首页 > 基础资料 博客日记
Java IO
2023-11-11 00:23:16基础资料围观611次
IO(输入/输出)是每个程序都必须的部分。使用输入机制,程序可以读取到外部数据(例如来磁盘、光盘、网络等);使用输出机制,程序可以将数据输出到外部, 例如,把数据从内存写入到文件,把数据从内存输出到网络等等。
Java 的 IO 通过 java.io 包下的类和接口来支持,在java.io 包下主要包括输入、输出两种IO流,没中输入输出流又可分为字节流和字符流两大类。其中字节流以字节为单位来处理输入、输出操作,而字符流则以字符来处理输入、输出操作
File 类
使用File 类可以操作文件和目录。需要指出的是,File 类能新建、删除、重命名文件和目录,但File 类不能访问文件内容本身。如果需要访问文件内容本身,则需要通过IO来获取
File 类可以使用文件路径字符串来创建 File 实例,该文件路径字符串既可以是绝对路径,也可以是相对路径
// 通过绝对路径创建File 类
new File("C:\\Windows\\notepad.exe");
// 通过相对路径来创建File类
File f3 = new File(".\\sub\\javac");
注意Windows平台使用
\作为路径分隔符,在Java字符串中需要用\\表示一个\。Linux平台使用/作为路径分隔符:
创建 File 对象后,就可以通过File对象来操作文件和目录,下面列入一些比较常用的方法
1. 访问文件名相关方法
String getName()返回此 File 对象所表示的文件名或路径名String getPath()返回此 File 对象所对应的路径名File getAbsoluteFile()返回此对象所对应的绝对路径String getAbsoluteFile()返回此File 对象所对应的绝对路径名String getParent()返回此 File 对象所对应目录的父目录名boolean renameTo(File newName)重命名此File 对象所对应的文件或目录,如果重命名成功,则返回true,否则返回false
2. 文件检测方法
boolean exists()判断 File 对象所对应的文件或目录是否存在boolean canWrite()判断 File 对象所对应的文件和目录是否可写boolean canRead()判断 File 对象所对应的文件和目录是否刻度boolean isFile()判断 File 对象所对应的是否是文件boolean isDirectory()判断 File 对象所对应的是否是目录,而不是文件boolean isAbsolute()判断 File 对象所对应的文件或目录是否是绝对路径
3. 获取常规文件信息
long lastModified()返回文件的最后修改时间long length()返回文件内容的长度
4. 文件操作相关方法
boolean createNewFile()新建一个该 File 对象所指定的新文件,创建成功返回 true,否则返回falseboolean delete()删除 File 对象所对应的文件或路径static File createTempFile(String prefix,String suffix)在默认的临时文件目录中创建一个临时的空文件,使用给定前缀和给定后缀作为文件名static File createTempFile(String prefix,String suffix,File directory)在directory所指定的目录中创建一个临时的空文件,使用给定前缀和给定后缀作为文件名void deleteOnExit()注册一个删除钩子,指定当 Java 虚拟机退出时,删除File对象所对应的文件和目录
5. 目录操作相关方法
boolean mkdir()试图创建一个 File 对象所对应的目录,如果创建成功则返回trueString[] list()列出 File 对象的所有子文件名和路径名String[] list(FilenameFilter filter)FilenameFilter是一个函数式接口,该接口包含了一个accept(File,String name)方法,可以通过该参数列出符合条件的文件File[] listFiles()列出 File 对象所有的子文件和路径static File[] listRoots()列出系统所有的根路径
public class FileTest {
public static void main(String[] args) throws Exception {
// 以当前路径创建一个File 对象
File file = new File(".");
// 打印文件名
System.out.println(file.getName());
// 打印相对路径的上一级路径,由于相对路径只是一个点 所以输出null
System.out.println(file.getParent());
// 打印绝对路径
System.out.println(file.getAbsolutePath());
// 打印绝对路径的上一级路径
System.out.println(file.getAbsoluteFile().getParent());
// 创建一个临时文件
File temp = File.createTempFile("aaa", ".txt", file);
// 注册一个删除钩子,当JVM 退出时删除该文件
temp.deleteOnExit();
// 输出当前File 目录下所有的子文件和文件夹名
for (String filename : file.list()) {
System.out.print(filename + "\t");
}
// 换行
System.out.println();
// 输出系统所有的根目录
for (File root : File.listRoots()) {
System.out.println(root);
}
// 通过条件过滤出以.txt 结尾的文件
for (String filename : file.list(((dir, name) -> name.endsWith(".txt")))) {
System.out.print(filename + "\t");
}
}
}
输出
.
null
F:\yfd\java\JaveTest\.
