首页 > 基础资料 博客日记
Java 集合框架:Java 中的 Set 集合(HashSet & LinkedHashSet & TreeSet)特点与实现解析
2024-07-13 06:00:05基础资料围观597次
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 017 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自己的技术栈的同学。与此同时,本专栏的所有文章,也都会准备充足的代码示例和完善的知识点梳理,因此也十分适合零基础的小白和要准备工作面试的同学学习。当然,我也会在必要的时候进行相关技术深度的技术解读,相信即使是拥有多年 Java 开发经验的从业者和大佬们也会有所收获并找到乐趣。
–
相较于 List 集合与 Map 集合,Set 集合可以讨论的点其实很少,这主要的原因是因为无论是哪一种 Set 集合的实现类其实都是基于 Map 集合的,而如果深究其原理,其实就是去深究 Map 的实现,而我不打算对 Map 的解读放在 Set 的章节…
当然除了主要实现之外,Set 也是有很多值得我们关注的特点的,比如他的无序性,对并发流、序列化以及非序列化的实现,以及主要实现类 HashSet、TreeSet、LinkedHashSet 三者的区别,只是由于可能真正值得关注的点不是很多,所以我在本系列中将整个 Set 压缩为了一篇文章。
文章目录
1、Set 集合介绍
1.1、Set 接口概述
Set 是 java.util 包下集合框架中一个接口,它是 Collection 接口的一个子接口,表示不允许包含重复元素的集合。Set 集合的特点是集合内的元素无序,且每个元素都是唯一的。这意味着即使试图添加两个相等的对象(依据 .equals() 方法判断相等),Set 集合只会保存一个对象。
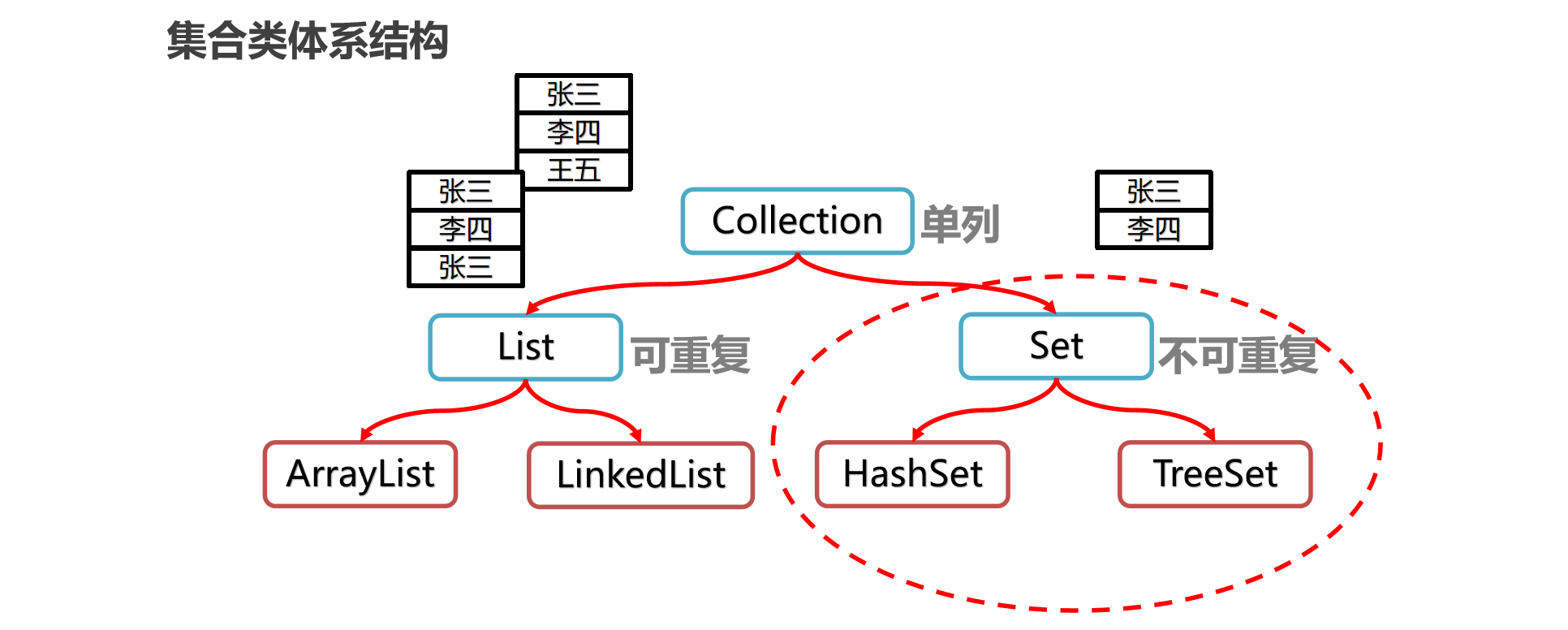
Set集合的特点:
- 无序性:Set 集合中的元素不按任何特定顺序排列,无法通过索引访问元素,即集合内部的元素顺序可能随时间和操作发生变化;
