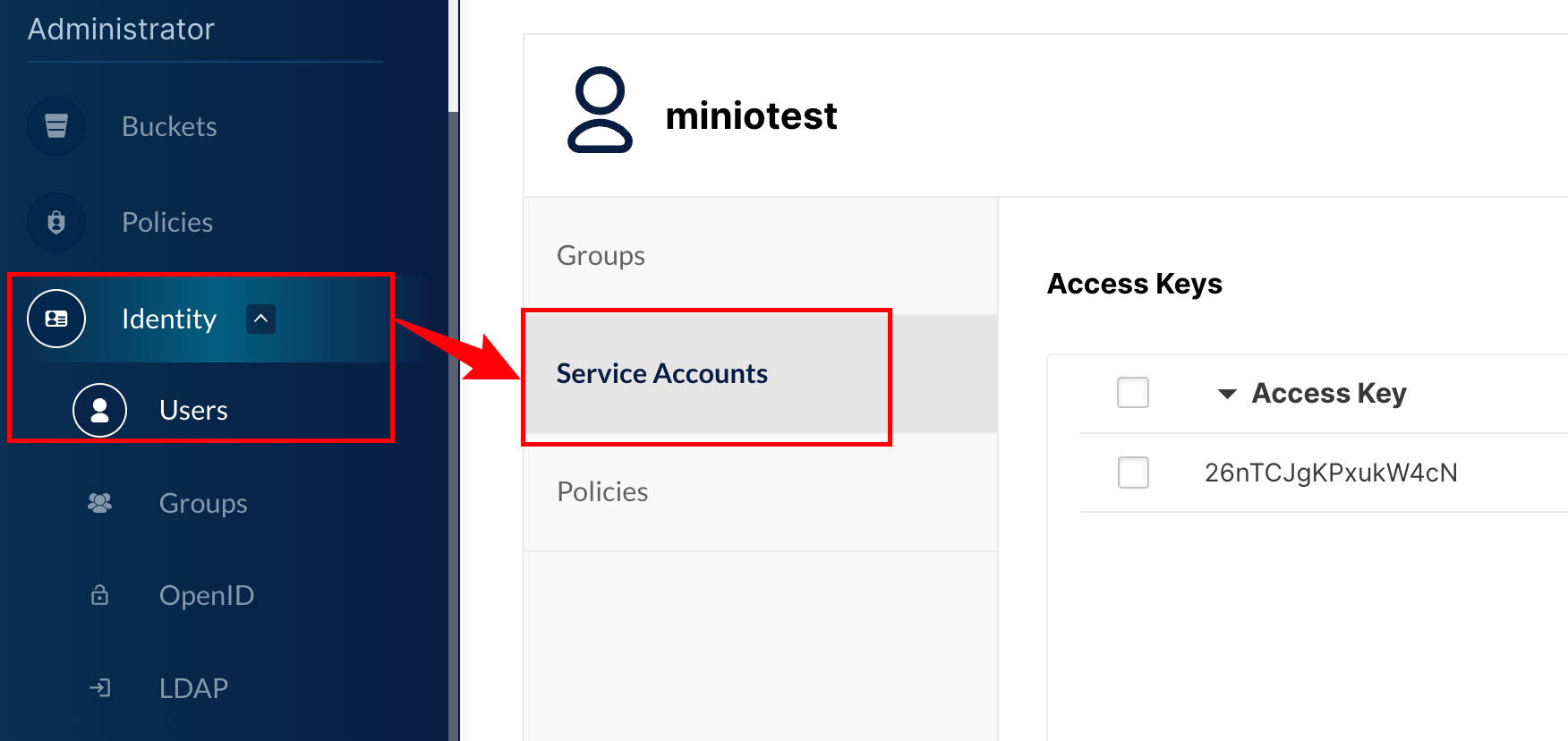
下载保存,备用
- 创建Buckets
MinIO 使用桶来组织对象,桶类似于文件系统中的文件夹或目录,其中每个桶可以容纳任意数量的对象。

赋予桶 public 权限、上传文件,然后可以通过网址来访问文件,如:
http:// 域名:端口 / 桶名 / 文件名http://127.0.0.1:9000/testbucket/1.jpeg
3、整合Java
MinIO官方提供了许多语言的 SDK
-
引入依赖
<dependency> <groupId>io.minio</groupId> <artifactId>minio</artifactId> <version>8.5.1</version> </dependency> -
上传文件
可将 MinioClient 配置成 Bean 对象
创建 MinioClient 对象需要提供
accessKey和secretKey(由具有读写权限的账户创建)// 创建 MinioClient 对象 MinioClient minioClient = MinioClient.builder() .endpoint("http://175.178.20.191:9000") .credentials("HlaV03Fck1XuwE4X", "Sp5CeqEVtasxcgkJ5ZhPJPsFoRknUlSS") .build(); // 如果桶不存在则创建 String bucket = "testbucket"; if (!minioClient.bucketExists(BucketExistsArgs.builder().bucket(bucket).build())) { minioClient.makeBucket(MakeBucketArgs.builder().bucket(bucket).build()); } // 声明上传文件(可定义多层文件夹) UploadObjectArgs uploadObject = UploadObjectArgs.builder() .bucket(bucket) .object("finename/credentials.json") .filename("credentials.json") .build(); // 正式上传文件 minioClient.uploadObject(uploadObject); System.out.println("上传成功~"); -
查询文件及下载
GetObjectArgs getObject = GetObjectArgs.builder() .bucket(bucket) .object("1.jpeg") .build(); // 判断文件是否存在及创建输出流 InputStream input = minioClient.getObject(getObject); FileOutputStream output = new FileOutputStream(getObject.object()); // 存在则下载 IOUtils.copy(input, output); // 关闭输出流 output.close(); System.out.println("下载成功");tips:输入流与输出流之间,可以使用 Spring 工具类
IOUtils进行“快捷拷贝”IOUtils.copy( source , target ); -
删除文件
minioClient.removeObject( RemoveObjectArgs.builder().bucket(bucket).object("credentials.json").build() );
4、实战案例
编写:通用的 Service 层文件传输接口