F:\yfd\java\JaveTest
.idea aaa8648461841651352798.txt Annotation IODemo JDBCDemo out pom.xml
C:\
D:\
E:\
F:\
aaa8648461841651352798.txt
Java 的 IO 流
流的分类
按照不同的分类方式,可以将流分为不同类型
1. 输入流和输出流
- 输入流:只能从中读取数据,而不能向其写入数据,主要由 InputStream 和 Reader 作为基类
- 输出流:只能向其写入数据,而不能从中读取数据,主要由 OutputStream 和 Writer 作为基类
2. 字节流和字符流
字节流和字符流的用法几乎一样,区别在于操作的数据单元不同——字节流操作的数据单元是8位的字节,字符流操作的数据单元是16位的字符
3. 节点流和处理流
按照流的角色来分,可以分为节点流和处理流。
可以从/向一个特定的 IO 设备 读/写 数据的流,称为节点流。处理流则用于对一个已存在的流进行连接和封装,通过封装后的流来实现数据读/写功能
字节流和字符流
字节流和字符流的操作方式几乎一样,区别只是操作的数据单元不同
InputStream 和 Reader
InputStream 和 Reader 是所有输入流的抽象基类
InputStream 里包含如下三个方法
int read()从输入流中读取单个字节int read(byte[] b)从输入流中最多读取b.length个字节的数据,并将其存储在字节数组 b 中,返回实际读取的字节数int read(byte[] b,int off,int len)从输入流中最多读取len个字节的数据,并将其存储在 数组b中,放入数组b中时,是从off位置开始,返回实际读取的字节数
Reader 包含如下三个方法
int read()从输入流中读取单个字符int read(char[] cbuf)从输入流中最多读取cbuf.length个字符的数据,并将其存储在字符数组cbuf中,返回实际读取的字符数int read(char[] cbuf,int,int len)从输入流中最多读取len个字符的数据,并将其存储在字符数组cbuf中,防暑数组cbuf中时,是从off位置开始,返回实际读取的字符数
InputStream 实例
public static void main(String[] args) throws IOException {
try (
// 创建字节输入流,IO 流实现了AutoCloseable 接口,因此可通过try语句来关闭IO流
FileInputStream fis = new FileInputStream("test.txt");
) {
// 创建一个长度128的字节数组
byte[] data = new byte[128];
int len = 0;
// 向数组中装填数据
while ((len = fis.read(data)) > 0) {
// 将字节数组转换为字符串输入
System.out.print((new String(data, 0, len)));
}
}
}
Reader 实例
public class ReaderTest {
public static void main(String[] args) throws IOException {
try (
// 创建一个字符输入流
FileReader fr = new FileReader("test.txt");
) {
// 表示当前字符
int data = 0;
// 通过read() 方法循环读取流,如果到底则返回-1
while ((data = fr.read()) != -1) {
System.out.print((char) data);
}
}
}
}
除此之外, InputStream 和 Reader 还支持如下几个方法来移动记录指针
void mark(int readAheadLimit)在记录指针当前位置记录一个标记(mark)boolean markSupported()判断此输入流是否支持mark()操作void reset()将此流的记录指针重新定位到上一次标记(mark)的位置long skip(long n)记录指针向后移动 n 个字节/字符
OutputStream 和 Writer
OutputStream 和 Writer 是输出流的基类,两个流都提供了如下三个方法
void write(int c)将指定的 字节/字符 输出到输出流中,其中c既可以代表字节,也可以代表字符void write(byte[]/char[] buf)将 字节/字符 数组中的数据输出到指定输出流中void write(byte[]/char[] buf,int off,int len)将 字节/字符 数组从off位置开始,长度为len的 字节/字符 输出到输出流中
除此之外,Writer 还包含如下两个方法
void write(String str)将str字符串里包含的字符输出到指定输出流中void write(String str,int off,int len)将 str 字符串里从off位置开始,长度为len的字符输出到指定输出流中
OutputStream 示例
public class FileOutputStreamTest {
public static void main(String[] args) throws IOException {
File file = new File("test2.txt");
// 如果文件不存在则创建
if (!file.exists()) {
file.createNewFile();
}
try (
// 创建字节输入流
FileInputStream fis = new FileInputStream("test.txt");
// 创建字节输出流
FileOutputStream fos = new FileOutputStream("test2.txt");