- 唯一性:Set 集合不允许包含重复的元素。判断元素是否重复的标准是基于元素的
.equals()方法。如果两个对象在.equals()方法下判断为相等,则 Set 集合中只会存储其中一个; - 最大容量:理论上,Set 集合可以无限增长,直到受到可用内存限制为止。
1.2、实现类 HashSet
HashSet 是 Java 集合框架中一个实现 Set 接口的类,它使用哈希表(内部一般采用 HashMap)作为底层数据结构,主要用于存储不重复的元素集合。
HashSet 集合有以下特点:
- 唯一性;
- 无序性;
- 高效性:由于基于哈希表实现,
HashSet插入、删除和查找元素的平均时间复杂度为O(1),前提是哈希函数能够良好地分散冲突。 - 允许存储
null值:HashSet允许存储一个null元素,但仅能存储一个,因为null的哈希码固定为0。
1.3、实现类 TreeSet
TreeSet 同样是 Java 集合框架中实现 Set 接口的一个重要类,它基于红黑树(Red-Black Tree)数据结构,提供了一个有序的、不包含重复元素的集合。
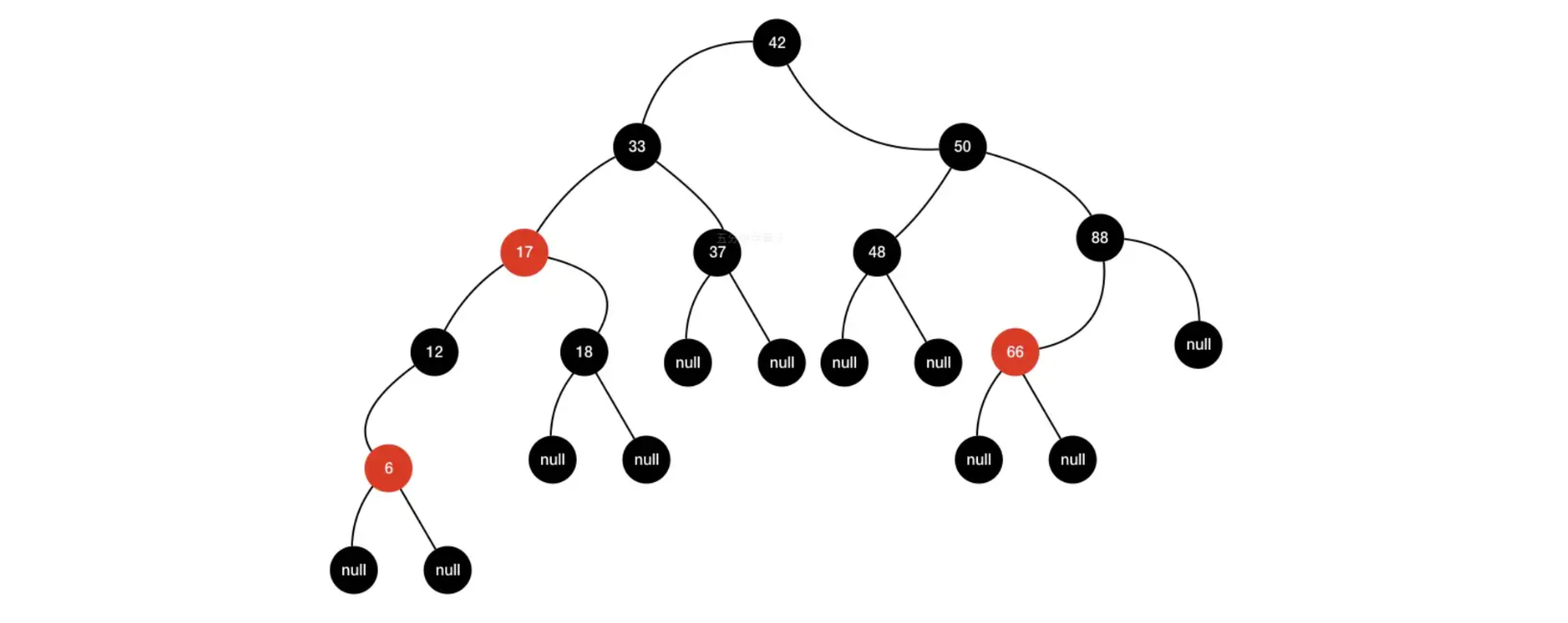
相比于 HashSet,TreeSet 性能稍逊,但在需要排序功能时非常有用。
TreeSet集合有以下特点:
- 唯一性
- 有序性:
TreeSet中的元素是有序的,排序规则既可以是元素本身的自然排序(元素类实现了Comparable接口),也可以是由客户端提供的Comparator来决定。 - 自平衡:由于基于红黑树实现,
TreeSet在插入、删除和查找操作后都能保持树的平衡,从而确保这些操作的时间复杂度接近O(log n)。
1.4、实现类 LinkedHashSet
LinkedHashSet 继承自 HashSet 并实现了 Set 接口。LinkedHashSet 集合是一种哈希表和链表的组合,它具有以下特点:
- 无序性:与
HashSet类似,LinkedHashSet也不允许集合中有重复的元素。 - 有序性:与
