首页 > 基础资料 博客日记
RAG应用开发实战02-相似性检索的关键 - Embedding
2024-04-14 21:00:03基础资料围观651次
Java资料网推荐RAG应用开发实战02-相似性检索的关键 - Embedding这篇文章给大家,欢迎收藏Java资料网享受知识的乐趣
1 文本Embedding
将整个文本转化为实数向量的技术。
Embedding优点是可将离散的词语或句子转化为连续的向量,就可用数学方法来处理词语或句子,捕捉到文本的语义信息,文本和文本的关系信息。
◉ 优质的Embedding通常会让语义相似的文本在空间中彼此接*

◉ 优质的Embedding相似的语义关系可以通过向量的算术运算来表示:
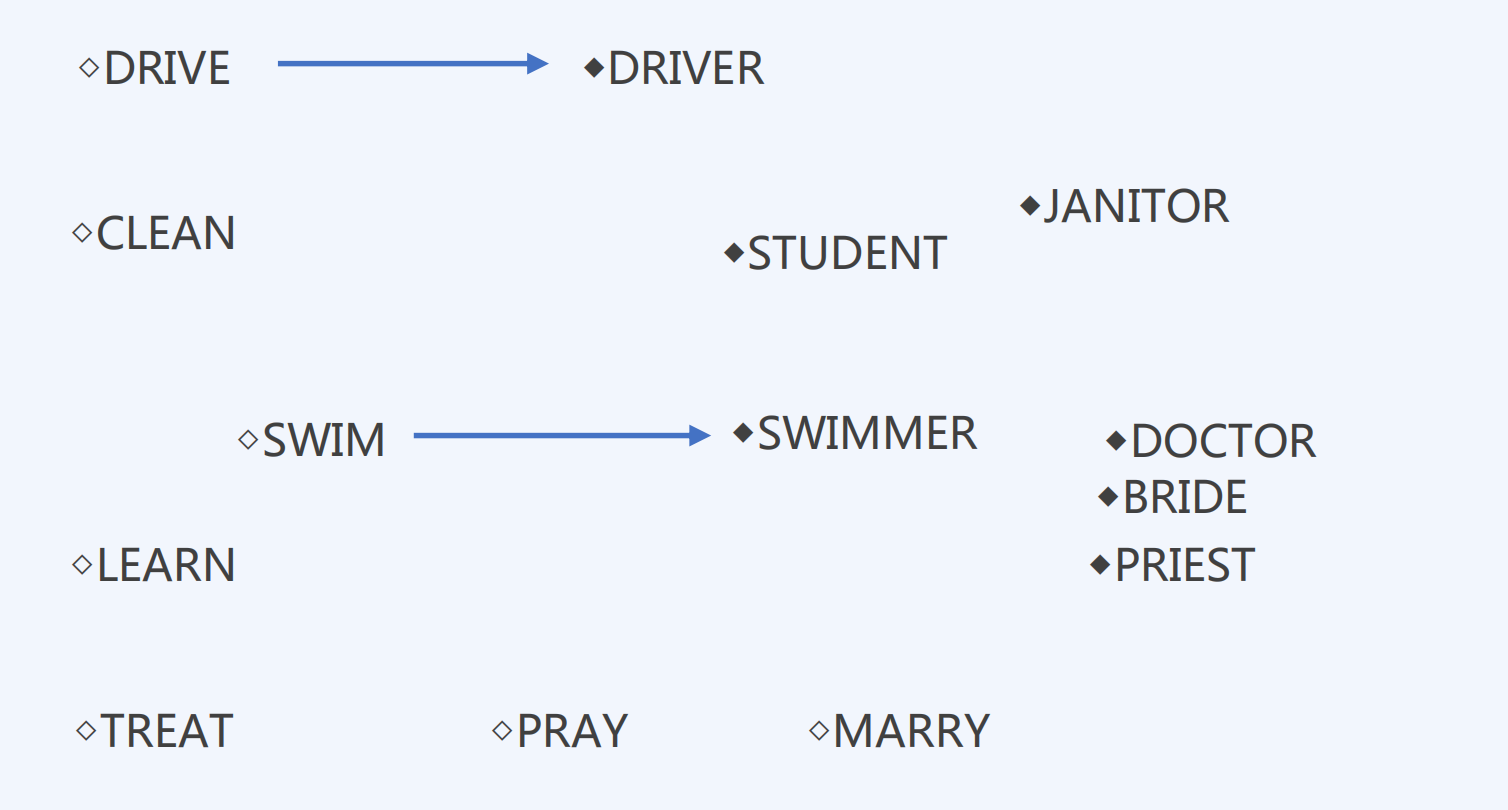
2 文本Embedding模型的演进与选型
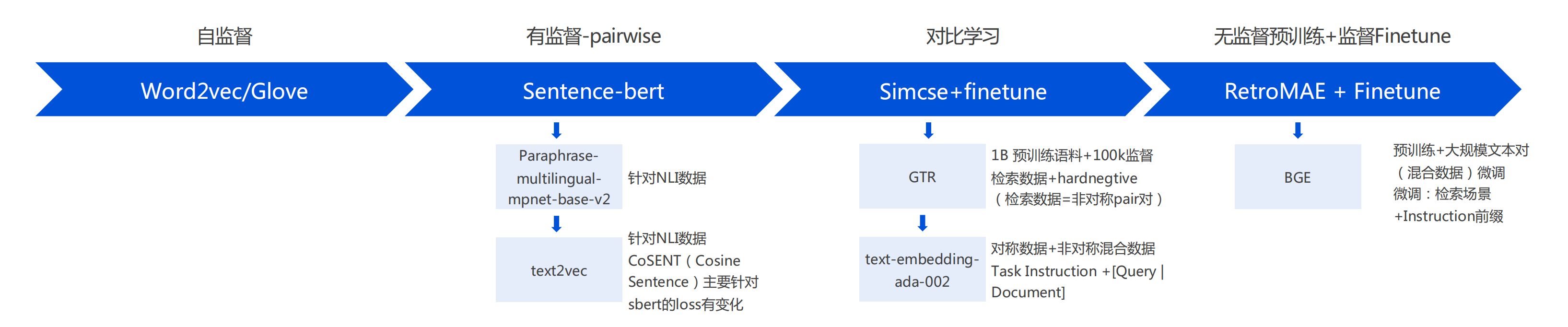
