首页 > 基础资料 博客日记
带你走进Java8新特性Stream流的小世界
2023-07-24 10:00:13基础资料围观714次
目录
🐼个人主页:爪哇斗罗
🐼博主介绍:一名打工人
🐼签名:圣人之道,为而不争。
🐼一起交流,一起进步,一起互动。

一. 什么是流(Stream)
1.1 流的定义
将原来的数组或者集合(数据源)通过一系列流水线的中间操作方式产生一个新的流,相当于一个数据渠道。

1.2 流的特点
流的特点主要有两条记住即可:
1. 集合是数据,流是计算;
2. 流不改变数据源,也不做任何存储。
1.3 操作流
操作流只需这三步:创建流,中间操作流,终止操作 。也就是对应上图中的解释。
具体来说就是一个数据源获取一个流,然后通过一个中间操作,对数据进行处理后,最后一个终止操作产生一个结果。
1.4 创建流
创建流主要三种方式:了解即可,具体如何操作在后面会说到。
@Test
public void t3()
{
// 1.创建流 通过集合提供的stream()创建
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream(); ·
// 2.通过Arrays中的静态方法stream()创建流
Integer[] integers = new Integer[10];
Stream<Integer> stream1 = Arrays.stream(integers);
// 3.Stream.of()创建
Stream<Integer> stream2 = Stream.of(1, 2, 4);
}二. 流的中间操作
开始前,请准备一个集合,集合可以自己随便创建。
// 案例数据 姓名 年龄 薪水
List<Employee> employees = Arrays.asList(
new Employee("张三", 20, 9999.99),
new Employee("李四", 21, 5555.55),
new Employee("王五", 45, 4568.88),
new Employee("赵六", 56, 6666.66),
new Employee("田七",34 , 8888.88),
new Employee("周一", 19, 9999.99),
new Employee("吴用", 22, 6666.89),
new Employee("孙十",22 , 7878.56));2.1 流的筛选与切片
2.1.1 filter
通过接收一个lambda表达式,根据定义中间过滤条件过滤流中的一些数据。
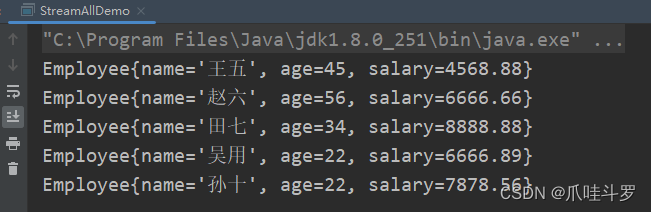
比如,过滤年龄大于21的员工。
public void filter()
{
List<Employee> employees = emp();
// 调用stream()方法创建一个流
// 通过中间操作filter去过滤年龄大于21的员工
// 并收集一个新的集合后打印。
List<Employee> collect = employees.stream().filter(e -> e.age > 21).collect(Collectors.toList());
collect.forEach(System.out::println);
}
练习(自己测试)
1. 过滤年龄大于21的并且薪水大于7000的员工。
2. 过滤年龄大于21的或者薪水大于7000的员工。
2.1.2 limit
流的截断操作,使最后获取的数据不超过所指定数量。
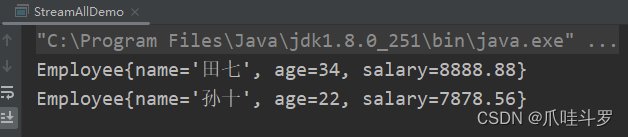
比如,先过滤年龄大于21的并且薪水大于7000的员工,只取前两条数据。
public void limit(){
List<Employee> employees = emp();
// 调用stream()方法创建一个流
// 先过滤年龄大于21的并且薪水大于7000的员工,只取前两条数据。
// 并收集一个新的集合后打印。
List<Employee> collect = employees.stream()
.filter(e -> e.age > 21 && e.salary>7000)
.limit(2)
.collect(Collectors.toList());
collect.forEach(System.out::println);
}
只要取到对应数量的数据,就会发生短路,之后的数据便不会获取。
练习(自己测试)
1. 过滤年龄大于21的并且薪水大于7000的员工只获取前0条数据。
2. 过滤年龄大于21的并且薪水大于7000的员工只获取前10条数据。