5、集群部署
暂时搭建失败!
-
简介:
分布式 MinIO 能够将多块硬盘(可以不在同一台机器上)组成一个对象存储 服务,分布式Minio里所有的节点必须拥有相同的access秘钥和secret秘钥才能建立联接,即
accessKey和secretKey一样。 分布式MinIO可以通过
Docker Compose或者Swarm mode进行部署。这两者之间的主要区别是 Compose 只实现单主机多容器部署(测试环境),而 Swarm 模式能实现多主机多容器部署(生产环境)。 -
集群原理:
MinIO分布式集群是指在多个服务器节点均部署MinIO服务,并将其组建为分布式存储集群,对外提供标准S3接口以进行统一访问。MinIO采用去中心化无共享架构,各节点间为对等关系,连接至任一节点均可实现对集群的访问,我们可以使用 Nginx 对节点进行轮询。
-
实战(搭建失败):
2台机器、4个硬盘,硬盘序号一致
175.178.20.191 minio1 47.94.55.73 minio2第一台机器
docker run -d \ -p 9000:9000 \ -p 9090:9090 \ --net=host \ -e "MINIO_ROOT_USER=minioadmin" \ -e "MINIO_ROOT_PASSWORD=minioadmin" \ -v /home/minio/data1:/data1 \ -v /home/minio/data2:/data2 \ -v /home/minio/data3:/data3 \ -v /home/minio/data4:/data4 \ -v /home/minio/config:/root/.minio \ --name minio \ minio/minio \ server http://minio{1...2}/data{1...4} \ --console-address ":9090" -address ":9000"第二台机器
docker run -d \ -p 9001:9001 \ -p 9091:9091 \ --net=host \ -e "MINIO_ROOT_USER=minioadmin" \ -e "MINIO_ROOT_PASSWORD=minioadmin" \ -v /home/minio/data1:/data1 \ -v /home/minio/data2:/data2 \ -v /home/minio/config:/root/.minio \ --name minio2 \ minio/minio \ server http://minio{1...2}/data{1...4} \ --console-address ":9091" -address ":9001"测试
docker rm -f $(docker ps -a)docker run -d --name minio \ -p 9000:9000 \ -p 9001:9001 \ --restart=always --net=host \ -e MINIO_ACCESS_KEY=minio \ -e d=minio123 \ -v /data/config:/root/.minio \ -v /data/data1:/data1 \ -v /data/data2:/data2 \ -v /data/data3:/data3 \ -v /data/data4:/data4 \ minio/minio server http://minio{1...2}/data{1...4} \ --console-address ":9001"
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