) {
byte[] buf = new byte[2];
int readLen = 0;
while ((readLen = fis.read(buf)) > 0) {
// 将字节数组写入文件流
fos.write(buf, 0, readLen);
}
}
}
}
Writer 示例
public class FileWriterTest {
public static void main(String[] args) throws IOException {
try (
FileWriter fw = new FileWriter("test.txt");
) {
fw.write("锦瑟 \r\n");
fw.write("锦瑟无端五十弦, \r\n");
fw.write("一弦一柱思华年。 \r\n");
fw.write("庄生晓梦迷蝴蝶, \r\n");
fw.write("望帝春心托杜鹃。 \r\n");
}
}
}
处理流的用法
处理流隐藏了底层设备上的节点流的差异,并对外提供了更方便的输入/输出方法,让程序员只需关心高级流的操作
下面通过使用 PrintStream 处理流来包装 OutputStream,使用处理流后的输出流在输出时将更加方便
public class PrintStreamTest {
public static void main(String[] args) throws IOException {
try (
FileOutputStream fos = new FileOutputStream("test.txt");
PrintStream ps = new PrintStream(fos);
) {
ps.println("Java");
}
}
}
可以看到test.txt文件的内容已经变成了 Java
IO 流的体系结构
Java IO流体系中常用的流分类
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | PipedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 抽象基类 | FilerInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | PrintWriter | ||
| 推回输入流 | PushBackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
转换流
IO 流体系中还提供了两个用于实现将字节流转换成字符流的转换流,其中 InputStreamReader 将字节输入流转换成字符输入流,OutputStreamWriter 将字节输出流转换成字符输出流
public class StreamTest {
public static void main(String[] args) throws IOException {
try (
FileInputStream fis = new FileInputStream("test.txt");
// 将字节流转换成字符流
InputStreamReader isr = new InputStreamReader(fis);
) {
char[] data = new char[32];
int len = 0;
while ((len = isr.read(data)) > 0) {
System.out.println(String.valueOf(data,0,len));
}
}
}
}
推回输入流
PushbackInputStream 和 PushbackReader都带有一个推回缓冲区,当程序调用这两个退回输入流的 unread() 方法时,系统将会吧指定数组的内容退回到缓冲区里,而退回输入流每次调用 read() 方法时总是先从退回缓冲区读取
当程序创建一个退回流时,需要指定退回缓冲区的大小,默认的推回缓冲区的长度为1。如果程序中退回的长度超出了缓冲区的大小,将会引发异常
public class PushbackTest {
public static void main(String[] args) throws IOException {
try (
PushbackReader pr = new PushbackReader(new FileReader("test.txt"), 64);
) {
int c = 0;
while ((c = pr.read()) != -1) {
System.out.print((char) c);
}
// test.txt 最后一个字符是 a,将此字符推回输入流
pr.unread('a');
// 获取缓冲区的字符
System.out.println((char) pr.read());
}
}
}
输出
Javaa
读写其他进程数据
使用 Runtime 对象的 exec() 方法可以运行平台上的其他程序。Process 类提供了如下三个方法,用于让程序和其子进程进行通讯
InputStream getErrorStream()获取子进程的错误流InputStream getInputStream()获取子进程的输入流OutputStream getOutputStream()获取子进程的输出流
public class ProcessStreamTest {
public static void main(String[] args) throws IOException {
Process p = Runtime.getRuntime().exec("javac");
try (
// 将字节流转换为字符流,再交给缓冲流(处理流)包装
BufferedReader br = new BufferedReader(new InputStreamReader(p.getErrorStream(),"GBK"))
){
String buff = null;