HashSet不同的是,LinkedHashSet维护了一个双向链表,使得迭代它时可以按照插入顺序访问集合中的元素。 - 性能:
LinkedHashSet在大多数情况下提供与HashSet相同的时间和空间复杂度,即添加、删除和查找元素的时间复杂度为 O(1)。
当你需要一个不允许重复元素的集合,并且希望迭代时能够按照元素的插入顺序进行时,可以使用 LinkedHashSet。LinkedHashSet 可以作为 HashMap 的键集合,因为它提供了快速的查找和迭代性能。
1.5、三种 Set 集合对比
| 特点 | HashSet | TreeSet | LinkedHashSet |
|---|---|---|---|
| 底层数据结构 | HashMap | 红黑树 | LinkedHashMap |
| 元素顺序 | 无特定顺序 | 按自然顺序或自定义顺序 | 按插入顺序 |
| 时间复杂度 | O(1) | O(log n) | O(1) |
| 额外功能 | 无 | 支持范围查询和排序操作 | 保证插入顺序 |
| 适用场景 | 需要快速访问和操作的集合 | 需要排序的有序集合 | 需要保持插入顺序且快速访问和操作的集合 |
总的来说,这三种集合各有优劣,选择时需根据具体需求考虑,如性能要求、是否需要排序或保持顺序等。
- HashSet:在需要高效地进行添加、删除、查找操作且不关心元素顺序时最为适用。
- TreeSet:适用于需要对元素进行排序和范围查询的场景,尽管性能稍逊,但提供了额外的有序操作方法。
- LinkedHashSet:当既需要快速操作元素,又需要保持插入顺序时,是最佳选择。
2、HashSet 底层实现
HashSet<E> 继承自 AbstractSet<E>,实现了 Set<E>, Cloneable 和 java.io.Serializable 接口。Cloneable 使其支持克隆,Serializable 使其支持序列化。
2.1、HashSet 构造函数实现
HashSet 类在 Java 集合框架中提供了多个构造函数,用于创建不同的 HashSet 实例。
package java.util;
import ...