2.1.3 skip
跳过前面n个数据,获取后面所有的数据,与limit刚好互补。
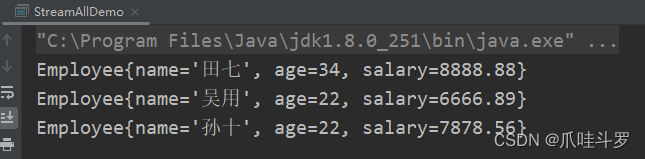
比如,过滤年龄大于21的员工。并跳过前2个数据获取后面的所有数据。
public void skip(){
List<Employee> employees = emp();
// 调用stream()方法创建一个流
// 过滤年龄大于21的员工。并跳过前2个数据获取后面的所有数据。
// 并收集一个新的集合后打印。
List<Employee> collect = employees.stream()
.filter(e -> e.age > 21)
.skip(2)
.collect(Collectors.toList());
collect.forEach(System.out::println);
}
练习(自己测试)
1. 过滤年龄大于21的并且薪水大于7000的员工跳过前0条数据。
2. 过滤年龄大于21的并且薪水大于7000的员工跳过前10条数据。
2.1.4 distinct
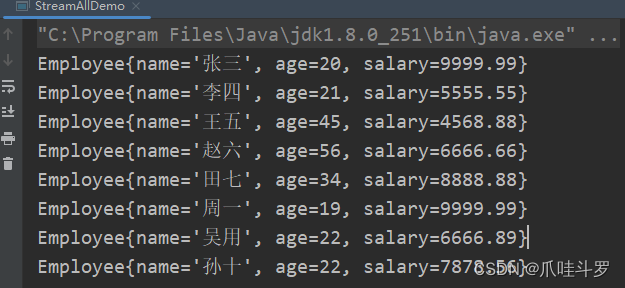
对重复的对象元素进行去重,它的原理是根据重写对象的hashCode方法与equals方法进行去重。
将之前的数据添加几个重复的数据:
// 案例数据
List<Employee> employees = Arrays.asList(
new Employee("张三", 20, 9999.99),
new Employee("李四", 21, 5555.55),
new Employee("王五", 45, 4568.88),
new Employee("赵六", 56, 6666.66),
new Employee("田七",34 , 8888.88),
new Employee("周一", 19, 9999.99),
new Employee("吴用", 22, 6666.89),
new Employee("吴用", 22, 6666.89),
new Employee("吴用", 22, 6666.89),
new Employee("吴用", 22, 6666.89),
new Employee("孙十",22 , 7878.56));
然后重写员工的hashCode方法与equals方法。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Double.compare(employee.salary, salary) == 0 && Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, salary);
}使用distinct方法进行元素去重:
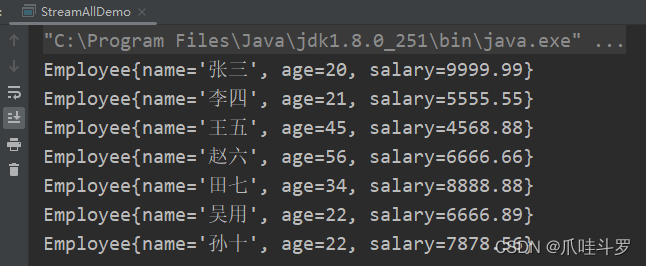
public void distinct(){
List<Employee> employees = emp();
// 调用stream()方法创建一个流
// 过滤重复的元素。
// 并收集一个新的集合后打印。
List<Employee> collect = employees.stream()
.distinct()
.collect(Collectors.toList());
collect.forEach(System.out::println);
}
这是进行对整个对象进行去重的,若对某个字段进行去重使用filter方法加上自定义方法。
// 自定义方法
<T> Predicate<T> distinctBykey(Function<? super T,?> key){
Map<Object,Boolean> booleanMap = new ConcurrentHashMap<>();
return t-> booleanMap.putIfAbsent(key.apply(t),Boolean.TRUE)==null;
}public void distinct(){
List<Employee> employees = emp();
// 调用stream()方法创建一个流
// 过滤重复的薪水。
// 并收集一个新的集合后打印。
List<Employee> collect = employees.stream()
.filter(distinctBykey(s->s.getSalary()))
.collect(Collectors.toList());
collect.forEach(System.out::println);