// 循环输出 p 进程的错误输出
while ((buff = br.readLine()) != null){
System.out.println(buff);
}
}
}
}
输出
用法: javac <options> <source files>
其中, 可能的选项包括:
-g 生成所有调试信息
-g:none 不生成任何调试信息
-g:{lines,vars,source} 只生成某些调试信息
-nowarn 不生成任何警告
-verbose 输出有关编译器正在执行的操作的消息
-deprecation 输出使用已过时的 API 的源位置
-classpath <路径> 指定查找用户类文件和注释处理程序的位置
-cp <路径> 指定查找用户类文件和注释处理程序的位置
-sourcepath <路径> 指定查找输入源文件的位置
-bootclasspath <路径> 覆盖引导类文件的位置
-extdirs <目录> 覆盖所安装扩展的位置
-endorseddirs <目录> 覆盖签名的标准路径的位置
-proc:{none,only} 控制是否执行注释处理和/或编译。
-processor <class1>[,<class2>,<class3>...] 要运行的注释处理程序的名称; 绕过默认的搜索进程
-processorpath <路径> 指定查找注释处理程序的位置
-parameters 生成元数据以用于方法参数的反射
-d <目录> 指定放置生成的类文件的位置
-s <目录> 指定放置生成的源文件的位置
-h <目录> 指定放置生成的本机标头文件的位置
-implicit:{none,class} 指定是否为隐式引用文件生成类文件
-encoding <编码> 指定源文件使用的字符编码
-source <发行版> 提供与指定发行版的源兼容性
-target <发行版> 生成特定 VM 版本的类文件
-profile <配置文件> 请确保使用的 API 在指定的配置文件中可用
-version 版本信息
-help 输出标准选项的提要
-A关键字[=值] 传递给注释处理程序的选项
-X 输出非标准选项的提要
-J<标记> 直接将 <标记> 传递给运行时系统
-Werror 出现警告时终止编译
@<文件名> 从文件读取选项和文件名
Process finished with exit code 0
序列化
序列化机制允许将实现序列化的 Java 对象转换成字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以备以后重新恢复成原来的对象
实现序列化
如果需要将某个对象实现序列化,则必须实现 Serializabe 接口,该接口只是一个标记接口,只是表明该类的示例是可序列化的
如果这个可序列化类中包含引用类型的成员变量,那么该成员变量也需要实现 Serializabe 接口,否则该类型的成员变量是不可序列化的,将会引发 NotSerializableException 异常
使用 transient 关键字修饰成员变量,可以指定 Java 序列化时无视该实例变量
// 课程类
public class Course implements Serializable {
String name;
public Course(String name) {
this.name = name;
}
...省略getter,setter,toString 方法
}
// 学生类
public class Student implements Serializable {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
...省略getter,setter,toString 方法
}
// 成绩类
public class Grade implements Serializable {
// 分数
int grade;
// 备注,使用 transient 使此成员变量不参与序列化
transient String memo;
Student student;
Course course;
public Grade(int grade, String memo, Student student, Course course) {
this.grade = grade;
this.memo = memo;
this.student = student;
this.course = course;
}
...省略getter,setter,toString 方法
}
进行序列化对象
public class SerializeTest {
public static void main(String[] args) throws IOException {
Student stu = new Student("张三", 12);
Course course = new Course("语文");
Grade grade = new Grade(66, "备注", stu, course);
try (
// 1. 创建一个 ObjectOutputStream 输出流(处理流)
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.txt"));
) {
// 2. 调用 ObjectOutputStream 的 writeObject()方法将对象输出为可序列化对象
oos.writeObject(grade);
}
}
}
反序列化
我们可以通过反序列化从二进制流中恢复 Java 对象
public class DeserializeTest {
public static void main(String[] args) throws Exception {
try (
// 1. 创建一个 ObjectInputStream 处理流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt"))