目前的向量模型从单纯的基于 NLI 数据集(对称数据集)发展到基于混合数据(对称+非对称)进行训练,即可以做 QQ召回任务也能够做 QD 召回任务,通过添加 Instruction 来区分这两类任务,只有在进行 QD 召回的时候,需要对用户 query 添加上 Instruction 前缀。
3 VDB通用Embedding模型
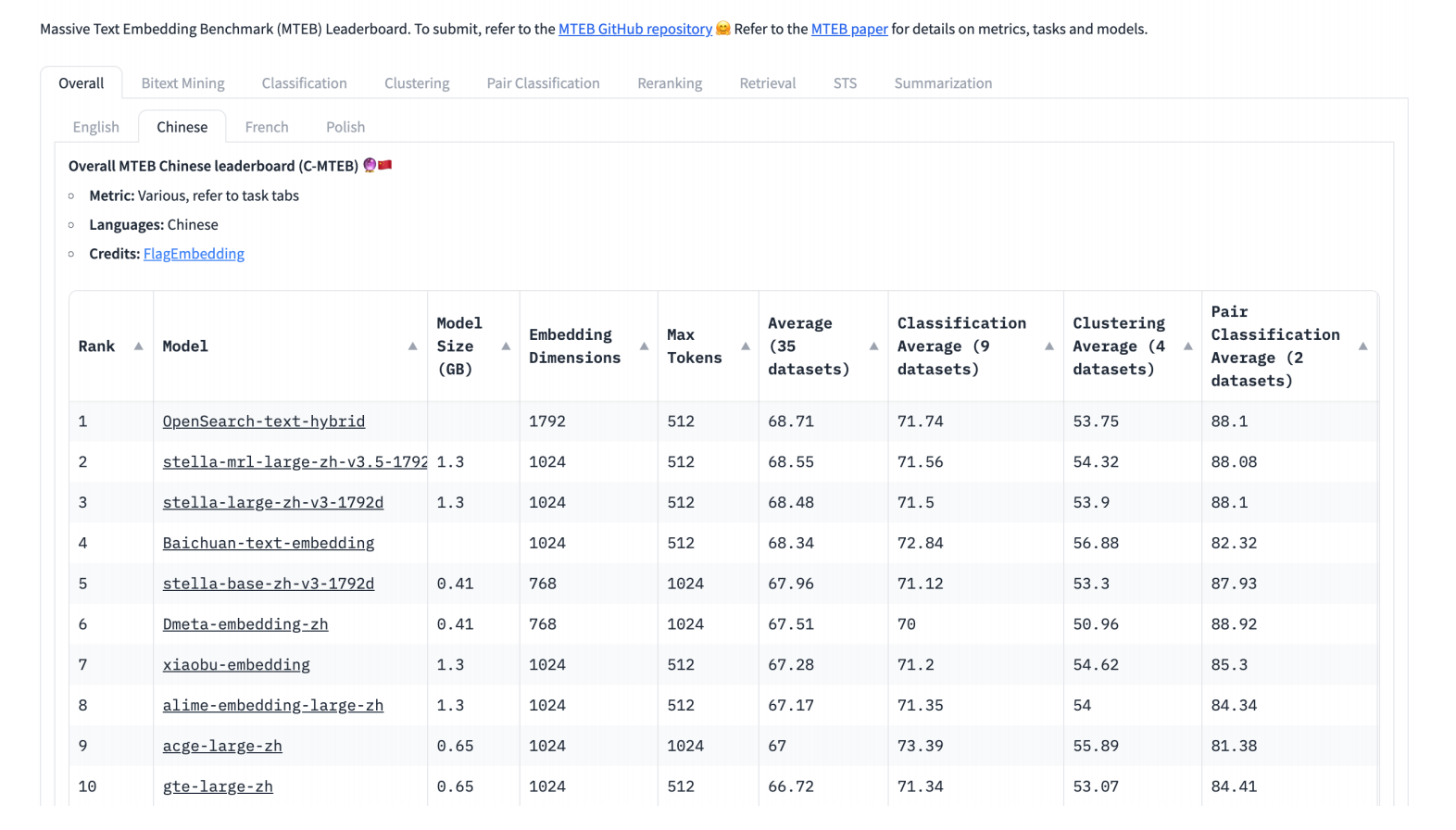
模型选择:
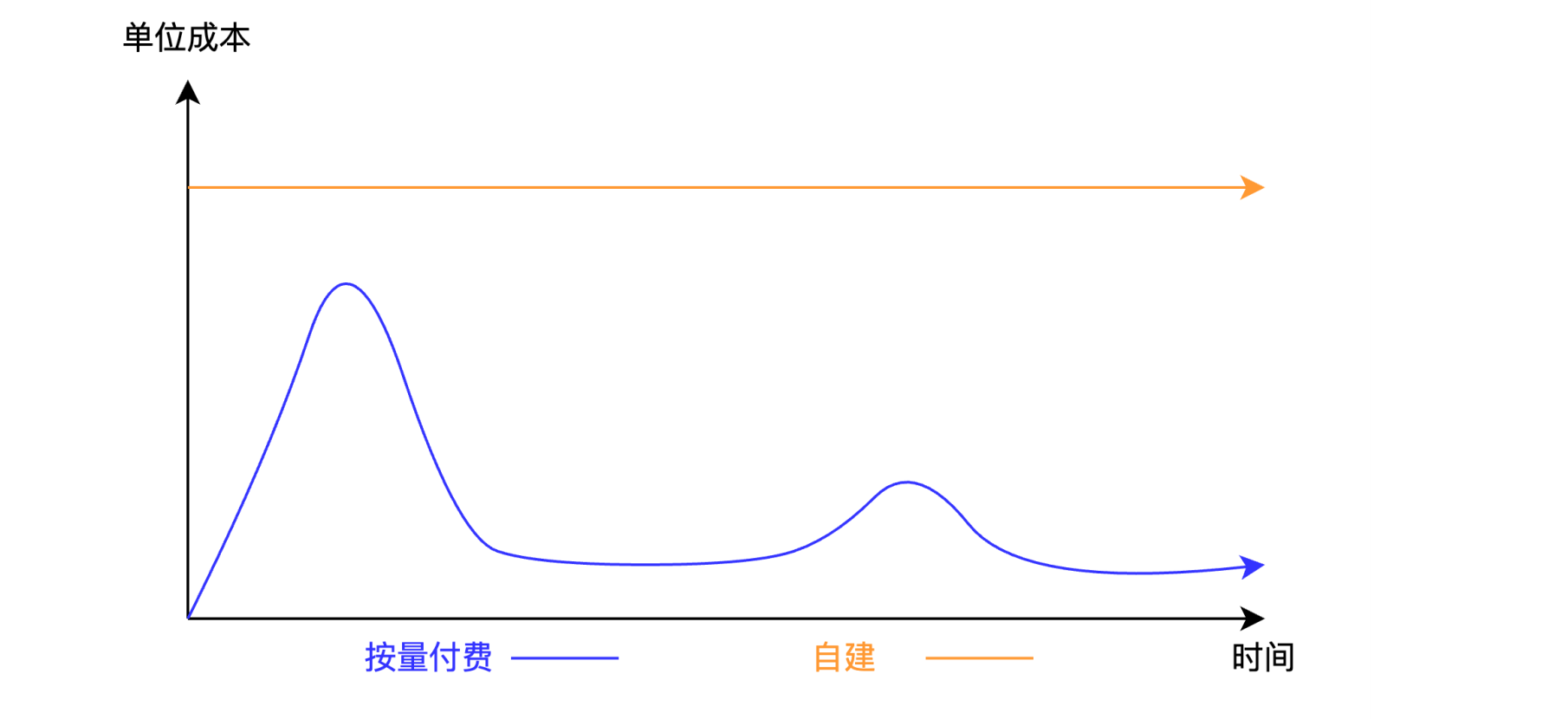