}
2.2 流的映射
2.2.1 map
接收一个lambda表达式,将对象中的元素转换成其它形式或者提取对象中的元素。
然后,接收一个函数作为参数,该函数会应用到每一个对象元素上,并映射成为新的对象元素。
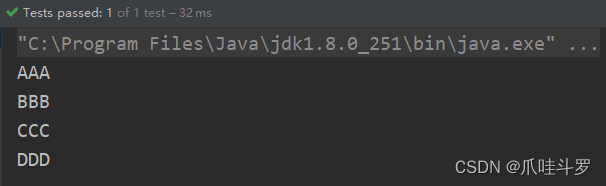
比如,将对象中的所有英文元素转为大写。
@Test
public void test01(){
// 构建一个集合
List<String> strings = Arrays.asList("aaa","bbb","ccc","ddd");
// 将集合中的元素进行大写
List<String> collects = strings.stream().map(str -> str.toUpperCase()).collect(Collectors.toList());
// 输出
collects.forEach(System.out::println);
}
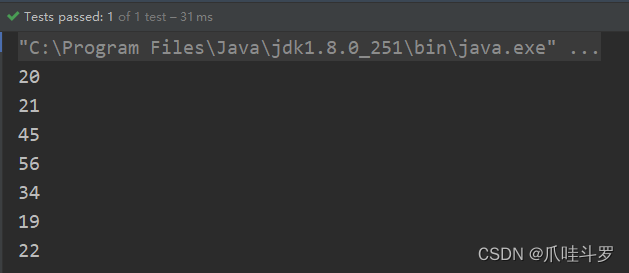
比如,将员工对象中的年龄抽取出来并去重。
@Test
public void test02(){
List<Employee> employees = emp();
// 将年龄提取出来,并去重。
employees.stream().map(Employee::getAge)
.distinct()
.forEach(System.out::println);
}
2.2.2 flatMap
流的扁平化处理,接收一个函数作为参数,将流中的每一个值都换成另一个流,然后将所有的流连接成一个流。
首先我们看看之前的map操作:
@Test
public void t4()
{
// 构建集合
List<String> list = Arrays.asList("hello","world");
// map 将一个个流加入流
List<String[]> collect = list.stream().map(s -> s.split("")).collect(Collectors.toList());
collect.forEach(System.out::println);
}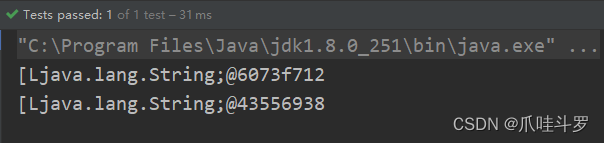
看代码可以看出它返回的是一个集合,集合里面是一个数组,map操作是针对于单层式的操作,也就是说只能对外层进行处理。
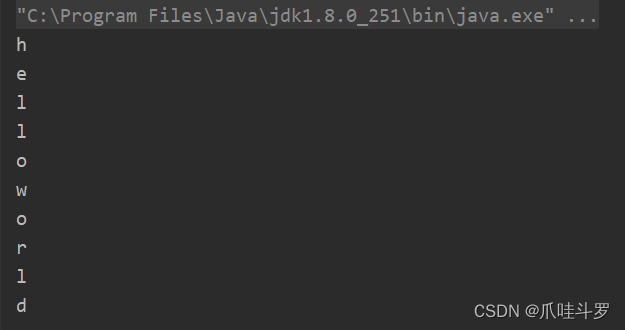
所以,它输出的就是两个数组对象是这种格式的【[h,e,l,l,o],[w,o,r,l,d]】。
[h,e,l,l,o]作为一个流,[w,o,r,l,d]作为一个流,然后将两者按照流的方式逐个放入一个新流里。
如果要输出成这种格式的[h,e,l,l,o,w,o,r,l,d]就需要使用flatMap进行双层式的处理。
这种方式就是先将各个流拆成最小元素,然后将元素分别放入一个流中。
@Test
public void t4()
{
List<String> list = Arrays.asList("hello","world");
// 使用flapMap将流中的每一个值都换成另一个流,然后将所有的流连接成一个流。
Stream<String> stringStream = list.stream().map(s -> s.split("")).flatMap(Arrays::stream);
stringStream.forEach(System.out::println);
}
2.3 流的排序
2.3.1 sort
流的排序分为以下两种:
自然排序: 默认的字典方式的排序
@Test
public void t5()
{
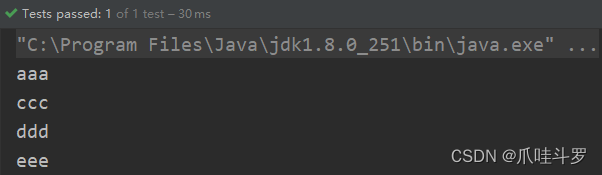
List<String> list = Arrays.asList("ccc","aaa","eee","ddd");
// 默认字典排序
list.stream().sorted().forEach(System.out::println);
}
自定义排序: 根据自己定义的规则排序
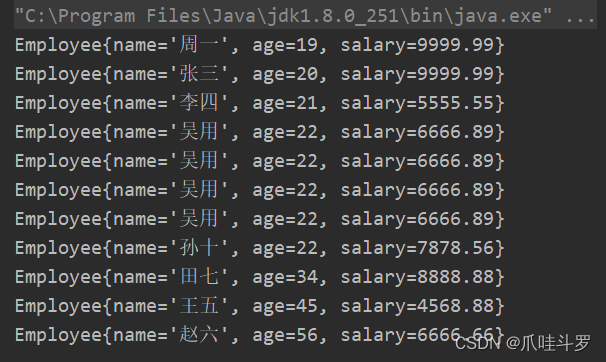
比如,若年龄一样,按照薪水排序,否则按照年龄排序。
@Test
public void t5()
{
List<Employee> employees = emp();
// 自定义排序
employees.stream().sorted((e1,e2)->{
// 若年龄一样,按照薪水排序
