首页 > 基础资料 博客日记
基于注解注册连接的Thrift框架(04)——TProtocol
2024-07-18 15:00:03基础资料围观500次
前情提要
之前介绍了TProcessor的同步和异步实现,也说明了TAsyncMethodCall中的状态循环以及它是如何和TServer进行交互的。
TProtocol
TProtocol 是一个抽象类,主要做了两件事情:
- 绑定一个TTransport
- 定义一系列读写消息的编解码接口。包括两类,一类是复杂数据结构比如readMessageBegin, readMessageEnd, writeMessageBegin, writMessageEnd.还有一类是基本数据结构,比如readI32, writeI32, readString, writeString
Schema
在编译完IDL之后,会生成一系列“方法名_args”/“方法名_result”的静态类,比如我有一个“add”方法。我就会生成add_args 和 add_result 两个类。
在Client中可以直接看到对这两个类的实例化:
public void send_add(int arg1, int arg2) throws TException
{
add_args args = new add_args(); // 这里
args.setArg1(arg1);
args.setArg2(arg2);
sendBase("add", args);
}
回到静态类中,这里以add_args为例子,可以看到里面有一个静态代码块,初始化了两个Schema。
public static class add_args implements org.apache.thrift.TBase<add_args, add_args._Fields>, java.io.Serializable, Cloneable, Comparable<add_args> {
//...
private static final Map<Class<? extends IScheme>, SchemeFactory> schemes = new HashMap<Class<? extends IScheme>, SchemeFactory>();
static {
schemes.put(StandardScheme.class, new add_argsStandardSchemeFactory()); // 1、标准Schema
schemes.put(TupleScheme.class, new add_argsTupleSchemeFactory()); // 2、元组Schema
}
//...
}
在 TProtocol 中,返回的是 StandardSchema.class ,只有在 TTupleProtocol 中才进行了重写。所以除了 TTupleProtocol 外,所有的都使用 StandardSchema .
所以,在add_args中,read/write方法的调用最终是调用Schema中的read/write实现。
读写
Thrift对TProtocol的约束中,(调用方)写步骤如下:
1、先writeMessageBegin表示开始传输消息了,写消息头。Message里面定义了方法名,调用的类型,版本号,消息seqId。
2、接下来是写方法的参数,实际就是写消息体。先写入结构:writeStructBegin
3、再写入字段:writeFieldBegin
3.1、再写入内容:如果是集合类型那就writeMapBegin/writeListBegin;如果是一般类型,那就是writeI32/writeI64
3.2、结束字段写入:writeFieldEnd
4、重复第3步骤,把方法中所有的形参都写完之后,writeFieldStop
5、结束结构的写入:writeStructEnd
6、结束消息的传输:writeMessageEnd
// add_args.write()
public void write(org.apache.thrift.protocol.TProtocol oprot, add_args struct) throws TException {
struct.validate();
oprot.writeStructBegin(STRUCT_DESC); // 2
oprot.writeFieldBegin(ARG1_FIELD_DESC); //3
oprot.writeI32(struct.arg1); // 3.1
oprot.writeFieldEnd(); // 3.2
oprot.writeFieldBegin(ARG2_FIELD_DESC); // 3
oprot.writeI32(struct.arg2); // 3.1
oprot.writeFieldEnd(); // 3.2
oprot.writeFieldStop(); // 4
oprot.writeStructEnd(); // 5
}
(接收方)读信息的过程和(调用方)写入的过程一致:
public void read(org.apache.thrift.protocol.TProtocol iprot, add_args struct) throws TException {
org.apache.thrift.protocol.TField schemeField;