GPU资源:
4 VDB垂类Embedding模型
用户提供垂类文档数据,VDB对模型进行微调,助力垂类应用效果更进一步。
优化1:对比学*拉*同义文本的距离,推远不同文本的距离
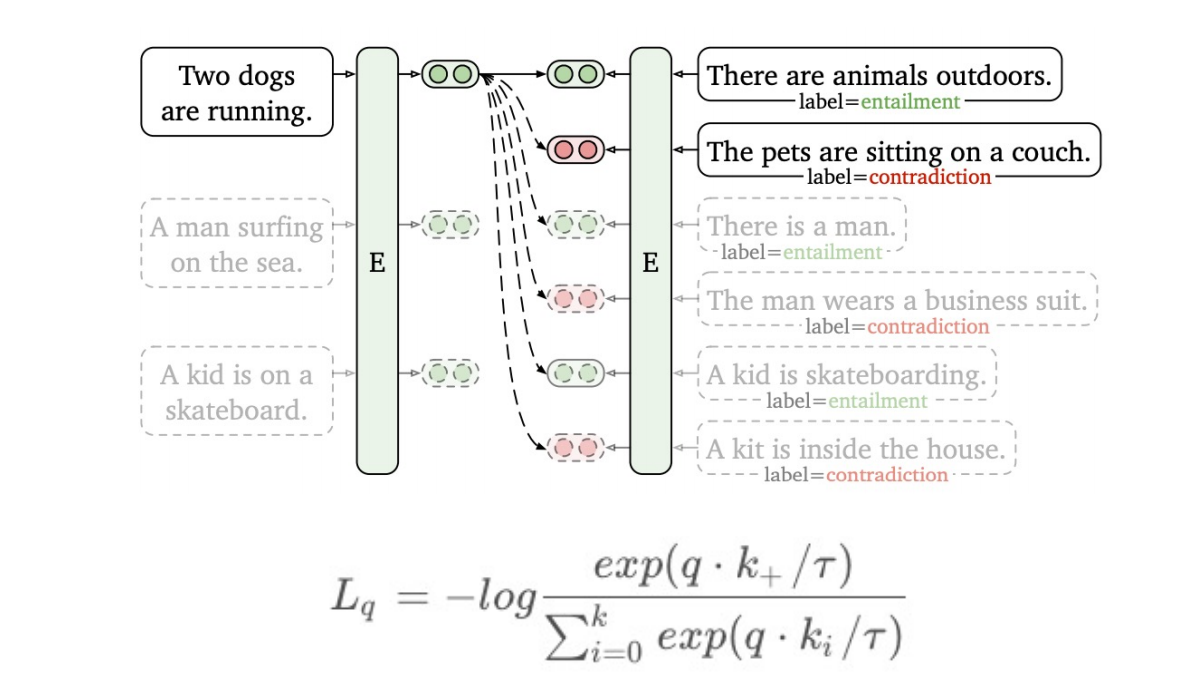
优化2:短文本匹配和长文本匹配使用不同prompt,提升非对称类文本效果
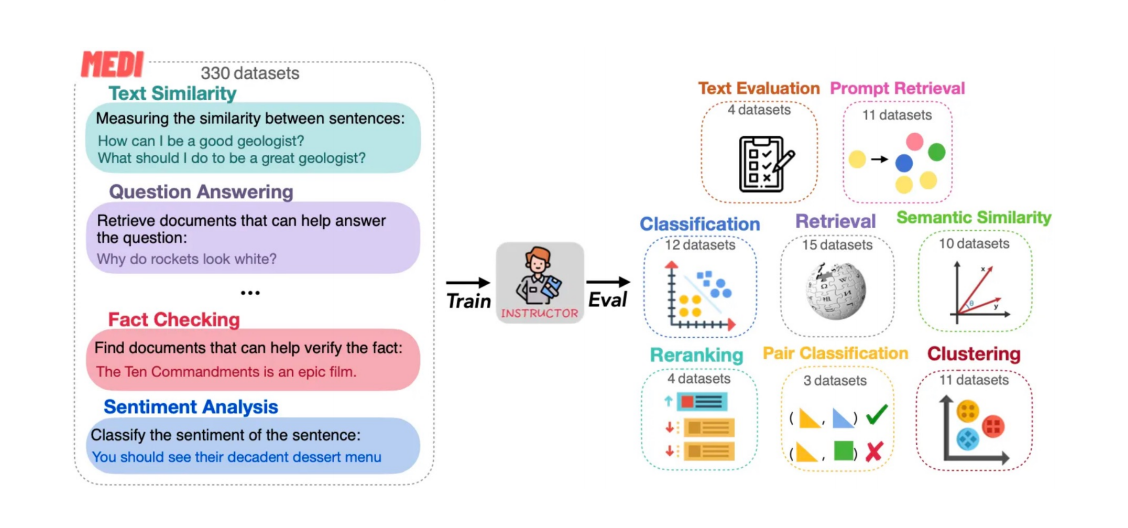