) {
// 2. 调用 readObject() 读取流中的对象
Grade grade = (Grade) ois.readObject();
System.out.println(grade);
}
}
}
输出
Grade{grade=66, memo='null', student=Student{name='张三', age=12}, course=Course{name='语文'}}
NIO
从 JDK 1.4 开始 ,Java 提供了一系列改进的 输入/输出处理的新功能,这些功能被统称为新 IO(New IO,简称NIO),新增了许多用于处理IO的类,这些类都被放在java.nio 包以及子包下,并且对原 java.io 包中的很多类都以 NIO 为基础进行了改写
Channel(通道)和 Buffer(缓冲)是NIO 中的两个核心对象,Channel 是对传统的IO系统的模拟,在NIO 系统中所有的数据都需要通过通道传输
Buffer 可以被理解成一个容器,它的本质是一个数组,发送到 Channel 中的所有对象都必须首先放到 Buffer 中,而从 Channel 中读取的数据也必须先放到 Buffer 中
Buffer(缓冲区)
Buffer 的主要作用就是装入数据,然后输出数据,在Buffer 中有三个重要的概念:容量(capacity)、界限(limit)和位置(position)
容量(capacity)缓冲区的容量(capacity)表示该 Buffer 的最大数据容量。缓冲区的容量不可能为负值,且创建后不能改变界限(limit)第一个不应该被读出或者写入的缓冲区位置索引。就是说,位于 limit 后的数据既不可被读,也不可被写位置(position)用于指明下一个可以被读出的或者写入的缓冲区索引
除此之外,Buffer 还支持一个可选的标记(mark),Buffer 允许直接将 position 定位到该 mark 处。
这些值满足如下关系
0 <= mark <= position <= limit <= capacity
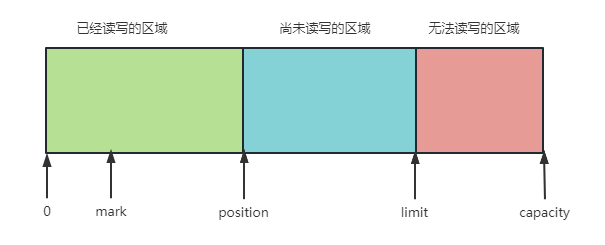
开始时,Buffer 的 position 为 0,limit 为 capacity,程序可通过put() 方法向 Buffer 中放入一些数据(或从 Channel中获取一些数据),每放入一些数据, Buffer 的position 相应的向后移动一些位置
当 Buffer 装入数据结束后,调用 Buffer 的 flip() 方法,该方法将 limit 设置为 position 所在的位置,并将 position 设为 0,也就是说,flip()是为取出数据做好准备。取完数据后,Buffer 可以调用clean() 方法,clean() 方法并不是清空数据,而是将 position 置为0,limit 置为 capacity,这样是为了再次向 Buffer 装入数据做好准备
Buffer 是一个抽象类,其最常用的子类是ByteBuffer,它可以在底层字节数组上进行 get/set 操作,除了 ByteBuffer 之外,对应于其他基本数据类型(boolean除外)都有相应的 Buffer 类:CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer
Buffer 还包含如下一些常用方法
int capacity()返回Buffer 的capacity 大小boolean hasRemaining()判断当前位置(position)和界限(limit)之间是否还有元素可供处理int limit()返回 Buffer的界限(limit)的位置Buffer limit(int newLt)重新设置界限(limit)的值,并返回一个具有新的limit 的缓冲区对象Buffer mark()设置 Buffer 的mark 位置int position()返回 Buffer 中的 position 值Buffer position(int newPs)设置 Buffer 的position,并返回 position 被修改后的Buffer 对象int remaining()返回当前位置和界限(limit)之间的元素个数Buffer reset将位置(position)转到 mark 所在的位置Buffer rewind()将位置(position)设置成0,取消设置的 mark
除了上述方法以外,Buffer 还有两个重要的方法:put() 和 get() 方法,用于向 Buffer 中放入数据和从Buffer 中取出数据。
当使用put() 和get() 来访问数据时,分为相对和绝对两种
相对(Relative)从Buffer 的当前 position 处开始读取或写入数据,然后将位置(position)的值按处理元素的个数相加绝对(Absolute)直接根据索引向 Buffer 中读取或写入数据,位置(position)的值不作改变
public class BufferTest {
public static void main(String[] args) {
// 创建Buffer capacity为 8
CharBuffer buf = CharBuffer.allocate(8); // 此时 position 为 0,limit为 8
buf.put('a'); // position 为 1,limit为 8
buf.put('b'); // position 为 2,limit为 8
buf.put('c'); // position 为 3,limit为 8
buf.flip(); // position 为 0,limit为 3
System.out.print(buf.get()); // position 为 1,limit为 3
System.out.print(buf.get()); // position 为 2,limit为 3