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// 底层使用 HashMap 实现
private transient HashMap<E,Object> map;
// 用于与 HashMap 中的 key 关联的虚拟值
private static final Object PRESENT = new Object();
/**
* 构造一个新的空集合,底层 HashMap 的默认初始容量为 16,负载因子为 0.75
*/
public HashSet() {
map = new HashMap<>();
}
/**
* 构造一个包含指定集合中元素的新集合。底层 HashMap 的负载因子为 0.75,
* 初始容量足以包含指定集合中的元素。
*
* @param c 要放入此集合的元素的集合
* @throws NullPointerException 如果指定的集合为 null
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* 构造一个新的空集合,底层 HashMap 实例具有指定的初始容量和负载因子。
*
* @param initialCapacity 哈希映射的初始容量
* @param loadFactor 哈希映射的负载因子
* @throws IllegalArgumentException 如果初始容量小于 0,或负载因子非正
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* 构造一个新的空集合,底层 HashMap 实例具有指定的初始容量和默认负载因子 0.75。
*
* @param initialCapacity 哈希表的初始容量
* @throws IllegalArgumentException 如果初始容量小于 0
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* 构造一个新的空的 LinkedHashSet。仅由 LinkedHashSet 使用的包私有构造函数。
* 底层 HashMap 实例是具有指定初始容量和负载因子的 LinkedHashMap。
*
* @param initialCapacity 哈希映射的初始容量
* @param loadFactor 哈希映射的负载因子
* @param dummy 忽略(用于区分其他 int, float 构造函数)
* @throws IllegalArgumentException 如果初始容量小于 0,或负载因子非正
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
// 省略其他方法和实现细节
...
}
从这部分代码我们可以看出:
HashSet主要通过HashMap实现其所有功能,所有元素作为HashMap的键存储,而PRESENT常量对象作为所有键的值。- 多个构造函数提供了不同的初始化方式,满足不同场景下的使用需求。
- 包私有构造函数
HashSet(int initialCapacity, float loadFactor, boolean dummy)专为LinkedHashSet设计,用于支持按插入顺序访问元素。
2.2、HashSet 主要方法实现
从 HashSet 具体的方法实现,我们可以进一步看出 HashSet 通过 HashMap 实现其所有主要功能,通过 HashMap 的键值特性,确保集合中的元素不重复。由于底层采用哈希表存储,HashSet 提供了快速的元素添加、删除和查找操作。
此外 HashSet 也主要实现了部分流方法,用于实现序列化、反序列化和并行流操作:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// 底层使用 HashMap 实现
private transient HashMap<E,Object> map;
// 用于与 HashMap 中的 key 关联的虚拟值
private static final Object PRESENT = new Object();
// 省略其他方法和实现细节
...
// 返回该集合的迭代器
public Iterator<E> iterator() {
return map.keySet().iterator();
}
/**
* 返回集合中的元素数量(基数)。
*
* @return 集合中的元素数量(基数)
*/
public int size() {
return map.size();
}
/**
* 如果此集合不包含任何元素,则返回 true。
*
* @return 如果此集合不包含任何元素,则返回 true
*/
public boolean isEmpty() {
return map.isEmpty();
}
/**
* 如果此集合包含指定的元素,则返回 true。
* 更正式地讲,当且仅当此集合包含一个元素 e 满足 (o==null ? e==null : o.equals(e)) 时,返回 true。
*
* @param o 测试在此集合中的存在的元素
* @return 如果此集合包含指定的元素,则返回 true
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* 如果指定元素尚未存在于集合中,则将其添加到集合中。
* 更正式地讲,如果此集合不包含元素 e2 满足 (e==null ? e2==null : e.equals(e2)),则将指定元素 e 添加到此集合中。
* 如果此集合已经包含该元素,则此调用不更改集合并返回 false。
*
* @param e 要添加到集合中的元素
* @return 如果集合中尚不包含指定元素,则返回 true
*/
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
/**
* 如果集合中存在指定的元素,则将其从集合中移除。
* 更正式地讲,如果此集合包含一个元素 e 满足 (o==null ? e==null : o.equals(e)),则将其移除。
* 如果此集合包含该元素,则返回 true(即此调用改变了集合)。
*
* @param o 要从集合中移除的元素
* @return 如果集合中包含指定的元素,则返回 true
*/
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
/**
* 从此集合中移除所有元素。此调用返回后集合将为空。
*/
public void clear() {
map.clear();
}
/**
* 返回此 HashSet 实例的浅表副本:元素本身不被克隆。
*