if (e1.getAge()==e2.getAge()){
return (int) (e1.getSalary()-(e2.getSalary()));
// 否则按照年龄排序
}else{
return e1.getAge()-e2.getAge();
}
}).forEach(System.out::println);
}
三. 流的终止操作
3.1 流的查找与匹配
3.1.1 allMatch
用于检查是否匹配所有的元素,全部匹配成功返回true。
现在将员工信息修改如下:
// 案例数据
List<Employee> employees = Arrays.asList(
new Employee("张三", 22, 9999.99),
new Employee("李四", 22, 5555.55),
new Employee("王五", 22, 4568.88),
new Employee("赵六", 22, 6666.66),
new Employee("田七",22, 8888.88),
new Employee("周一", 22, 9999.99),
new Employee("吴用", 22, 6666.89),
new Employee("吴用", 22, 6666.89),
new Employee("吴用", 22, 6666.89),
new Employee("吴用", 22, 6666.89),
new Employee("孙十",22, 7878.56));
return employees;匹配年龄是否全部为22。
@Test
public void t7()
{
List<Employee> employees = emp();
// 匹配年龄是否全部为22
boolean allMatch = employees.stream().allMatch(e -> e.age == 22);
// 全部匹配到返回true
System.out.println(allMatch);
}
3.1.2 anyMatch
用于检查元素是否匹配到流中的任意元素,匹配到一个就成功返回true。
查找员工薪水是否有超过9000的。
@Test
public void t8()
{
List<Employee> employees = emp();
// 查找员工薪水是否有超过9000的
boolean anyMatch = employees.stream().anyMatch(e -> e.salary > 9000);
// 部分匹配到则返回true
System.out.println(anyMatch);
}
3.1.3 noneMatch
全部没有匹配到元素返回true。
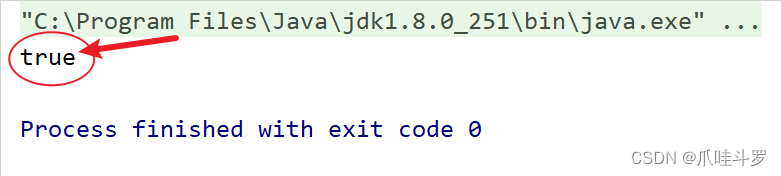
查找员工薪水是否有超过10000的。
@Test
public void t10()
{
List<Employee> employees = emp();
// 查找员工薪水是否有超过10000的
boolean noneMatch = employees.stream().noneMatch(e -> e.salary > 10000);
// 没有匹配到则返回true
System.out.println(noneMatch);
}
3.1.3 findFirst与findAny
findFirst用于查找流中的第一个元素,对于元素处理的流是串行流。
findAny用于查找流中的任意一个元素,对于元素处理的流是并行流。
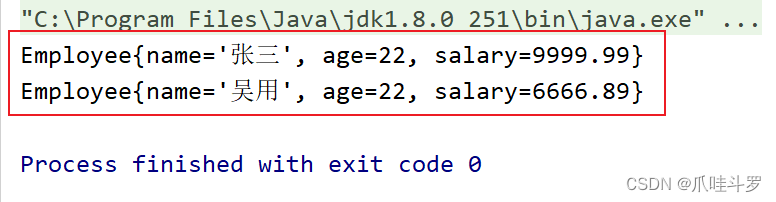
例如:查找员工薪水大于6000的并取第一个元素与查找员工薪水大于6000的并取任意一个元素
@Test
public void t11()
{
List<Employee> employees = emp();
// 查找员工薪水大于6000的并取第一个元素
System.out.println(employees.stream().filter(e->e.getSalary()>6000).findFirst().get());
// 查找员工薪水大于6000的并取任意一个元素
System.out.println(employees.parallelStream().filter(e->e.getSalary()>6000).findAny().get());
}
3.1.4 count
统计流中的元素总个数。
例如,统计所有员工。
@Test
public void t12()
{
List<Employee> employees = emp();