优化3:预训练阶段提升基座模型面向检索的能力,对比学*阶段提高负样本数
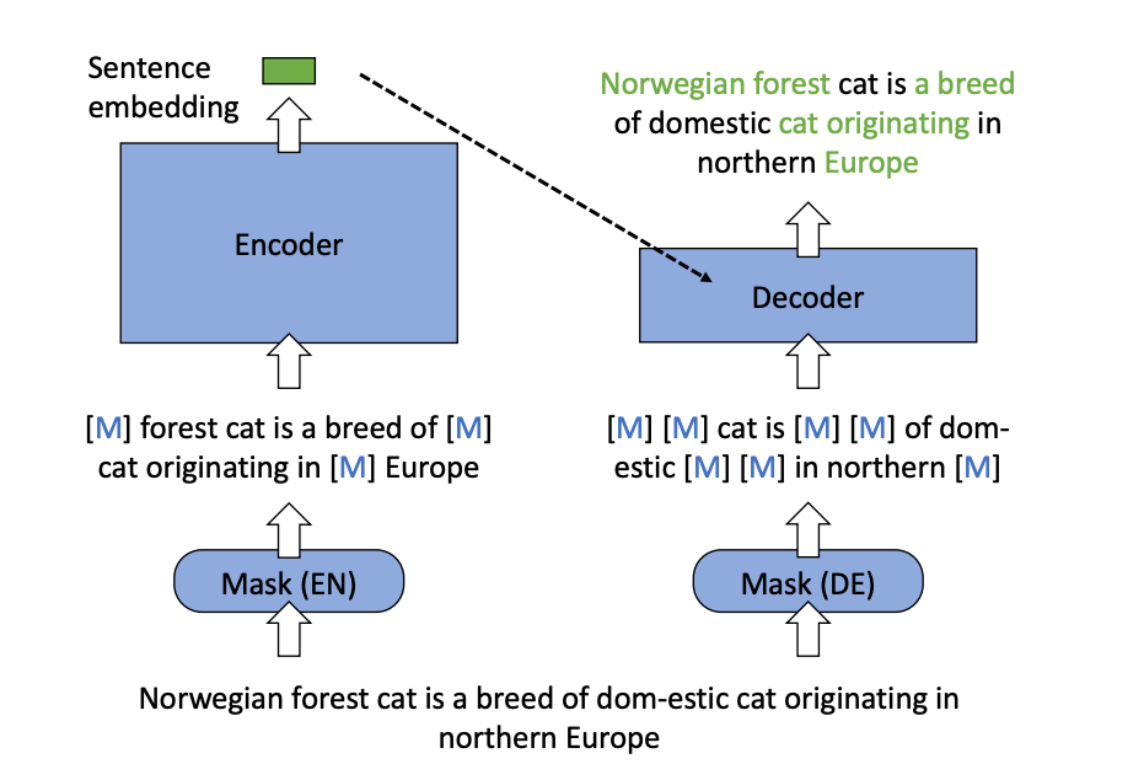
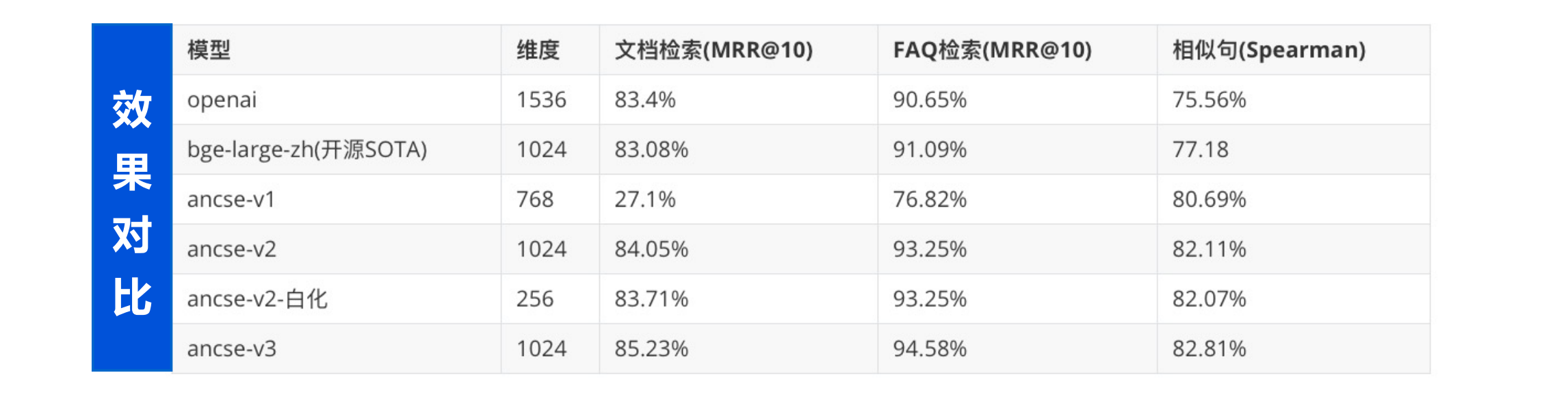
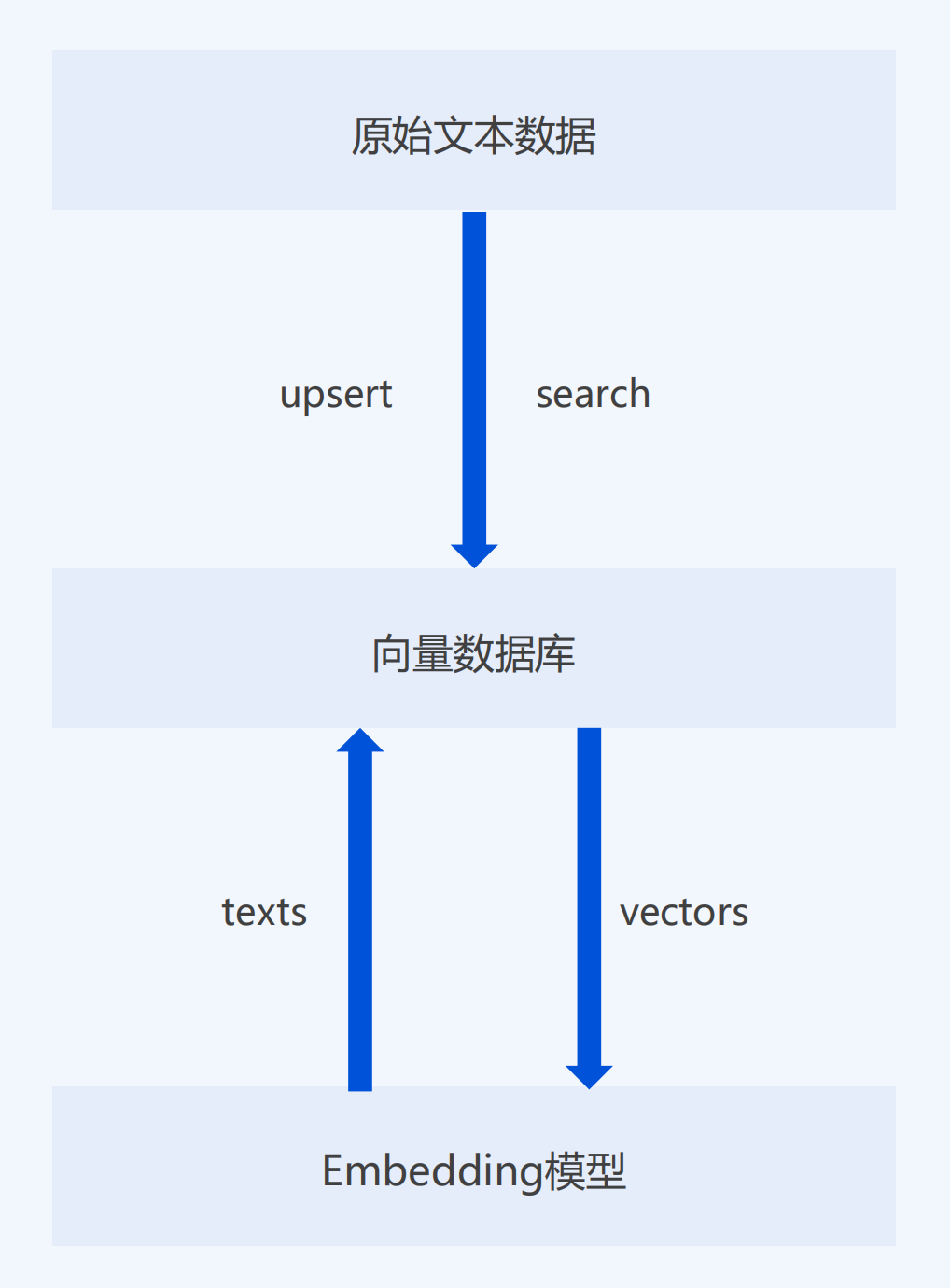
5 存储、检索向量数据
5.1 为啥需要一个专用的向量数据库
- 查询方式与传统数据库存在区别
- 简单易用,无需关心细节