* @return 此集合的浅表副本
*/
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
/**
* 将此 HashSet 实例的状态保存到一个流中(即,序列化它)。
*
* @serialData 发出支持 HashMap 实例的容量(int)及其负载因子(float),
* 然后是集合的大小(它包含的元素数量)(int),
* 以及所有的元素(每个是 Object),顺序不定。
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// 写出所有默认的序列化内容
s.defaultWriteObject();
// 写出 HashMap 的容量和负载因子
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// 写出大小
s.writeInt(map.size());
// 写出所有元素,顺序不定
for (E e : map.keySet())
s.writeObject(e);
}
/**
* 从流中重构 HashSet 实例(即,反序列化它)。
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// 读取并忽略流字段(当前为零)
s.readFields();
// 读取容量并验证非负
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("非法容量: " + capacity);
}
// 读取负载因子并验证正值且非 NaN
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("非法负载因子: " + loadFactor);
}
// 将负载因子限制在 0.25 到 4.0 范围内
loadFactor = Math.min(Math.max(0.25f, loadFactor), 4.0f);
// 读取大小并验证非负
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("非法大小: " + size);
}
// 根据大小和负载因子设置容量,确保 HashMap 至少填充 25%,并限制最大容量
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
// 构造支持的 HashMap 将在添加第一个元素时懒惰地创建一个数组,
// 因此在构造前进行检查。调用 HashMap.tableSizeFor 计算实际分配大小。
// 检查 Map.Entry[].class,因为它是最接近实际创建的公共类型。
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
// 创建支持的 HashMap
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// 以适当的顺序读取所有元素
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
/**
* 创建一个晚绑定且快速失败的 Spliterator 对象,遍历此集合中的元素。
*
* Spliterator 报告 SIZED 和 DISTINCT 特性。
* 重写实现应记录额外特性值的报告。
*
* @return 一个遍历此集合中元素的 Spliterator
* @since 1.8
*/
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}
3、TreeSet 底层实现
TreeSet 类实现了 NavigableSet 接口,提供了一组按顺序存储的集合元素。它使用一个 NavigableMap 来存储元素,默认情况下是 TreeMap。
3.1、TreeSet 构造方法实现
TreeSet 提供了多个构造函数,以支持不同的初始化方式:
- 无参构造函数:创建一个空的
TreeSet,按自然顺序排序; - 带比较器参数的构造函数:按指定的比较器排序;
- 带集合参数的构造函数:使用指定集合的元素构造
TreeSet,按自然顺序排序; - 带排序集参数的构造函数:使用指定排序集的元素和顺序构造
TreeSet。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* 底层使用的 NavigableMap 实例。
*/
private transient NavigableMap<E,Object> m;
// 作为在底层 Map 中与元素关联的虚拟值
private static final Object PRESENT = new Object();
/**
* 构造一个由指定的 NavigableMap 支持的集合。
*/
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
/**
* 构造一个新的空的树集,按照元素的自然顺序排序。
* 插入集合的所有元素必须实现 {@link Comparable} 接口。
* 此外,所有元素必须是相互可比较的:{@code e1.compareTo(e2)}
* 不能对集合中的任何元素 {@code e1} 和 {@code e2} 抛出
* {@code ClassCastException} 异常。如果用户尝试添加违反此约束的元素
* (例如,用户尝试将字符串元素添加到整数元素的集合中),
* {@code add} 调用将抛出 {@code ClassCastException} 异常。
*/
public TreeSet() {
this(new TreeMap<E,Object>());
}
/**
* 构造一个新的空的树集,按照指定的比较器排序。
* 插入集合的所有元素必须是由指定的比较器相互可比较的:
* {@code comparator.compare(e1, e2)} 不能对集合中的任何元素
* {@code e1} 和 {@code e2} 抛出 {@code ClassCastException} 异常。
* 如果用户尝试添加违反此约束的元素,
* {@code add} 调用将抛出 {@code ClassCastException} 异常。
*
* @param comparator 用于排序此集合的比较器。
* 如果 {@code null},将使用元素的自然顺序。
*/
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
/**
* 构造一个包含指定集合中的元素的新树集,
* 按照元素的自然顺序排序。插入集合的所有元素必须实现