iprot.readStructBegin(); // 2
while (true)
{
schemeField = iprot.readFieldBegin(); // 3
if (schemeField.type == org.apache.thrift.protocol.TType.STOP) {
break;
}
switch (schemeField.id) {
case 1: // 形参1
if (schemeField.type == org.apache.thrift.protocol.TType.I32) {
struct.arg1 = iprot.readI32(); // 3.1
struct.setArg1IsSet(true);
} else {
org.apache.thrift.protocol.TProtocolUtil.skip(iprot, schemeField.type);
}
break;
case 2: // 形参2
if (schemeField.type == org.apache.thrift.protocol.TType.I32) {
struct.arg2 = iprot.readI32(); // 3.1
struct.setArg2IsSet(true);
} else {
org.apache.thrift.protocol.TProtocolUtil.skip(iprot, schemeField.type);
}
break;
default:
org.apache.thrift.protocol.TProtocolUtil.skip(iprot, schemeField.type);
}
iprot.readFieldEnd(); // 4
}
iprot.readStructEnd(); // 5
struct.validate();
}
调用流程
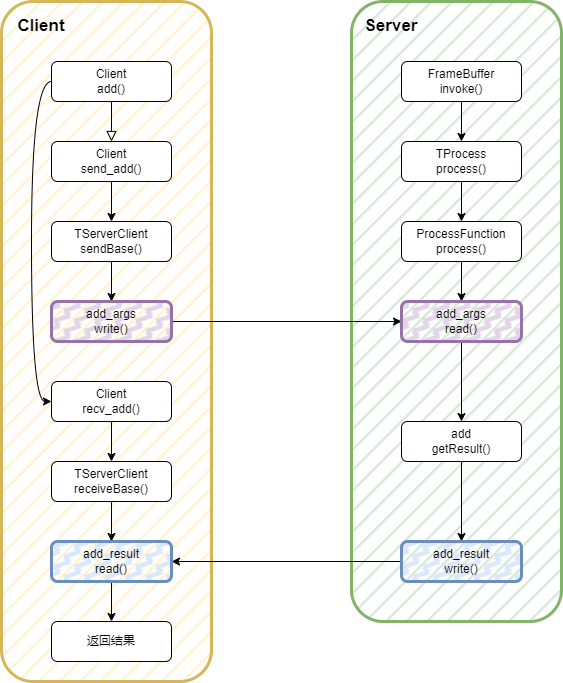
整体的调用流程如上图所示,从之前的代码中我们可以知道,在add_args和add_result中读写都是一一对应的。
从流程中我们可以知道,在客户端和服务端各自调用一边的读和一边的写,从而进行交互。
不同的实现类
上面我们知道了TProtocol的作用、读写的源码以及交互的调用流程。这里介绍TProtocol的实现类。
不同的实现类代表着不同的数据编码:
TJSONProtocol
@Override
public void writeI16(short i16) throws TException {
writeJSONInteger((long)i16);
}
==============
private void writeJSONInteger(long num) throws TException {
context_.write();
String str = Long.toString(num);
boolean escapeNum = context_.escapeNum();
if (escapeNum) {
trans_.write(QUOTE);
}
try {
byte[] buf = str.getBytes("UTF-8");
trans_.write(buf);
} catch (UnsupportedEncodingException uex) {
throw new TException("JVM DOES NOT SUPPORT UTF-8");
}
if (escapeNum) {
trans_.write(QUOTE);
}
}
把他们都转化成JSON格式。
TJSONProtocol
@Override
public void writeI16(short i16) throws TException {
writeJSONInteger((long)i16);
}
==============
private void writeJSONInteger(long num) throws TException {
context_.write();
String str = Long.toString(num);
boolean escapeNum = context_.escapeNum();
if (escapeNum) {
trans_.write(QUOTE);
}
try {
byte[] buf = str.getBytes("UTF-8");
trans_.write(buf);
} catch (UnsupportedEncodingException uex) {
throw new TException("JVM DOES NOT SUPPORT UTF-8");
}
if (escapeNum) {
trans_.write(QUOTE);
}
}
TBinaryProtocol
public void writeI16(short i16) throws TException {
i16out[0] = (byte)(0xff & (i16 >> 8));
i16out[1] = (byte)(0xff & (i16));
trans_.write(i16out, 0, 2);
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
