首页 > 基础资料 博客日记
智能工作流:Spring AI高效批量化提示访问方案
2024-05-11 21:30:03基础资料围观658次
文章智能工作流:Spring AI高效批量化提示访问方案分享给大家,欢迎收藏Java资料网,专注分享技术知识
基于SpringAI搭建系统,依靠线程池\负载均衡等技术进行请求优化,用于解决科研&开发过程中对GPT接口进行批量化接口请求中出现的问题。
github地址:https://github.com/linkcao/springai-wave
大语言模型接口以OpenAI的GPT 3.5为例,JDK版本为17,其他依赖版本可见仓库pom.xml
拟解决的问题
在处理大量提示文本时,存在以下挑战:
- API密钥请求限制: 大部分AI服务提供商对API密钥的请求次数有限制,单个密钥每分钟只能发送有限数量的请求。
- 处理速度慢: 大量的提示文本需要逐条发送请求,处理速度较慢,影响效率。
- 结果保存和分析困难: 处理完成的结果需要保存到本地数据库中,并进行后续的数据分析,但这一过程相对复杂。
解决方案
为了解决上述问题,本文提出了一种基于Spring框架的批量化提示访问方案,如下图所示:
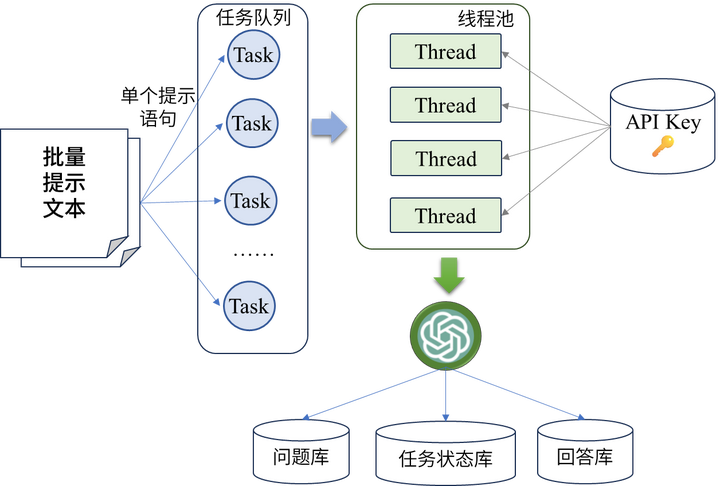
其中具体包括以下步骤:
- 多线程处理提示文本: 将每个提示文本看作一个独立的任务,采用线程池的方式进行多线程处理,提高处理效率。
- 动态分配API密钥: 在线程池初始化时,通过读取本地数据库中存储的API密钥信息,动态分配每个线程单元所携带的密钥,实现负载均衡。
- 结果保存和管理: 在请求完成后,将每个请求的问题和回答保存到本地数据库中,以便后续的数据分析和管理。
- 状态实时更新: 将整个批量请求任务区分为进行中、失败和完成状态,并通过数据库保存状态码实时更新任务状态,方便监控和管理。
关键代码示例
- 多线程异步请求提示信息(所在包: ChatService)
// 线程池初始化
private static final ExecutorService executor = Executors.newFixedThreadPool(10);
/**
* 多线程请求提示
* @param prompts
* @param user
* @param task
* @return
*/
@Async
public CompletableFuture<Void> processPrompts(List<String> prompts, Users user, Task task) {
for (int i = 0; i < prompts.size();i++) {
int finalI = i;
// 提交任务
executor.submit(() -> processPrompt(prompts.get(finalI), user, finalI));
}
// 设置批量任务状态
task.setStatus(TaskStatus.COMPLETED);
taskService.setTask(task);
return CompletableFuture.completedFuture(null);
}
-
如上所示,利用了Spring框架的
@Async注解和线程池的功能,实现了多线程异步处理提示信息。 -
首先,使用了
ExecutorService创建了一个固定大小的线程池,以便同时处理多个提示文本。 -
然后,通过
CompletableFuture来实现异步任务的管理。 -
在处理每个提示文本时,通过
executor.submit()方法提交一个任务给线程池,让线程池来处理。 -
处理完成后,将批量任务的状态设置为已完成,并更新任务状态。
-
一个线程任务需要绑定请求的用户以及所在的批量任务,当前任务所分配的key由任务所在队列的下标决定。
- 处理单条提示信息(所在包: ChatService)
/**
* 处理单条提示文本
* @param prompt 提示文本
* @param user 用户
* @param index 所在队列下标
*/
public void processPrompt(String prompt, Users user, int index) {
// 获取Api Key
OpenAiApi openAiApi = getApiByIndex(user, index);
assert openAiApi != null;
ChatClient client = new OpenAiChatClient(openAiApi);
// 提示文本请求
String response = client.call(prompt);
// 日志记录
log.info("提示信息" + prompt );
log.info("输出" + response );
// 回答保存数据库
saveQuestionAndAnswer(user, prompt, response);
}
- 首先根据任务队列的下标获取对应的API密钥
- 然后利用该密钥创建一个与AI服务进行通信的客户端。
- 接着,使用客户端发送提示文本请求,并获取AI模型的回答。