- 为相似性检索设计,天生性能优势
5.2 腾讯云向量数据库的优势
“首家”:
- 通过信通院的标准化性能和规模测试
- 支持千亿级向量规模和最高500W QPS
自研:
- 内核源自集团自研OLAMA引擎
- 内部已有40+业务接入
性价比:
- 性能领先业内平均水平1.5倍
- 同时客户成本降低20%
6 VDB优势
流程简化
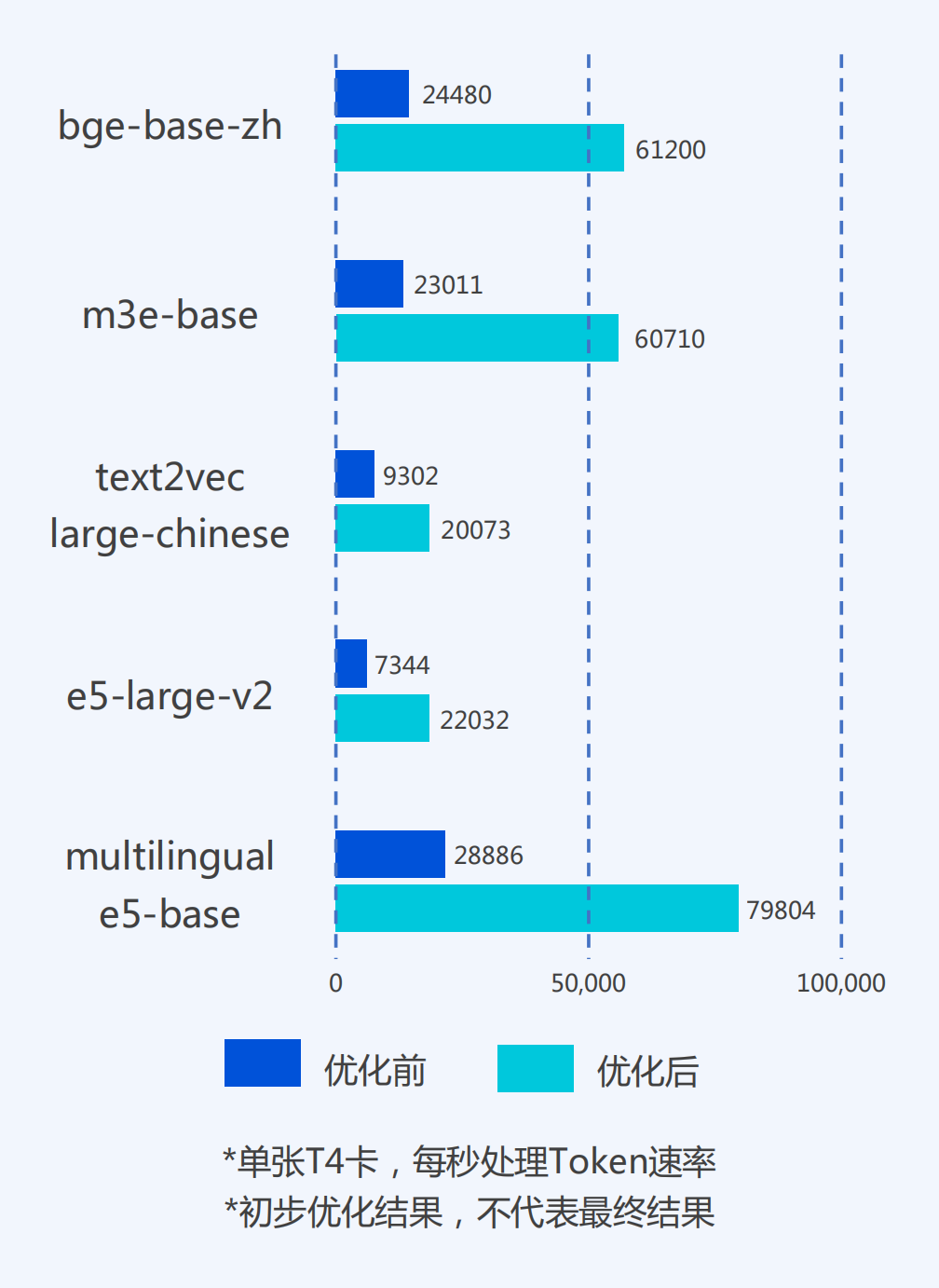
模型简化:
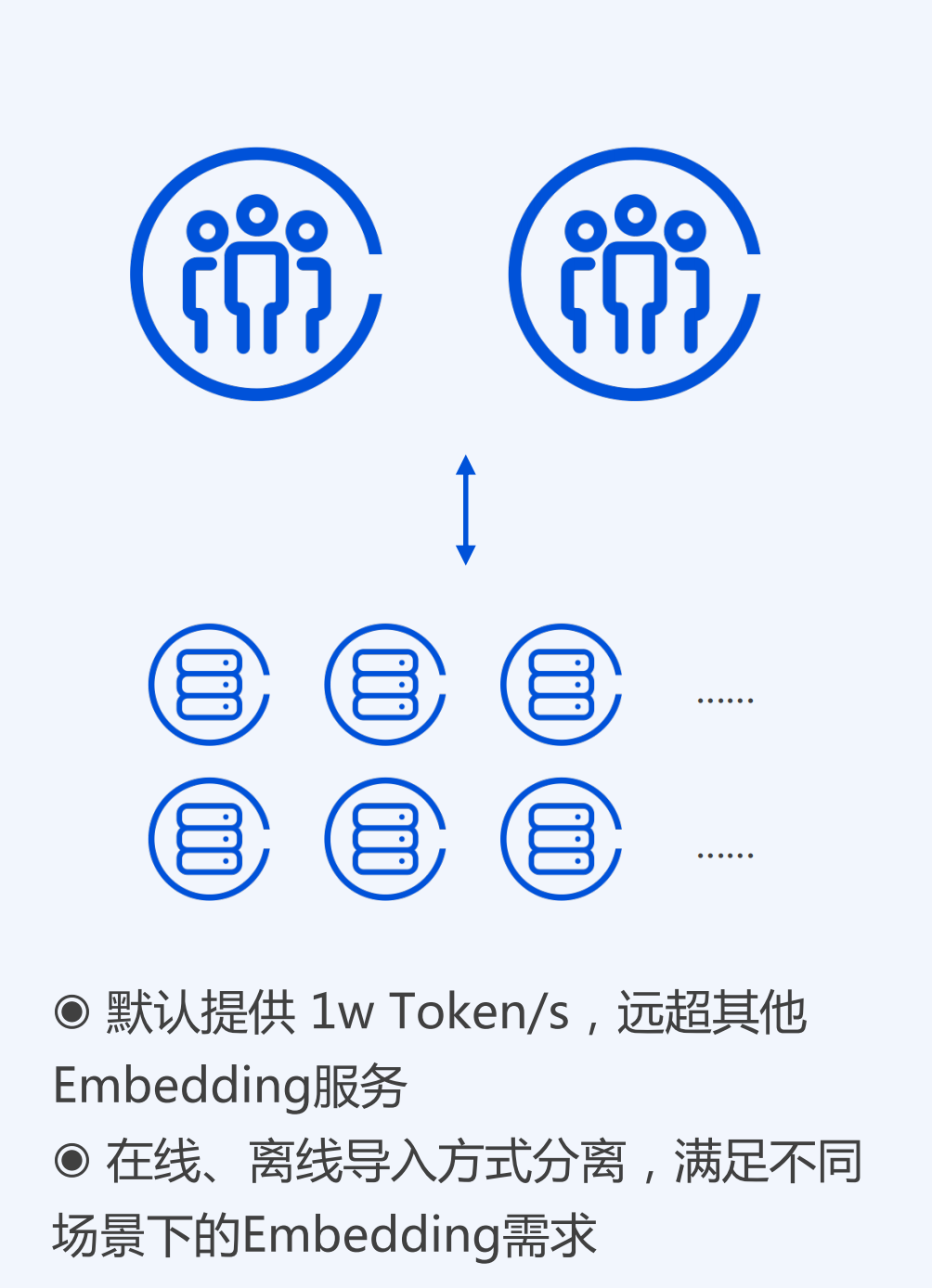
共享GPU集群:
7 腾讯云向量数据库:消除大模型幻觉,加速大模型在企业落地
7.1 端到端AI套件,AGI时代的知识库解决方案
提供一站式知识检索方案,实现业界内最高召回率、大幅降低开发门槛,帮助企业快速搭建RAG应用,解决大模型幻觉问题。
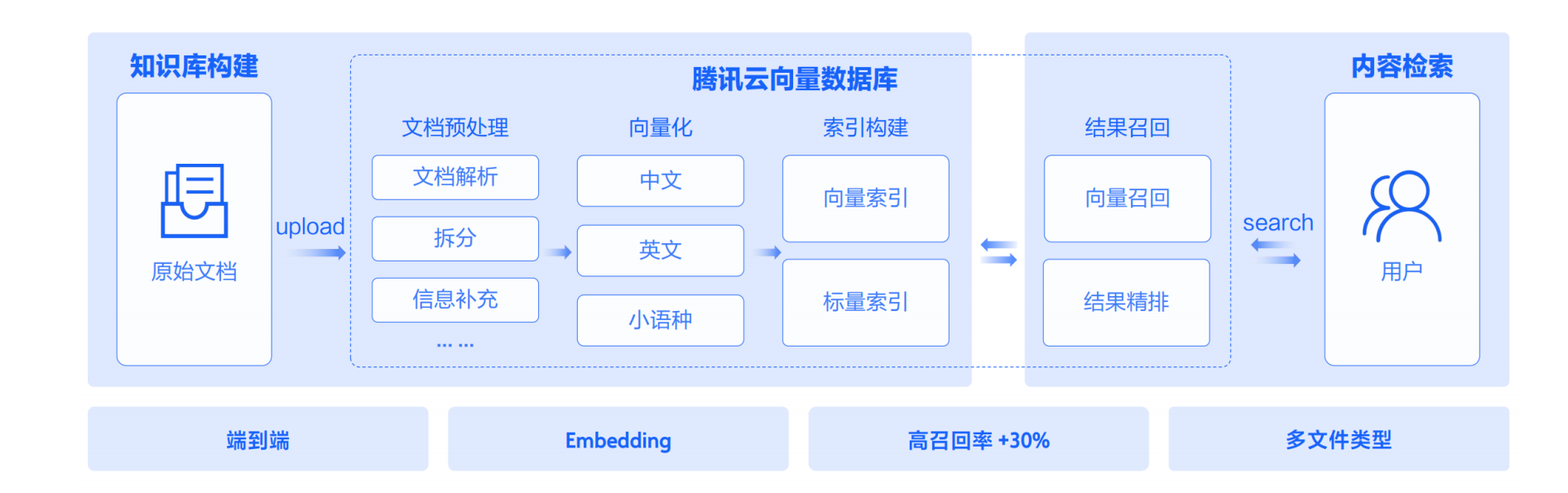
7.2 源自集团多年积累,产品能力行业领先
源自腾讯自研向量检索引擎OLAMA,集团内部40+业务线上使用,日均处理1600亿次检索请求。
- 『首家』通过中国信通院向量数据库标准测试
- 单索引支持最高千亿级超大数据规模
- 单实例最高可达500万 QPS
本文由博客一文多发平台 OpenWrite 发布!
文章来源:https://www.cnblogs.com/JavaEdge/p/18134415
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