* {@link Comparable} 接口。此外,所有元素必须是相互可比较的:
* {@code e1.compareTo(e2)} 不能对集合中的任何元素 {@code e1} 和
* {@code e2} 抛出 {@code ClassCastException} 异常。
*
* @param c 其元素将构成新集合的集合
* @throws ClassCastException 如果 {@code c} 中的元素不是
* {@link Comparable},或不是相互可比较的
* @throws NullPointerException 如果指定的集合为 null
*/
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
/**
* 构造一个包含指定排序集的相同元素并使用相同顺序的新树集。
*
* @param s 其元素将构成新集合的排序集
* @throws NullPointerException 如果指定的排序集为 null
*/
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
}
3.2、TreeSet 特色方法实现
TreeSet 提供了灵活的集合操作和导航功能的操作,使其成为功能强大的有序集合。这些特点使 TreeSet 在需要有序和高效查找的场景中尤为有用
/**
* 返回此集合中的第一个(最低)元素。
*
* @throws NoSuchElementException 如果此集合为空
*/
public E first() {
return m.firstKey();
}
/**
* 返回此集合中的最后一个(最高)元素。
*
* @throws NoSuchElementException 如果此集合为空
*/
public E last() {
return m.lastKey();
}
/**
* 返回一个新的集合,包含从 fromElement(包含或不包含,根据 fromInclusive)到 toElement(包含或不包含,根据 toInclusive)范围内的元素。
*
* @param fromElement 起始元素
* @param fromInclusive 是否包含起始元素
* @param toElement 结束元素
* @param toInclusive 是否包含结束元素
* @return 包含指定范围内元素的新集合
*/
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<>(m.subMap(fromElement, fromInclusive, toElement, toInclusive));
}
/**
* 返回一个新的集合,包含从集合开头到指定元素(包含或不包含,根据 inclusive)的所有元素。
*
* @param toElement 结束元素
* @param inclusive 是否包含结束元素
* @return 包含从开头到指定元素的新集合
*/
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new TreeSet<>(m.headMap(toElement, inclusive));
}
/**
* 返回一个新的集合,包含从指定元素(包含或不包含,根据 inclusive)到集合末尾的所有元素。
*
* @param fromElement 起始元素
* @param inclusive 是否包含起始元素
* @throws ClassCastException 如果指定元素的类型不允许
* @throws NullPointerException 如果 fromElement 为 null 且集合使用自然顺序,或其比较器不允许 null 元素
* @throws IllegalArgumentException 如果起始元素不合法
* @since 1.6
* @return 包含从指定元素到末尾的新集合
*/
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<>(m.tailMap(fromElement, inclusive));
}
/**
* 返回一个新的集合,包含从 fromElement(包含)到 toElement(不包含)范围内的元素。
*
* @param fromElement 起始元素
* @param toElement 结束元素
* @return 包含指定范围内元素的新集合
*/
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
/**
* 返回一个新的集合,包含从集合开头到指定元素(不包含)的所有元素。
*
* @param toElement 结束元素
* @throws ClassCastException 如果指定元素的类型不允许
* @throws NullPointerException 如果 toElement 为 null 且集合使用自然顺序,或其比较器不允许 null 元素
* @throws IllegalArgumentException 如果结束元素不合法
* @return 包含从开头到指定元素的新集合
*/
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
/**
* 返回一个新的集合,包含从指定元素(包含)到集合末尾的所有元素。
*
* @param fromElement 起始元素
* @throws ClassCastException 如果指定元素的类型不允许
* @throws NullPointerException 如果 fromElement 为 null 且集合使用自然顺序,或其比较器不允许 null 元素
* @throws IllegalArgumentException 如果起始元素不合法
* @return 包含从指定元素到末尾的新集合
*/
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
/**
* 返回此集合中元素的逆序迭代器。
*
* @return 逆序迭代器
*/
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
}
/**
* 返回一个新的集合,包含此集合中元素的逆序视图。
*
* @since 1.6
* @return 逆序视图的新集合
*/
public NavigableSet<E> descendingSet() {
return new TreeSet<>(m.descendingMap());
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