- 最后,将问题和回答保存到本地数据库和日志中,以便后续的数据分析和管理。
- Api Key 负载均衡(所在包: ChatService)
/**
* 采用任务下标分配key的方式进行负载均衡
* @param index 任务下标
* @return OpenAiApi
*/
private OpenAiApi getApiByIndex(int index){
List<KeyInfo> keyInfoList = keyRepository.findAll();
if (keyInfoList.isEmpty()) {
return null;
}
// 根据任务队列下标分配 Key
KeyInfo keyInfo = keyInfoList.get(index % keyInfoList.size());
return new OpenAiApi(keyInfo.getApi(),keyInfo.getKeyValue());
}
- 首先从本地数据库中获取所有可用的API密钥信息
- 然后根据任务队列的下标来动态分配API密钥。
- 确保每个线程单元都携带了不同的API密钥,避免了因为某个密钥请求次数达到限制而导致的请求失败问题。
- 依靠线程池批量请求GPT整体方法(所在包: ChatController)
/**
* 依靠线程池批量请求GPT
* @param promptFile 传入的批量提示文件,每一行为一个提示语句
* @param username 调用的用户
* @return 处理状态
*/
@PostMapping("/batch")
public String batchPrompt(MultipartFile promptFile, String username){
if (promptFile.isEmpty()) {
return "上传的文件为空";
}
// 批量请求任务
Task task = new Task();
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(promptFile.getInputStream()));
List<String> prompts = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
prompts.add(line);
}
// 用户信息请求
Users user = userService.findByUsername(username);
// 任务状态设置
task.setFileName(promptFile.getName());
task.setStartTime(LocalDateTime.now());
task.setUserId(user.getUserId());
task.setStatus(TaskStatus.PROCESSING);
// 线程池处理
chatService.processPrompts(prompts, user, task);
return "文件上传成功,已开始批量处理提示";
} catch ( IOException e) {
// 处理失败
e.printStackTrace();
task.setStatus(TaskStatus.FAILED);
return "上传文件时出错:" + e.getMessage();
} finally {
// 任务状态保存
taskService.setTask(task);
}
}
- 首先,接收用户上传的批量提示文件和用户名信息。
- 然后,读取文件中的每一行提示文本,并将它们存储在一个列表中。
- 接着,根据用户名信息找到对应的用户,并创建一个任务对象来跟踪批量处理的状态。
- 最后,调用
ChatService中的processPrompts()方法来处理提示文本,并返回处理状态给用户。
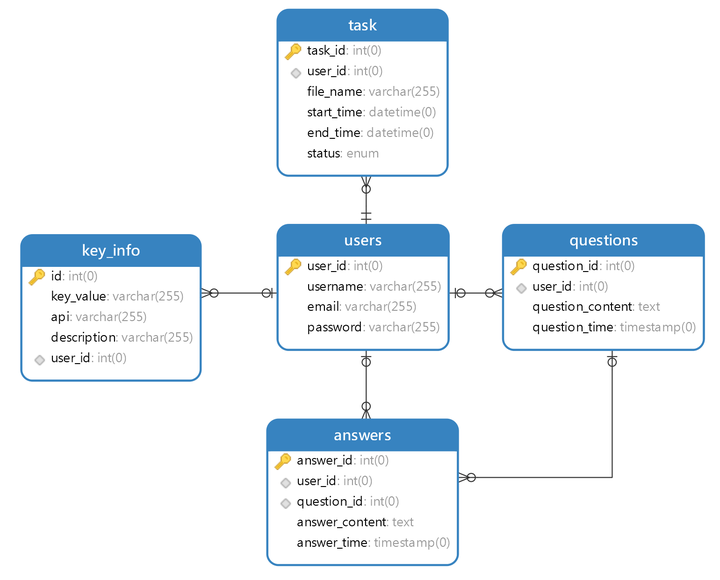
数据库ER图
所有信息都与用户ID强绑定,便于管理和查询,ER图如下所示:
演示示例
- 通过postman携带
批量请求文件和username信息进行Post请求访问localhost:8080/batch接口:
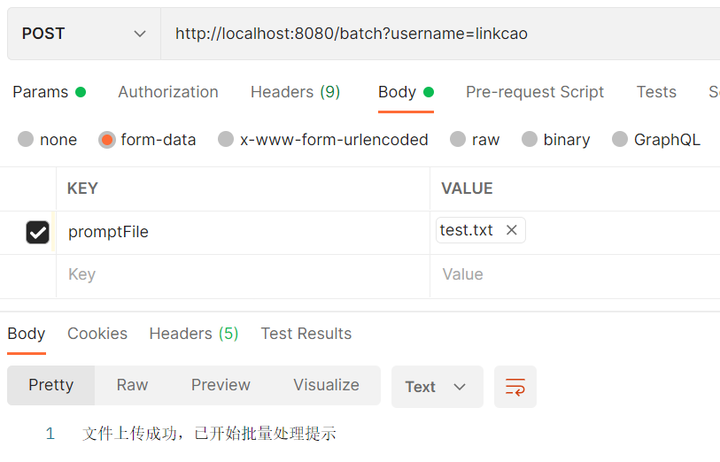
- 在实际应用中,可以根据具体需求对提示文本进行定制和扩展,以满足不同场景下的需求,演示所携带的请求文件内容如下:
请回答1+2=?
请回答8*12=?
请回答12*9=?
请回答321-12=?
请回答12/4=?
请回答32%2=?
- 最终返回的数据库结果,左为问题库,右为回答库:
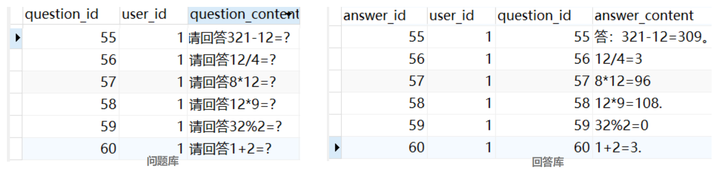
- 问题库和答案库通过
question_id和user_id进行绑定,由于一个问题可以让GPT回答多次,因此两者的关系为多对一,将问题和答案分在两个独立的表中也便于后续的垂域定制和扩展。
文章来源:https://www.cnblogs.com/linkcxt/p/18187163
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