// 统计流中的元素总个数
long count = employees.stream().count();
System.out.println(count);
}
3.1.5 max与min
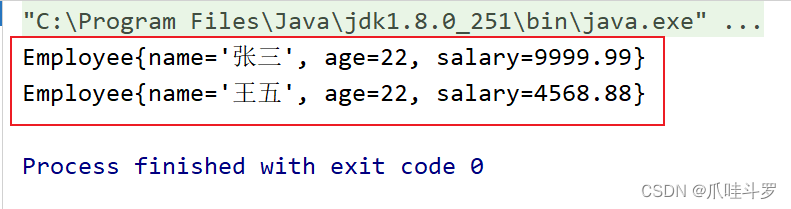
max与min分别是获取流中的最大值与最小值。
@Test
public void t14()
{
List<Employee> employees = emp();
// 统计员工薪水最高的
Optional<Employee> max = employees.stream().max(Comparator.comparingDouble(Employee::getSalary));
System.out.println(max.get());
// 统计员工薪水最低的
Optional<Employee> min = employees.stream().min(Comparator.comparingDouble(Employee::getSalary));
System.out.println(min.get());
}
3.2 归约与收集
3.2.1 归约(reduce)
可以将流中的元素反复结合起来,结成一个值。
例如,构建一个集合,求出它们的和。
@Test
public void t15()
{
// 构建一个集合
List<Integer> integers = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
// 进行求和
Integer reduce = integers.stream().reduce(0, (x, y) -> x + y);
System.out.println(reduce);
}
3.2.2 收集(collect)
集合收集
将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法。
可以将最终的结果收集成一个List集合,Set集合等,也可以将得到的结果进行计算。
看下面这个例子:利用Collectors.toSet()进行去重。
@Test
public void test01(){
// 构建一个集合
List<String> strings = Arrays.asList("aaa","bbb","ccc","ddd","ddd");
// 将集合中的元素进行大写
Set<String> collects = strings.stream().map(str -> str.toUpperCase()).collect(Collectors.toSet());
// 输出
collects.forEach(System.out::println);
}
分组操作
接下来着重介绍一下 ,使用Collectors.groupingBy进行分组操作。
先准备一组数据:使用其分组操作将年龄进行分组。
List<Employee> emp() {
// 案例数据
List<Employee> employees = Arrays.asList(
new Employee("张三", 22, 9999.99),
new Employee("李四", 22, 5555.55),
new Employee("王五", 23, 4568.88),
new Employee("赵六", 23, 6666.66),
new Employee("田七",24, 8888.88),
new Employee("周一", 24, 9999.99),
new Employee("吴用", 25, 6666.89),
new Employee("吴用1", 25, 6666.89),
new Employee("吴用2", 21, 6666.89),
new Employee("吴用3", 21, 6666.89),
new Employee("孙十",21, 7878.56));
return employees;
}@Test
public void t17()
{
List<Employee> employees = emp();
// 返回一个map集合
Map<Integer, List<Employee>> collect = employees.stream().collect(Collectors.groupingBy(Employee::getAge));
System.out.println(collect);
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