System.out.print(buf.get()); // position 为 3,limit为 3
// System.out.println(buf.get()); 超出界限(limit),抛出BufferUnderflowException异常
buf.clear(); // position 为 0,limit为 8
// 执行clean() 后,并没有清空其中的数据,只是将position定位到了0,limit为8
System.out.print(buf.get());
}
}
输出
abca
Channel
Channel 类似于传统的流对象,但与传统的流对象有两个主要区别
- Channel 可以直接将指定文件的部分或全部直接映射成 Buffer
- 程序不能直接访问 Channel 中的数据,包括读取,写入都不行,Channel 只能与 Buffer 进行交互
Channel 常用的实现类有 FileChannel,ServerSocketChannel,SocketChannel,DatagramChannel,SelectableChannel,Pipe.SinkChannel,Pipe.SourceChannel 等实现类
所有的 Channel 都是通过InputStream、OutputStream 的 getChannel() 方法来提供的
Channel 最常用的三个方法是map(),read(),write(), 这些方法用于向Buffer 写入或读取数据
其中 map() 方法用于将 Channel 对应的部分或全部数据映射成 ByteBuffer;map() 的方法签名为 MappedByteBuffer map(MapMode mode,long position, long size) 其中第一个参数执行映射的模式,有
MapMode.READ_ONLY只读MapMode.READ_WRITE读写MapMode.PRIVATE私有
后两个参数用于从 Buffer中读取哪些数据
public class FileChannelTest {
public static void main(String[] args) throws IOException {
File file = new File("test.txt");
try (
// 创建FileChannel对象,通过输入流读取文件
FileChannel inChannel = new FileInputStream(file).getChannel();
// 创建FileChannel对象,通过输出流写入文件
FileChannel outChannel = new FileOutputStream("a.txt").getChannel();
) {
// 将FileChannel 中的全部数据映射到 buffer中
MappedByteBuffer buffer = inChannel.map(FileChannel.MapMode.READ_ONLY,0,file.length());
// 直接将Buffer 中的数据全部输出
outChannel.write(buffer);
}
}
}
字符集
JDK 1.4 提供了 Charset 来处理字节序列和字符序列(字符串)之间的转换关系,该类包含了用于创建解码器和编码器的方法,还提供了获取 Charset 所支持字符集的方法,Charset 类是不可变的
Charset 有如下两个常用的静态方法
availableCharsets()获取当前JDK 所支持的所有字符集forName(String charsetName)通过别名创建对应的Charset对象
通过forName() 获得 Charset 对象之后,就可以通过该对象的newDecoder()、newEncoder() 这两个方法分别返回CharsetDecoder 和 CharsetEncoder 对象,代表该 Charset 的解码器和编码器
调用 CharsetDecoder 的 decode() 方法就可以将 ByteBuffer 转换成 CharBuffer,调用 CharsetEncoder 的 encode() 方法就可以将 CharBuffer 或 String 转换成 ByteBuffer
public class CharsetTest {
public static void main(String[] args) throws Exception {
Charset cn = Charset.forName("UTF-8");
CharsetEncoder cnEncoder = cn.newEncoder();
CharsetDecoder cnDecoder = cn.newDecoder();
CharBuffer cbuff = CharBuffer.allocate(8);
cbuff.put('孙');
cbuff.put('悟');
cbuff.put('空');
cbuff.flip();
// 将 CharBuffer中的字符转换成字节序列
ByteBuffer bbuff = cnEncoder.encode(cbuff);
// 循环访问每个字节
for (int i = 0; i < bbuff.limit(); i++) {
System.out.print(bbuff.get(i) + "\t");
}
// 将字节序列 解码成字符序列
System.out.println("\n" + cnDecoder.decode(bbuff));
}
}
文件锁
当多个程序同时访问并修改一个文件时,使用文件锁可以有效地阻止多个进程并发修改同一个文件
在 NIO 中,Java 提供了 FileLock 来支持文件锁定功能,在 FileChannel 中提供的 lock/tryLock() 方法可以获得文件锁 FileLock 对象,从而锁定文件;这两个方法的区别是 lock() 是阻塞式的,如果得不到文件锁会一直阻塞,tryLock() 是非阻塞式的,如果没获得文件锁,则返回 null
public class FileLockTest {
public static void main(String[] args) throws IOException,InterruptedException {
try (
FileChannel fc = new FileOutputStream("a.txt").getChannel();
) {
// 使用非阻塞式对文件进行加锁
FileLock lock = fc.tryLock();
// 程序暂停 10s
Thread.sleep(10000);
// 释放锁
lock.release();
}
}
}
NIO.2
Java 7 对原有的 NIO 进行了重大改造,改进主要包括如下两方面的内容
- 提供了全面的文件IO 和文件系统访问支持
- 基于异步 Channel 的 IO
Path 和 Paths
NIO.2 新增了一个 Path 接口,主要用于处理历经,通过 Paths 的静态工厂方法来获取 Path 方法
public class PathTest {
public static void main(String[] args) {
// 以当前路径来创建 Path 对象
Path path = Paths.get(".");
// 获取 path 里包含的路径数量
System.out.println(path.getNameCount());
// 获取 path 的根路径
System.out.println(path.getRoot());
// 获取 path 的绝对路径
System.out.println(path.toAbsolutePath());
}
}
Files
Files 是一个操作文件的工具类,提供了大量便捷的工具方法
public class FilesTest {
public static void main(String[] args) throws Exception{
// 复制文件
Files.copy(Paths.get("a.txt"),new FileOutputStream("b.txt"));
// 判断是否为隐藏文件
Files.isHidden(Paths.get("b.txt"));
// 一次性读取文件的所有行
List<String> lines = Files.readAllLines(Paths.get("a.txt"));
// 获取文件的大小
Files.size(Paths.get("a.txt"));
// 将多个字符串内容写入文件
Files.write(Paths.get("b.txt"),lines, Charset.forName("UTF-8"));
// 列出当前目录下的所有文件和子目录 (Java 8)
Files.list(Paths.get(".")).forEach(path -> {
System.out.println(path);
});
}
}
使用 FileVisitor 遍历 文件和目录
Files 类提供了如下两个方法来遍历文件和子目录
walkFileTree(Path start,FileVisitor<? super Path> visitor)遍历 start 路径下的所有文件和子目录walkFileTree(Path start,Set<? FileVisitOption> options,int maxDepth,FileVisitor<? super Path> visitor)上一个方法的功能类似。该方法最多遍历maxDepth深度的文件
FileVisitor 代表一个文件访问,walkFileTree() 方法会自动遍历 start 路径下的所有文件和子目录,遍历文件和子目录都会 触发 FileVisitor 中相应的方法
FileVisitor 中定义了如下4个方法
FileVisitResult postVisitDirectory(T dir,IOException exc)访问子目录之后触发该方法FileVisitResult preVisitDirectory(T dir,BasicFileAttributes attrs)访问子目录之前触发该方法FileVisitResult VisitFile(T file,BasicFileAttributes attrs)访问file 文件时触发该方法FileVisitResult VisitFileFailed(T file,IOException exc)访问file 文件失败时触发该方法
FileVisitResult 是一个枚举类,表示访问之后的后续行为
CONTINUE继续访问SKIP_SIBLINGS继续访问,但不访问该文件或目录的兄弟文件或目录SKIP_SUBTREE继续访问,但不访问该文件或目录的子目录树TERMINATE中止访问
public class FileVisitorTest {
public static void main(String[] args) throws IOException {
Files.walkFileTree(Paths.get("."),new SimpleFileVisitor<Path>(){
// 访问文件时触发该方法
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("正在访问"+ file + "文件");
if(file.endsWith("abc")){
System.out.println("已找到目标文件");
return FileVisitResult.TERMINATE; // 中止访问
}
return FileVisitResult.CONTINUE; // 继续访问
}
});
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
上一篇:12、SpringMVC之拦截器
下一篇:来世再不选Java!
相关文章
最新发布
点击排行
本站推荐
